




 本文介绍了机器学习的基础概念,并通过房价预测实例讲解了单变量线性回归模型的工作原理。文章详细阐述了如何使用梯度下降算法来优化模型参数,以最小化预测误差。
本文介绍了机器学习的基础概念,并通过房价预测实例讲解了单变量线性回归模型的工作原理。文章详细阐述了如何使用梯度下降算法来优化模型参数,以最小化预测误差。
向Andrew Ng的机器学习课程致敬
机器学习入门
定义
- Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
- Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
分类
- Supervised learning
- 数据有标签:分类,预测
- Unsupervised learning
- 数据无标签:聚类
单变量线性回归
以房价预测来说明
背景
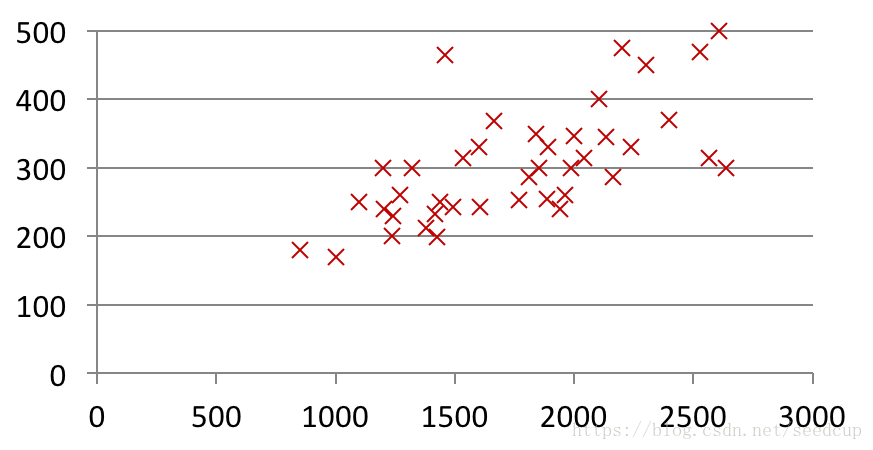
一个学生从波特兰俄勒冈州的研究所收集了一些房价的数据。
如图所示,将这些数据标在坐标上,横轴表示房子的面积,单位是平方英尺,纵轴表示房价,单位是千美元。
基于这组数据,假如你有一个朋友,他有一套 750 平方英尺房子,现在他希望把房子卖掉,能卖多少钱。
模型
- 可以画一条直线,让直线尽可能匹配所有数据。
- 可能还有更好的,比如我们用二次方程去拟合所有数据,即使用以下模型来模拟面积和售价的关系
这就是一个监督学习的例子。
损益函数
上面的模型中,如果来选择合适的参数
θ0
θ
0
和
θ1
θ
1
来尽量让预测值与真实值接近,那我们的模型就很完美了。
为此,我们定义一个函数来衡量不同参数,其模型与真实值的差异性,这样就能根据这个差异性来选择合适的参数。这个差异性叫做损益函数,对于线性回归模型来说,其损益函数定义如下:
寻找最合适的参数来使预测最接近真实值就转化为,求损益函数的最小值了。
梯度下降算法
给定上述模型已经损益函数,如何求最小的损益函数对应的参数呢。有一种非常有名的算法,叫梯度下降算法,可以用来求某个函数的全局或局部最小值。其实现过程如下:
- 初始函数值在某个峰值
- 随着迭代过程中,这个函数值会一步一步的下降,直至到某个局部最优或者全局最优的值
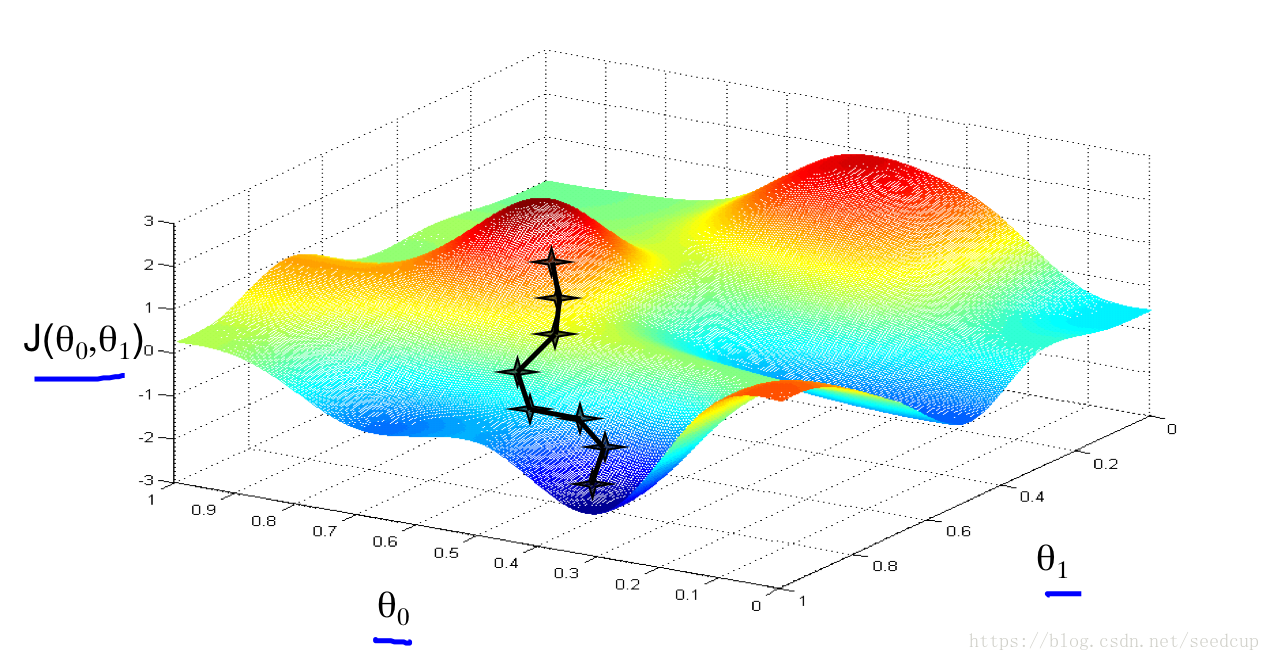
算法具体描述如下:
Gradient descent algorithm
repeated until convergence {
θj:=θj−α∂∂θjJ(θ0,θ1)for (j=0 and j=1) θ j := θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) f o r ( j = 0 a n d j = 1 )
}
注意:需要同时更新所有的参数,如下所示
tempθ0=θ0−α∂∂θ0J(θ0,θ1)tempθ1=θ1−α∂∂θ1J(θ0,θ1)θ0=tempθ0θ1=tempθ1 t e m p θ 0 = θ 0 − α ∂ ∂ θ 0 J ( θ 0 , θ 1 ) t e m p θ 1 = θ 1 − α ∂ ∂ θ 1 J ( θ 0 , θ 1 ) θ 0 = t e m p θ 0 θ 1 = t e m p θ 1
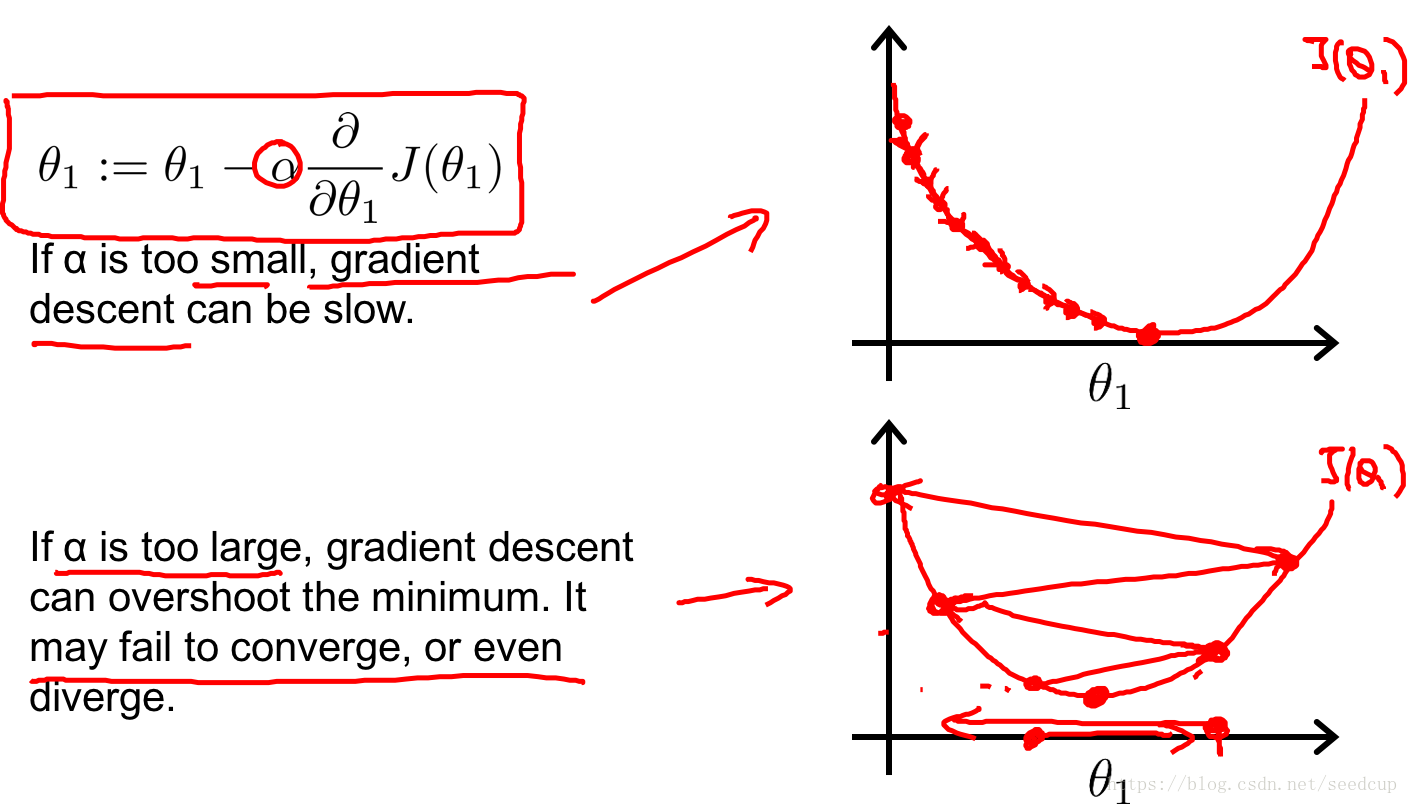
可以看到这里还有一个参数 α α 需要我们来确定,这个参数被称为学习率。
- 当 α α 比较小的时候,需要迭代很多次才能收敛到最小值。
- 而当 α α 比较大的时候,则可能导致梯度下降算法不能收敛,总是在最低值附近徘徊。
学习率对求损益函数的影响如下图所示:
一旦选定了学习率后,不用每次迭代都改变学习率的值,因为梯度下降算法会制动调整下降幅度来达到局部最优解。
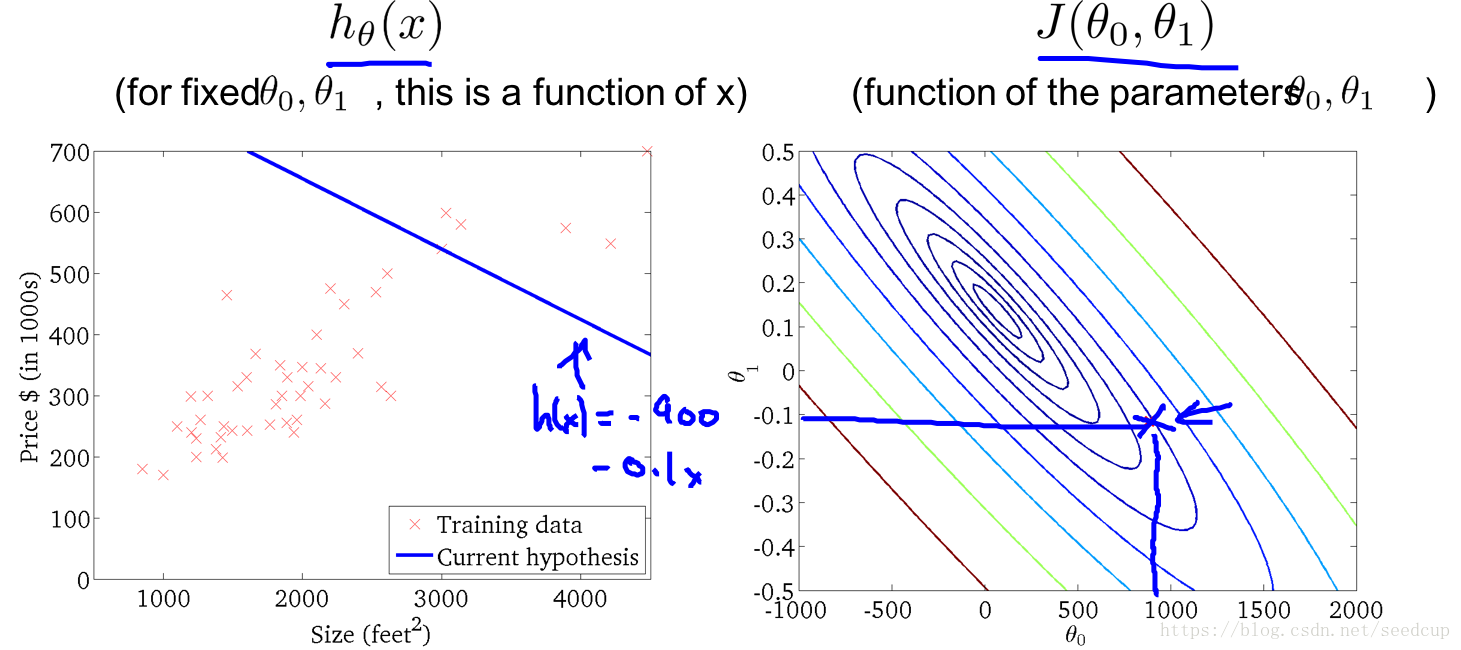
根据上述梯度下降算法描述,再来分析下单变量线性回归如何使用梯度下降算法求最优参数。如下公式所示,是单变量线性回归模型的参数计算方式。
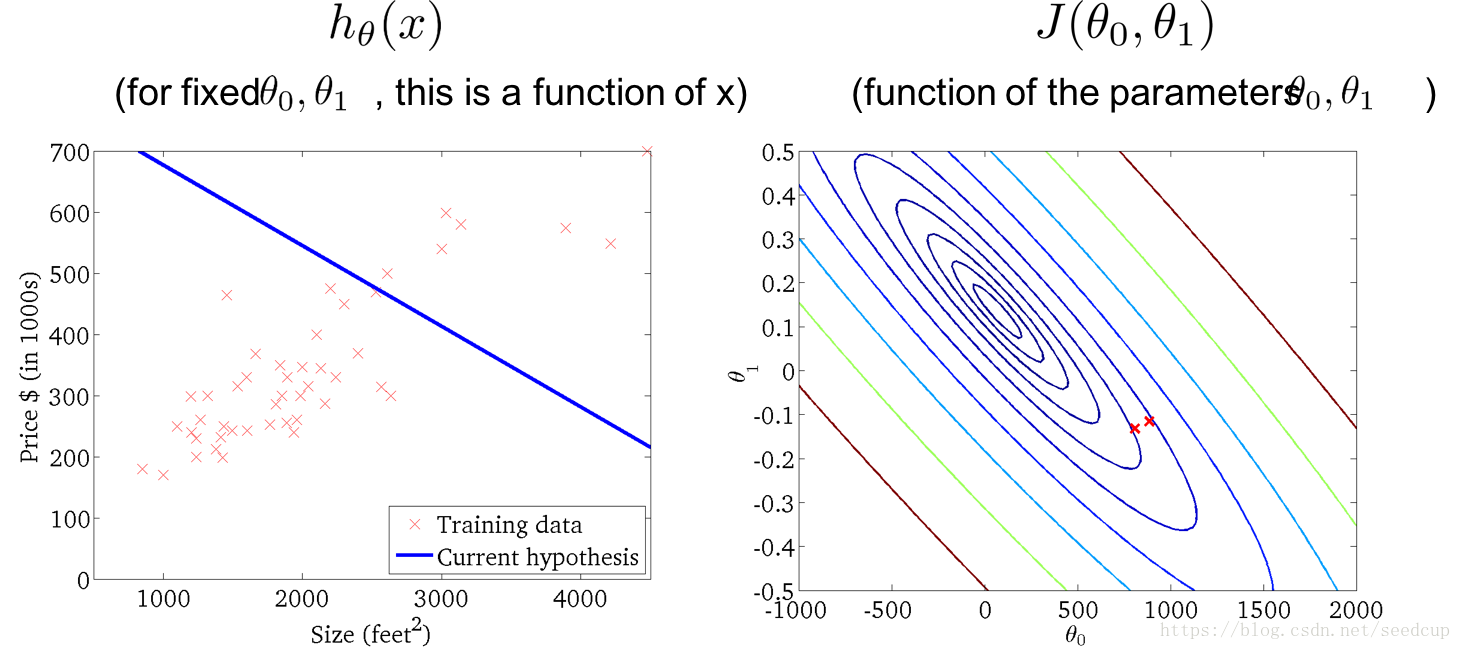
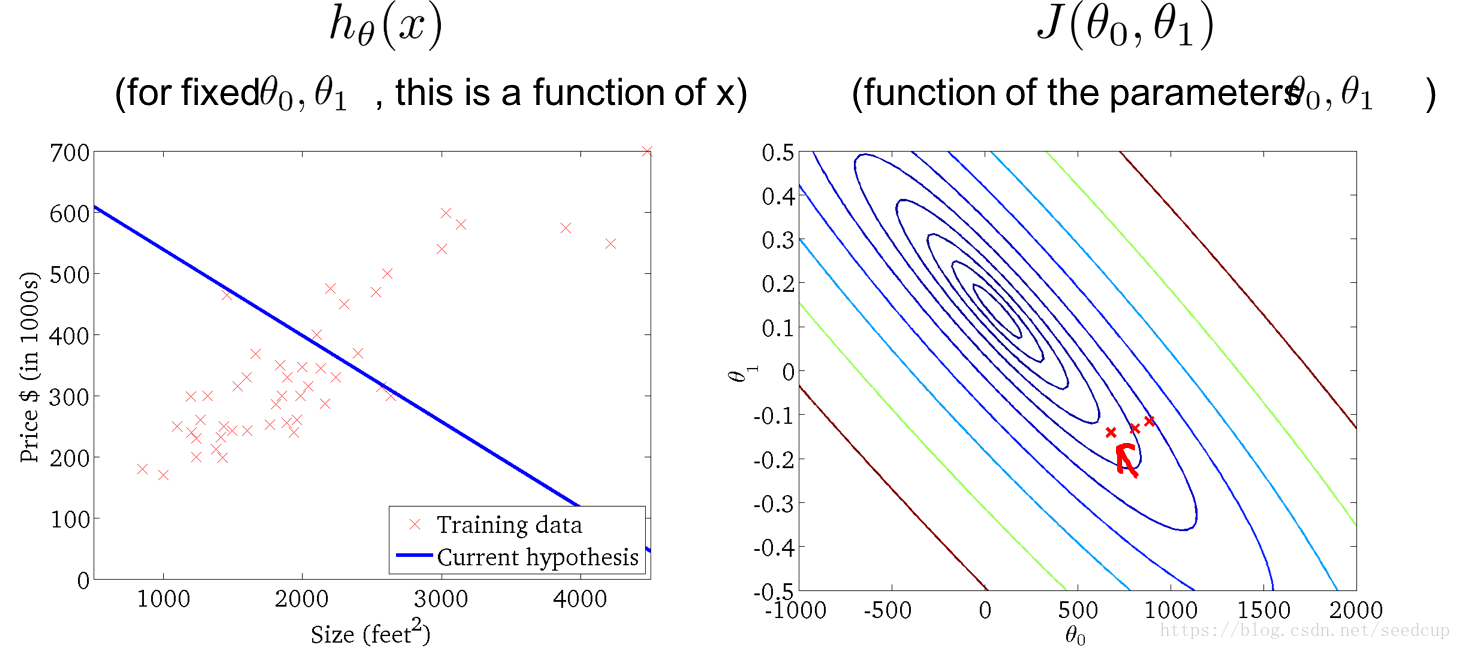
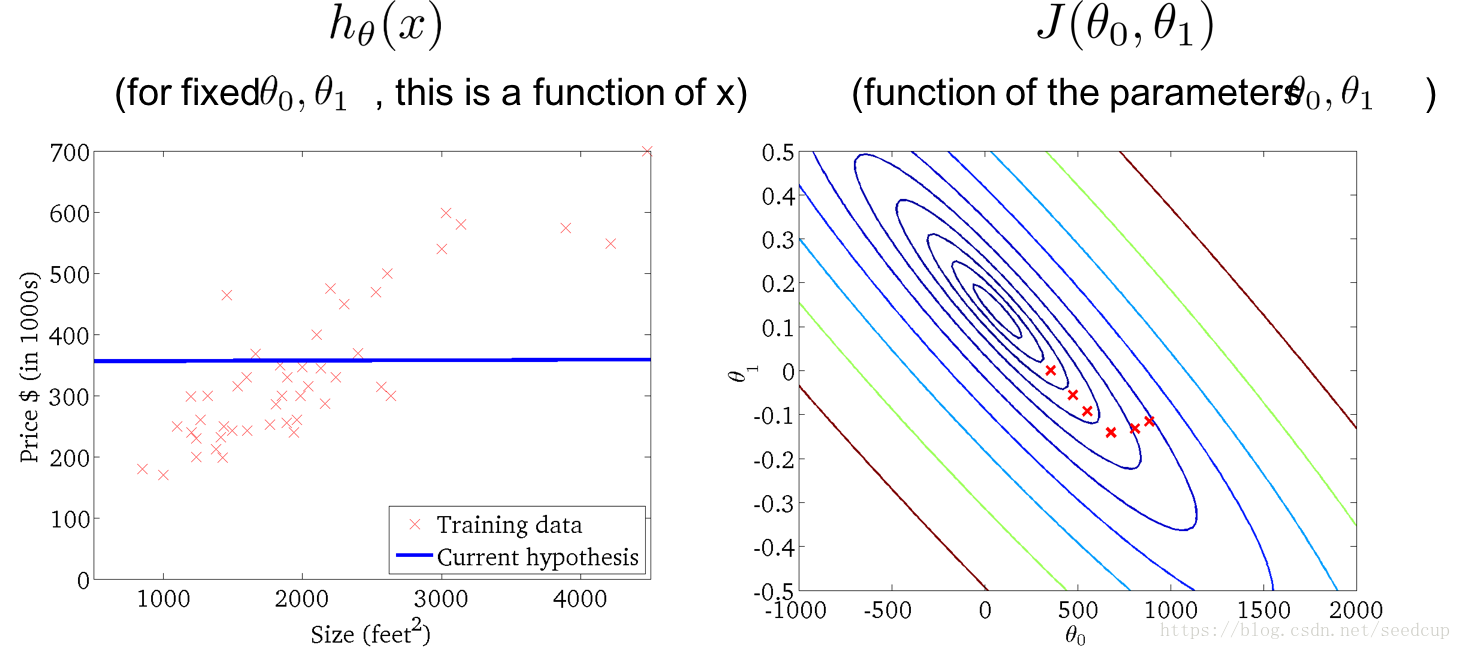
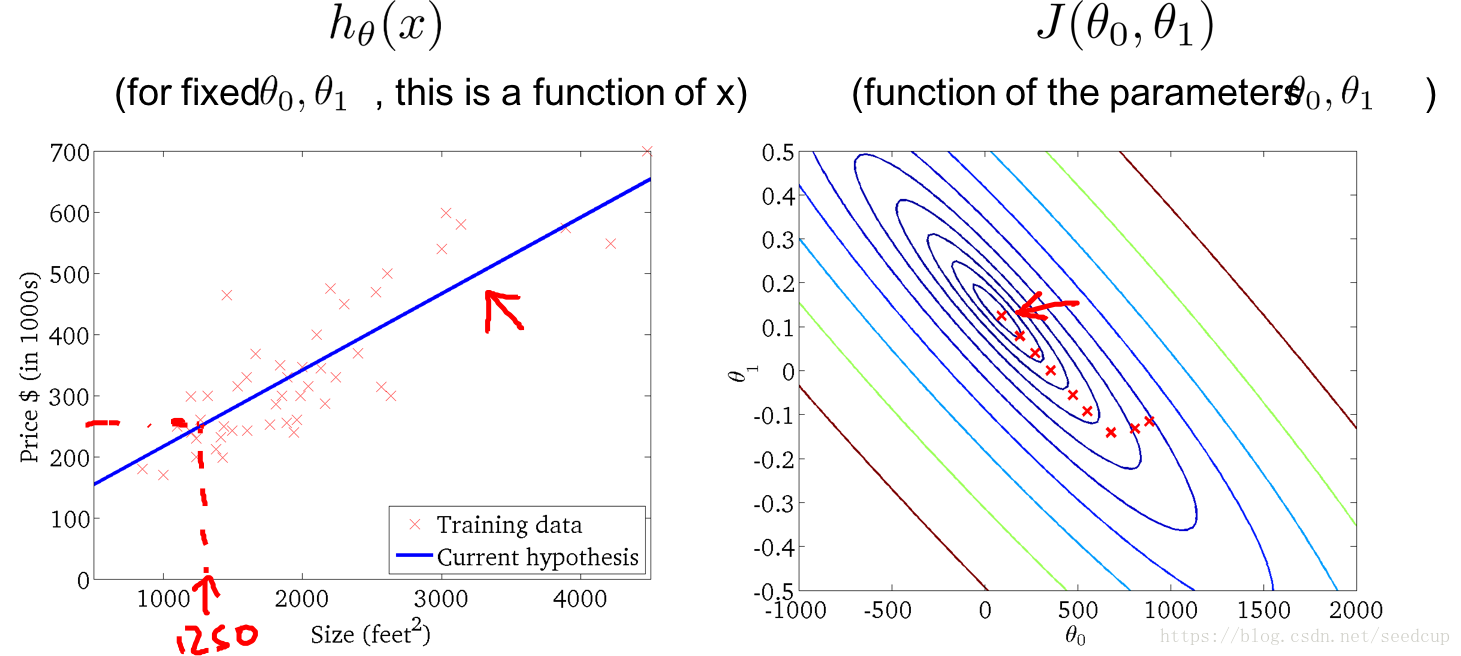
随着迭代进行,模型变化过程以下系列图所示:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









