




整个流程如如下图所示,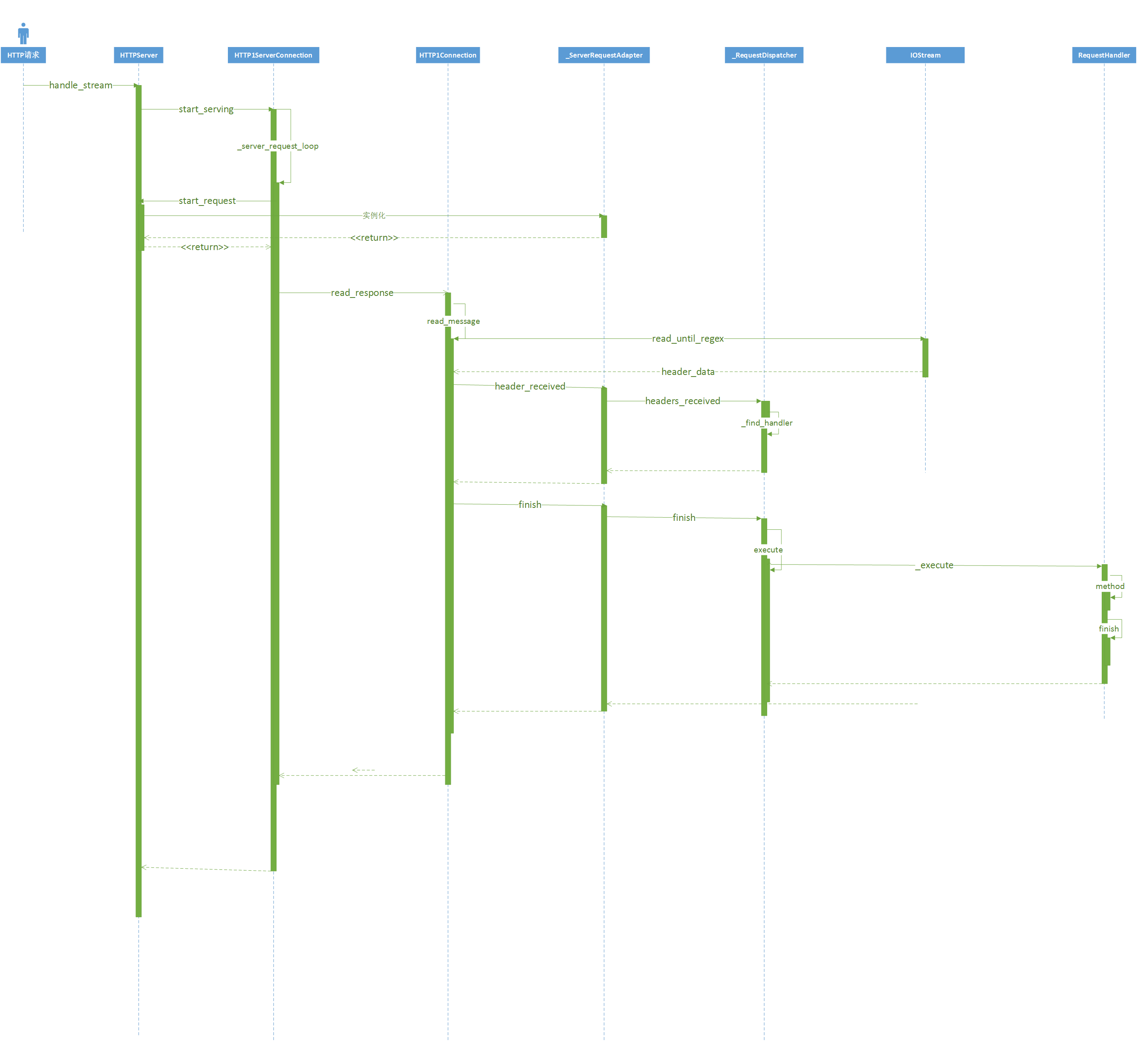
上图涉及到了多个类,下面就讲解主要的代码步骤
首先HTTPServe继承TcpServer,复写了handle_stream方法,当底层每次有新的请求连接时,就会调用。
|
1
2
3
4
5
6
7
|
def
handle_stream(
self
, stream, address):
context
=
_HTTPRequestContext(stream, address,
self
.protocol)
conn
=
HTTP1ServerConnection(
stream,
self
.conn_params, context)
self
._connections.add(conn)
conn.start_serving(
self
)
|
_HTTPRequestContext类是用来解析ip地址,协议的。
然后实例化HTTPServerConnection类,这个类主要负责对连接的处理。最后调用conn.start_serving方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
def
start_serving(
self
, delegate):
"""Starts serving requests on this connection.
:arg delegate: a `.HTTPServerConnectionDelegate`
"""
assert
isinstance
(delegate, httputil.HTTPServerConnectionDelegate)
self
._serving_future
=
self
._server_request_loop(delegate)
# Register the future on the IOLoop so its errors get logged.
self
.stream.io_loop.add_future(
self
._serving_future,
lambda
f: f.result())
@gen.coroutine
def
_server_request_loop(
self
, delegate):
try
:
while
True
:
conn
=
HTTP1Connection(
self
.stream,
False
,
self
.params,
self
.context)
request_delegate
=
delegate.start_request(
self
, conn)
try
:
ret
=
yield
conn.read_response(request_delegate)
except
(iostream.StreamClosedError,
iostream.UnsatisfiableReadError):
return
except
_QuietException:
# This exception was already logged.
conn.close()
return
except
Exception:
gen_log.error(
"Uncaught exception"
, exc_info
=
True
)
conn.close()
return
if
not
ret:
return
yield
gen.moment
finally
:
delegate.on_close(
self
)
|
可以看到start_serving方法,主要是调用了_server_request_loop方法。_server_request_loop方法被gen.coroutine装饰,说明这个函数是异步调用。
主要delegate这个函数参数,它指向HTTPServer。这里需要说明下一,HTTPServer和Application是怎么联系的。
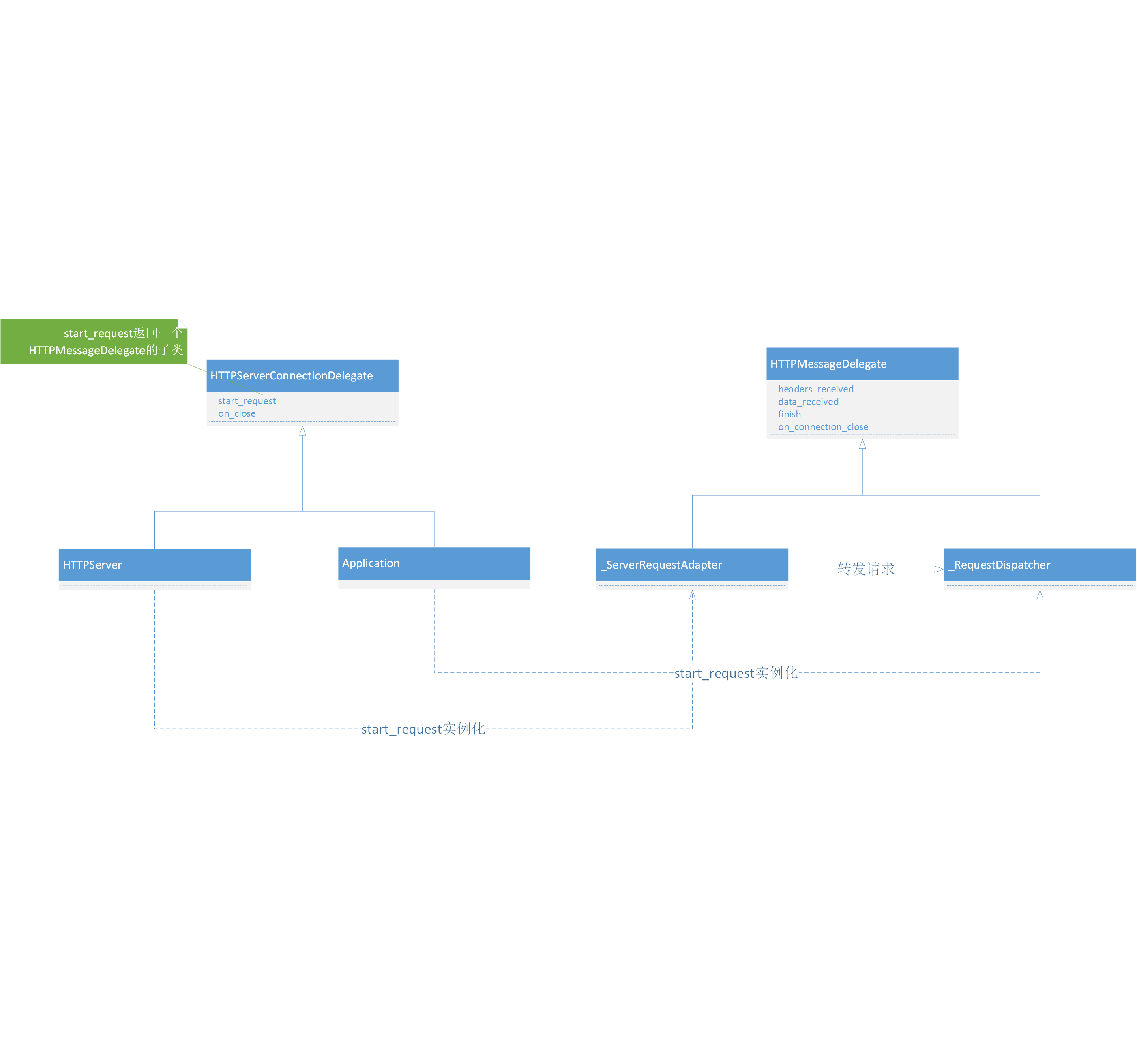
由上图可以看出_ServerRequestAdapter类是_RequestDispatcher类的代理。HTTPServer和Application是通过这两个类关联一起的。
继续回到_server_request_loop函数里。它首先实例化了HTTP1Connection类,然后等带conn.read_response方法,返回结果。
继续看HTTP1Connection的read_response方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def
read_response(
self
, delegate):
"""Read a single HTTP response.
Typical client-mode usage is to write a request using `write_headers`,
`write`, and `finish`, and then call ``read_response``.
:arg delegate: a `.HTTPMessageDelegate`
Returns a `.Future` that resolves to None after the full response has
been read.
"""
if
self
.params.decompress:
delegate
=
_GzipMessageDelegate(delegate,
self
.params.chunk_size)
return
self
._read_message(delegate)
|
这里_GzipMessageDelegate是一个装饰类(装饰者模式),负责内容的gzip解码。
_read_message代码比较多,注意分为几个部分,一是读取http的首部,然后调用delegate.header_received。
然后读取http的body,最后调用delegate.finish。下面简化下代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#试图从stream读取到连续两个行结束符。因为连续两个行结束符意味着HEADER部分已经完成
header_future
=
self
.stream.read_until_regex(
b
"\r?\n\r?\n"
,
max_bytes
=
self
.params.max_header_size)
#解析首部
start_line, headers
=
self
._parse_headers(header_data)
#调用delegate.header_received
delegate.headers_received(start_line, headers)
#试图读取body
body_future
=
self
._read_body(
start_line.code
if
self
.is_client
else
0
, headers, delegate)
#调用delegate.finish
delegate.finish()
|
接下来看看_RequestDispatcher的实现,他负责主要的逻辑。
|
1
2
3
4
5
6
7
8
9
10
11
|
def
headers_received(
self
, start_line, headers):
self
.set_request(httputil.HTTPServerRequest(
connection
=
self
.connection, start_line
=
start_line, headers
=
headers))
if
self
.stream_request_body:
self
.request.body
=
Future()
return
self
.execute()
def
set_request(
self
, request):
self
.request
=
request
self
._find_handler()
self
.stream_request_body
=
_has_stream_request_body(
self
.handler_class)
|
header_received会实例化HTTPServerRequest,这个对象就是RequestHandler的request属性。
_find_handler就是调用Application的_get_host_handlers方法,找到相应的RequestHandler的子类。
|
1
2
3
4
5
6
7
|
def
finish(
self
):
if
self
.stream_request_body:
self
.request.body.set_result(
None
)
else
:
self
.request.body
=
b''.join(
self
.chunks)
self
.request._parse_body()
self
.execute()
|
这里self.stream_request_body,只有在相应的RequestHandler被stream_request_body装饰,才会返回True。
所以这里会执行self.excute()方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
def
execute(
self
):
# If template cache is disabled (usually in the debug mode),
# re-compile templates and reload static files on every
# request so you don't need to restart to see changes
if
not
self
.application.settings.get(
"compiled_template_cache"
,
True
):
with RequestHandler._template_loader_lock:
for
loader
in
RequestHandler._template_loaders.values():
loader.reset()
if
not
self
.application.settings.get(
'static_hash_cache'
,
True
):
StaticFileHandler.reset()
self
.handler
=
self
.handler_class(
self
.application,
self
.request,
*
*
self
.handler_kwargs)
transforms
=
[t(
self
.request)
for
t
in
self
.application.transforms]
if
self
.stream_request_body:
self
.handler._prepared_future
=
Future()
# Note that if an exception escapes handler._execute it will be
# trapped in the Future it returns (which we are ignoring here).
# However, that shouldn't happen because _execute has a blanket
# except handler, and we cannot easily access the IOLoop here to
# call add_future (because of the requirement to remain compatible
# with WSGI)
f
=
self
.handler._execute(transforms,
*
self
.path_args,
*
*
self
.path_kwargs)
f.add_done_callback(
lambda
f: f.exception())
# If we are streaming the request body, then execute() is finished
# when the handler has prepared to receive the body. If not,
# it doesn't matter when execute() finishes (so we return None)
return
self
.handler._prepared_future
|
注意到这几步骤,
|
1
2
3
4
5
6
7
8
|
#实例化RequestHandler的子类
self
.handler
=
self
.handler_class(
self
.application,
self
.request,
*
*
self
.handler_kwargs)
#包装request,用于http中传输
transforms
=
[t(
self
.request)
for
t
in
self
.application.transforms]
#调用RequestHandler的_execute方法
self
.handler._execute(transforms,
*
self
.path_args,
*
*
self
.path_kwargs)
|
最后来看看Requesthandler的_execute方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
@gen
.coroutine
def
_execute(
self
, transforms,
*
args,
*
*
kwargs):
"""Executes this request with the given output transforms."""
self
._transforms
=
transforms
try
:
if
self
.request.method
not
in
self
.SUPPORTED_METHODS:
raise
HTTPError(
405
)
self
.path_args
=
[
self
.decode_argument(arg)
for
arg
in
args]
self
.path_kwargs
=
dict
((k,
self
.decode_argument(v, name
=
k))
for
(k, v)
in
kwargs.items())
# If XSRF cookies are turned on, reject form submissions without
# the proper cookie
if
self
.request.method
not
in
(
"GET"
,
"HEAD"
,
"OPTIONS"
)
and
\
self
.application.settings.get(
"xsrf_cookies"
):
self
.check_xsrf_cookie()
result
=
self
.prepare()
if
is_future(result):
result
=
yield
result
if
result
is
not
None
:
raise
TypeError(
"Expected None, got %r"
%
result)
if
self
._prepared_future
is
not
None
:
# Tell the Application we've finished with prepare()
# and are ready for the body to arrive.
self
._prepared_future.set_result(
None
)
if
self
._finished:
return
if
_has_stream_request_body(
self
.__class__):
# In streaming mode request.body is a Future that signals
# the body has been completely received. The Future has no
# result; the data has been passed to self.data_received
# instead.
try
:
yield
self
.request.body
except
iostream.StreamClosedError:
return
method
=
getattr
(
self
,
self
.request.method.lower())
result
=
method(
*
self
.path_args,
*
*
self
.path_kwargs)
if
is_future(result):
result
=
yield
result
if
result
is
not
None
:
raise
TypeError(
"Expected None, got %r"
%
result)
if
self
._auto_finish
and
not
self
._finished:
self
.finish()
except
Exception as e:
self
._handle_request_exception(e)
if
(
self
._prepared_future
is
not
None
and
not
self
._prepared_future.done()):
# In case we failed before setting _prepared_future, do it
# now (to unblock the HTTP server). Note that this is not
# in a finally block to avoid GC issues prior to Python 3.4.
self
._prepared_future.set_result(
None
)
|
注意这几个步骤:
|
1
2
3
4
5
6
7
8
9
10
|
#调用prepare
result
=
self
.prepare()
#找到相应的方法,并且调用
method
=
getattr
(
self
,
self
.request.method.lower())
result
=
method(
*
self
.path_args,
*
*
self
.path_kwargs)
#自动调用self.finish
if
self
._auto_finish
and
not
self
._finished:
self
.finish()
|
从Http请求过来,tornado会进行相应的处理。根据上面的流程,就可以比较清楚的弄清tornado的结构,然后逐步细细分析每一步。

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









