



量化边缘计算对移动应用的影响
摘要
面向移动设备的互联网边缘计算卸载服务正成为现实。通过使用多种移动应用程序,我们探讨了此类基础设施相较于云在延迟和能耗方面的改进。我们展示了来自无线网络和4G LTE网络的实验结果,证实边缘计算为高度交互式移动应用带来了显著优势。
1. 引言
边缘计算是一种新范式,其中大量的计算和存储资源被部署在互联网边缘,靠近移动设备或传感器。诸如“云朵”(本文中我们使用的术语)[22]、“微型数据中心(MDC)”[12]、“雾”[1],以及“移动边缘计算(MEC)”[4]等术语均用于指代这些小型的、位于边缘位置的计算节点。边缘计算因其在可扩展性、延迟和带宽方面相较于纯云模型具有潜在优势而受到推动。更实际地,一些研究源于软件定义网络(SDN)和网络功能虚拟化(NFV)的发展趋势,以及同一硬件可以同时提供SDN、NFV和边缘计算服务的事实。这表明提供边缘计算服务的基础设施可能很快变得无处不在,并且其部署密度可能超过当前内容分发网络(CDN)节点的密度。然而,尽管该领域发展迅速,但这类系统实际上为终端用户带来的好处仍不明确。本文的目标是为这一问题提供量化的答案。
我们关注边缘计算的一个特定优势,即能够以低延迟将移动设备的计算任务卸载到云朵。这一能力最初被演示允许出于个人或课堂教学目的,免费制作本作品全部或部分内容的数字版或印刷版副本,但前提是不得出于盈利或商业优势的目的制作或分发这些副本,且所有副本须在首页注明本声明及完整引用信息。本作品中第三方组件的版权必须得到尊重。对于所有其他用途,请联系版权所有者/作者。APSys’16, 2016年8月4日至5日, 中国香港。c© 2016 版权由版权所有者/作者持有。计算机协会ISBN 978‐1‐4503‐4265‐0/16/08。DOI: http://dx.doi.org/10.1145/2967360.2967369
由诺布尔等人于1997年提出[19],他们利用该方法在资源受限的移动设备上实现了性能可接受的语音识别。1999年,Flinn 等人[8]扩展了这一方法以改善电池续航。这些概念在2001年的一篇论文中被进一步概括,引入了网络觅食这一术语,指通过利用附近的基础设施来增强移动设备的数据或计算能力[20]。如今,向云端卸载已成为主流,被广泛应用于iOS和安卓设备上的语音识别。对于未来兼具高计算需求和低延迟要求的应用程序,例如认知辅助[5]或移动增强现实,卸载到网络边缘的云朵可能将成为新的常态。
在本文中,我们探讨“相对于云端卸载,卸载到云朵究竟有多好?”我们关注对终端用户重要的指标,即响应时间和能耗。针对多种应用程序(其中一些由开发者预先分割,另一些由运行时系统动态分割),我们量化了云朵相对于云端卸载对这些指标的影响。我们研究了通过无线网络和4G LTE进行卸载时这些指标的差异。此外,我们还报告了这些指标对应用程序交互级别的敏感性。
2. 实验方法
研究移动卸载到云和云朵受到两个因素的复杂影响。首先,大多数现有应用程序已被优化以在移动设备或移动加云环境中良好运行。它们的设计基于移动设备的资源限制以及相对于云较高的延迟。因此,目前没有可用于生产的、在移动设备上运行过于计算密集型但对云又过于延迟敏感的应用程序。由于这种应用程序特性的组合正是边缘计算的理想应用场景,我们广泛查阅了文献,并确定了具有这些特征的研究型应用(第2.1节)。这些应用被静态预分割为云和移动设备组件。
其次,卸载的好处在很大程度上取决于应用程序分割的质量。静态预分割可能并非最优。当无线网络带宽等资源发生变化时,需要采用动态分割可能是必要的。作为我们结果中一个无偏的外部因素,我们使用了一种名为COMET [11]的现有工具,该工具代表了对现成的Android应用程序进行动态划分的最新技术。它可以根据其动态划分算法,透明地将线程从移动设备迁移到远程服务器并返回。与预划分应用程序相同的原因,市面上没有现成的计算密集型且对延迟敏感的应用程序。因此,我们使用计算密集型基准测试,优先选择原始 COMET论文中使用的基准测试,来代表这类应用程序。
通过探索多样化的数据点,我们提高了洞察结果的稳健性和显著性。以响应时间作为性能的关键指标,我们重点探讨与卸载位置选择相关的以下问题:
- 对预划分应用程序的影响。
- 对COMET划分的应用程序的影响。
- 与应用程序交互级别的相互作用。
- 与无线网络类型之间的相互作用。
- 对移动设备能耗的影响。
2.1 应用程序
我们研究了现有研究文献中的三个静态预分割应用程序:
-
FACE
是一种人脸识别应用程序,该程序首先检测图像中的人脸,然后尝试从一个小型的预先填充的数据库中识别人脸。它在微软Windows上运行,使用OpenCV实现了特征脸方法 [25] [3]。
-
MAR
是一款在场景中标记建筑物和地标的增强现实应用[24]。该原型应用程序使用了包含 200 栋建筑物的 1005 张标注图像的数据集。MAR 在微软 Windows 上运行,并大量使用了 OpenCV[3], Intel 集成性能原语 (IPP) [15], 和多个处理线程。
-
FLUID
是基于物理的计算机图形学的一个示例 [23]。该 Linux 应用程序运行一个多线程的虚拟流体物理模拟,并利用客户端加速度计读数使用户与模型交互。我们在包含 2218 个粒子系统的设备上以 20 毫秒时间步长运行 FLUID,最高可生成每秒50帧。
这些应用程序中的每一个都被分为前端移动应用和执行大部分计算的后端服务器。移动前端捕获并发送输入(FACE 和 MAR 的图像,FLUID 的加速度计数值),并显示输出(为 FACE 和 MAR 显示文本标签,以及为 FLUID 渲染一组粒子)。输入和输出的差异体现在这些应用程序的网络传输大小上,如图1所示。
我们还使用COMET研究了三个未经修改的Android应用。其中一个来自原始的COMET论文,另外两个来自Google Play商店:
-
Android版Linpack
[6]执行数值线性代数计算,以求解稠密的N×N线性方程组。该基准测试被用于原始的COMET论文 [11]中。
-
CPU基准测试
[26]是一种简单的基准测试工具,用于测试和比较手机的处理速度以及中央处理器超频的效果。
-
PI基准测试
[17]通过计算 π(最高可达200万位精度)来测量中央处理器和内存速度。它会定期将中间状态保存到文件中,可能会触发COMET的线程迁移。
所有这些应用程序都是计算密集型的,从卸载中应能获得显著收益。然而,如图2所示,它们在使用 COMET运行时的数据传输量和频率上存在差异。
2.2 实验设置
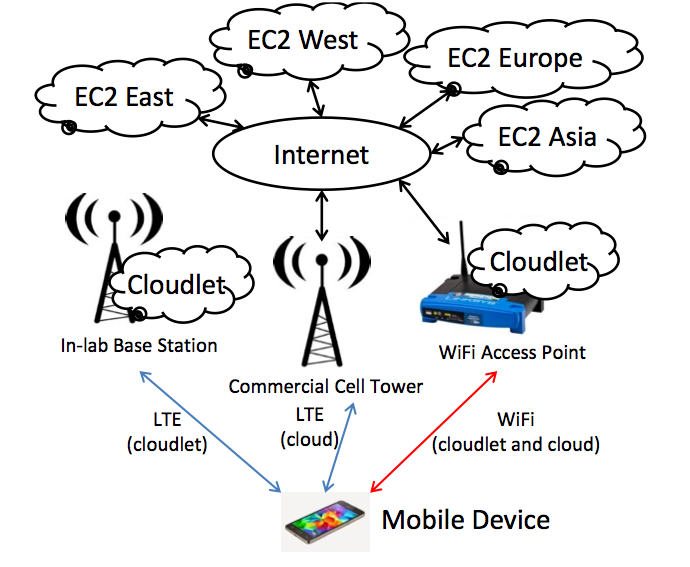
图3和图4描述了我们用于实验的云朵、云和移动设备。在云(Amazon EC2)中,我们使用了在CPU时钟速度方面可用的最强大的虚拟机(VM)实例。该实例具有8个核心(VCPUs),每个核心的时钟频率为可用的最高值(2.8 GHz);其内存大小对于所有测试的应用程序来说都绰绰有余(15吉字节)。对于云朵卸载,我们使用运行在戴尔 Optiplex 9010台式机上的虚拟机,该机器具有4个核心( VCPUs),时钟频率限制为2.7吉赫兹。该虚拟机(VM)实例分配有4吉字节内存。通过将相对较弱的云朵与更强大的 EC2云实例进行比较,我们有意使云朵处于不利地位。因此,我们在实验中观察到的任何云朵优势都应被视为非常有意义。
我们在实验中使用了两种不同的移动设备。由于 COMET无法在高于4.1.X版本的Android系统上运行,因此这些实验使用了一台运行Android 4.1.1的三星Galaxy Nexus手机。对于预划分应用程序,由于部分应用程序只能在x86硬件上运行,因此我们对硬件的选择受到了限制。因此,所有涉及预划分应用程序的实验均使用一台戴尔 Latitude 2120上网本,其计算能力与最新的智能手机相当。
李等人[16]报告称,从260个全球观测点到其最优亚马逊EC2实例的平均往返时间(RTT)为74毫秒,这与我们在实验设置中EC2‐西海岸的往返时延相近。我们注意到我们的与EC2‐East的连接速度要快得多(8毫秒),属于非典型情况。由于我们组织是亚马逊AWS的重要客户,因此在互联网骨干网中享有通往EC2‐East的优先路由。这种优先路由对于野外的移动设备而言是无法获得的。因此,在解释我们的结果时,应将EC2‐East视为最佳可能情况,而EC2‐西海岸则应被视为典型情况。除非另有说明,本文其余部分中的“云”均指EC2‐西海岸。


图5 展示了我们实验中使用的网络。共有五种配置,如下所述。
-
无卸载
:服务器组件在移动设备上本地运行,从而避免了所有网络传输。
-
云‐WiFi
:移动设备通过802.11n连接到私有 WiFi接入点,该接入点通过以太网连接到企业网络,再经由互联网连接到Amazon AWS站点。
-
云粒‐WiFi
:这与云‐WiFi配置类似,不同之处在于网络流量只需传输到云朵即可,而云朵与无线网络接入点位于同一以太网网段。
-
云粒‐LTE
:在美国联邦通信委员会(FCC)颁发的实验用途许可证下,我们搭建了一个实验室内的4G LTE网络。该实验室蜂窝网络使用一个发射功率衰减至10毫瓦的诺基亚 eNodeB。通过eNodeB的网络流量经由诺基亚RACS网关和本地以太网段传输至云朵。
-
云‐LTE
:由于实验室蜂窝网络与互联网之间的网络设置存在限制,我们的实验室蜂窝站无法实现云‐LTE选项的典型性能。因此,我们使用商用T‐Mobile 4G LTE网络上的蜂窝数据服务连接到互联网,进而访问亚马逊AWS站点。
由于我们在实验室LTE网络中使用了实验频段,只有少数手机(如谷歌Nexus 6)能够连接该网络。遗憾的是, COMET无法在这款手机上运行。因此,在进行云粒‐LTE实验时,我们通过USB和WiFi网络共享,分别将上网本和支持 COMET的智能手机连接到谷歌Nexus 6。对于一致性方面,我们也使用网络共享与云‐LTE。
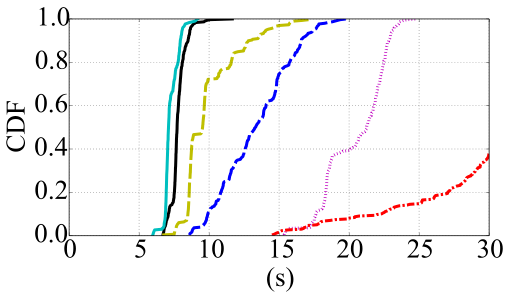
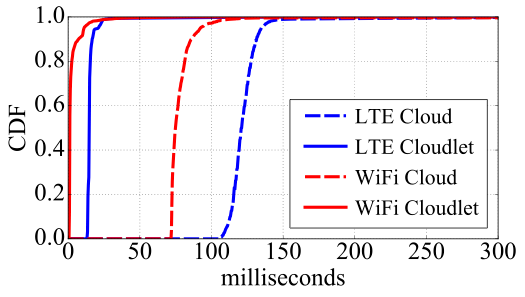
图6显示了除无卸载外上述所有网络配置的往返时延,使用Linux ping命令并设置1毫秒ping间隔。ping往返时延代表了我们网络配置可能达到的最小基准延迟。
3. 实验结果
3.1 Wi‐Fi卸载性能
图7比较了将预划分应用程序卸载到亚马逊AWS站点或云朵时的响应时间。同时展示了未卸载时的应用程序响应时间。图中绘制了三次运行中测得的响应时间的累积分布函数(CDF)。
随着到卸载站点的延迟增加,响应时间明显变差。对于所有三种应用程序而言,由于网络延迟更高以及到更远卸载站点的有效带宽更低,其CDF曲线向右偏移。对于更远程的站点,CDF曲线的上升也更为平缓,表明响应时间的波动更大,这是由于广域网网络状况的不确定性更大所致。(这些影响在FACE应用本身较大的性能固有变化下有所掩盖。)因此,无卸载通常比卸载到远程云提供更快的响应时间。云朵始终提供最佳的响应时间。
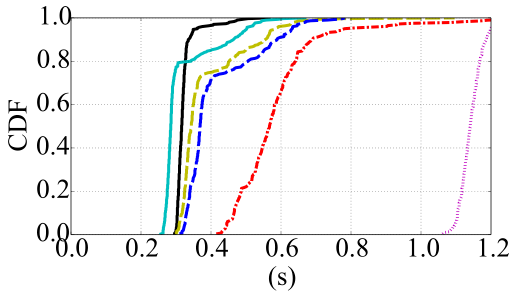
图8展示了基于COMET的应用程序的结果。这些结果同样表明响应时间受卸载位置的影响。EC2‐西海岸、EC2‐欧洲和EC2‐亚洲明显比EC2‐East数据中心差。对于PI基准测试,EC2‐亚洲的延迟过大,在图中已超出可见范围。然而,这些运行时间较长的应用程序(运行时间为数秒到数十秒,而非几十到几百毫秒)改变了EC2‐East数据中心与云朵之间的相对性能。如第2.2节所述,从我们的测试平台到EC2‐East数据中心的延迟异常良好,且并不比无线网络延迟高多少。因此,云实例相较于云朵所具备的更强计算能力现在变得显著起来,使得EC2‐East数据中心成为最快的选项。
结果还显示了应用程序特性的影响。CPU基准测试传输的数据量非常少,因此各EC2曲线看起来非常相似,主要因到不同站点的往返时延差异而有所偏移。Linpack传输的数据量显著增加,各EC2站点之间的响应时间差异更加明显。PI基准测试总共传输的数据量相近,但分为多次传输,因为处理线程会被转移。

在移动设备和后端之间来回传输。因此,对于PI基准测试而言,远程云的网络效应被放大了。我们将在第3.3节中进一步探讨多次迁移的影响。
3.2 WiFi卸载与能耗
除了提升性能外,计算卸载还可以降低移动设备的能耗。我们在测量移动设备功耗的同时重新运行了无线网络卸载场景。对于上网本,我们拆下电池,并使用WattsUp功率计[27]记录交流电源线的总功耗。对于智能手机,我们在电池触点处接入Monsoon电源监测仪[18],记录基准测试运行期间的电压和电流消耗。
每个请求或每次运行所消耗的平均能耗如图9所示,括号内为标准差。将计算任务卸载到任何站点都会显著降低移动设备的功耗(从而减少消耗的能量),因为移动设备不再执行繁重的计算。卸载站点的选择对功耗没有影响,功耗在各种情况下大致相同。
| 卸载 | None | 云朵 | East | West | 欧洲 | Asia |
|---|---|---|---|---|---|---|
| Face† (J/查询) | 12.4 (0.5) | 2.6 (0.3) | 4.4 (0.0) | 6.1 (0.2) | 9.2 (4.1) | 9.2 (0.2) |
| FLUID† (焦耳/帧) | 0.8 (0.0) | 0.3 (0.0) | 0.3 (0.0) | 0.9 (0.0) | 1.0 (0.0) | 2.2 (0.1) |
| MAR† (J/查询) | 5.4 (0.1) | 0.6 (0.1) | 3.0 (0.8) | 4.3 (0.1) | 5.1 (0.1) | 7.9 (0.1) |
| Linpack (J/运行) | 40.3 (2.6) | 13.0 (0.7) | 13.3 (2.3) | 16.9 (1.8) | 18.2 (1.9) | 38.1 (4.1) |
| CPU (J/运行) | 9.6 (1.4) | 5.7 (0.3) | 5.9 (0.3) | 5.8 (0.3) | 5.9 (0.2) | 6.0 (0.2) |
| PI (J/运行) | 129.7 (2.9) | 53.9 (2.1) | 57.6 (1.8) | 107.6 (8.6) | 162.8 (18.0) | 203.4 (16.7) |
括号中的数字为三次运行的标准差。 †能量测量期间显示屏已关闭。

云朵和云的情况。然而,执行时长确实存在差异,因此每次查询/帧/运行所消耗的能量受卸载站点的影响很大。在所有情况下,云小站卸载每次执行所消耗的能量最少,而更远的卸载站点则导致能耗逐渐增加。事实上,在许多情况下,卸载到EC2‐亚洲或EC2‐欧洲所造成的能耗高于不卸载。
3.3 交互级别对性能的影响
尽管 COMET 能有效卸载未经修改的安卓应用程序中的计算密集型部分,但任何与设备硬件的交互(例如传感器输入/输出、屏幕更新或文件操作)都将导致应用线程迁移回移动设备。这可能在程序执行过程中引发大量线程迁移,从而放大网络延迟和带宽的影响。
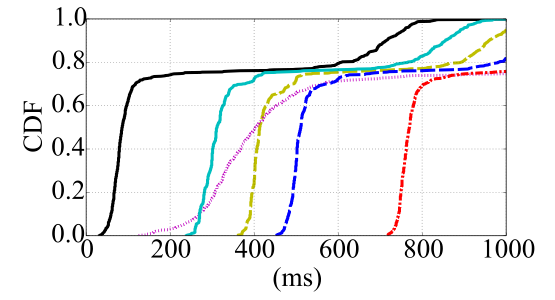
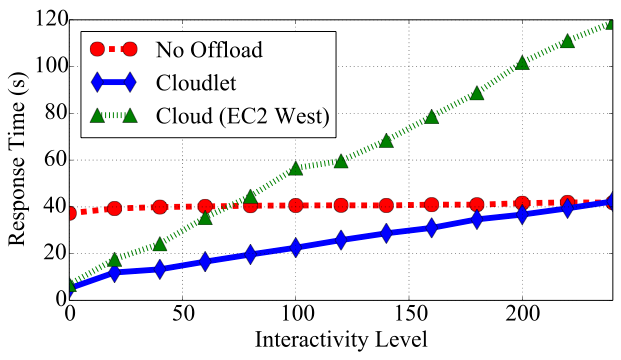
为了进一步研究交互性的影响,我们创建了一个用于分解大整数的自定义计算密集型应用程序。在卸载方面, COMET 将文件输入/输出视为与显示更新类似的交互。当应用程序线程尝试任何交互时,COMET 会在允许操作继续之前将其迁移回移动设备。我们的应用程序在可配置的迭代次数后将中间结果保存到文件中,使我们能够调整由 COMET 触发迁移的频率。图10 显示了随着交互级别(文件操作数量)增加,应用程序性能的变化情况。无卸载情况下的执行时间几乎保持不变,因为即使有数百次文件操作,该应用程序在移动设备上仍然是计算密集型的。
然而,云端卸载性能受到显著影响,一旦执行过程中超过 75次输入/输出操作,其速度就比直接在移动设备上运行还要慢。相比之下,向云朵的卸载对交互级别的敏感度要低得多。在不超过240次文件写入的情况下,其性能均优于不进行卸载的情况。这些结果表明,云朵可以通过减弱应用程序交互性的影响,极大地提升 COMET 等框架的效果。独立于我们的研究,Tango[10]也证实了应用程序的交互性会严重影响代码卸载。该研究使用确定性重放来提升卸载性能。相比之下,我们主张使用云朵来彻底避免长时间的响应延迟。
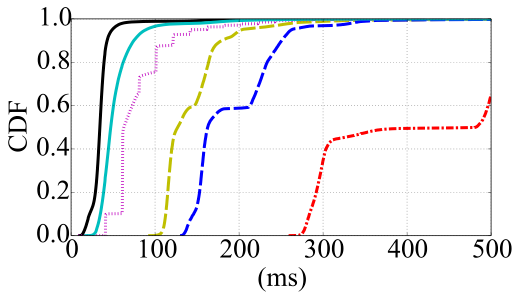
虚线表示周期性ping(间隔为1毫秒)。
3.4 无线电模块链路管理的影响
我们最初在LTE网络上的智能手机实验表明,网络延迟 tends to 在离散值之间跳跃。图11显示了从一个逐步增加回复延迟的简单回声服务器所观测到的LTE和无线网络响应时间的累积分布函数。我们原本期望得到一条直线,表示响应时间均匀分布,但结果却呈现出明显的阶梯状模式。由于这种阶梯状模式在LTE和无线网络中均可见,我们认为这是由于移动设备对无线电模块采取了激进的断电措施所致。该现象并非由CPU调度引起,且在测试的非手机设备的无线网络结果中并未出现。对于LTE,我们观察到两种不同的台阶大小,它们在不同时间开始出现。后者可能是由于商用LTE网络配置在回收空闲资源方面更加激进所致。我们认为不同的台阶大小是由于LTE中使用了非连续接收模式(DRX)[2]。该机制通过短睡眠周期和长睡眠周期使移动设备能够断电射频电路。DRX的使用及睡眠持续时间由LTE网络决定。
我们的实验还表明,如果移动设备执行频繁的数据传输(例如,周期性后台ping请求),这些影响就会完全消失。为了避免延迟离散化的干扰效应,我们所有的长期演进技术实验均以1毫秒间隔进行后台ping运行。
3.5 长期演进技术卸载性能
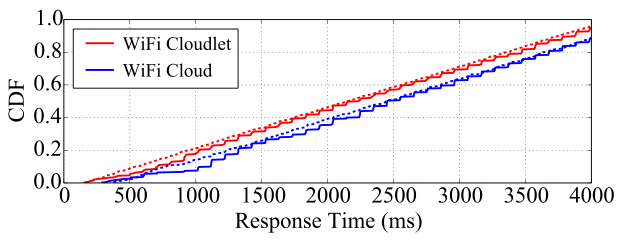
图12显示了使用长期演进技术时三个预划分应用程序的响应时间。总体而言,这些结果与无线网络实验的结果非常相似。由于长期演进技术的延迟略高,与无线网络结果相比,曲线向右偏移。此外,商用LTE网络与 EC2‐East数据中心的连接性不如我们的无线网络设置好。因此,尽管EC2‐East的响应时间在云场景中仍然是最优的,但并未达到我们在无线网络实验中的水平。在所有情况下,向云朵卸载都能提供最佳的响应时间。
3.6 长期演进技术 能量权衡
在之前的长期演进技术实验中,我们使用间隔为1毫秒的背景ping来克服离散化延迟效应根据第3.4节的影响来最小化响应时间。然而,这种方法可能会对移动设备的能耗产生负面影响。在此,我们通过改变ping间隔来量化响应时间与能耗之间的权衡。
由于我们需要使用网络共享设置在实验室LTE网络中运行所选的应用程序,这使得能耗测量变得困难。因此,我们使用另一种可以直接在谷歌Nexus 6上运行的应用程序( Tesseract‐OCR [9])。由于Nexus 6智能手机没有可拆卸电池,我们通过操作系统报告的电池电压和电流来测量能耗¹。
图13展示了Tesseract‐OCR的响应时间和功耗,比较了本地执行(最左侧柱状图)与卸载到云粒(上方图表)和卸载到云端(亚马逊EC2‐西区,下方图表)的情况。即使没有后台ping,卸载也能明显降低移动设备的功耗。当向云端卸载时,这会带来响应时间的代价。相比之下,在云粒上,延迟和能耗均有所降低。随着背景ping频率的增加,虽然会增加功耗,但可以改善响应时间。当向云端卸载时,每1毫秒进行一次ping请求(最右侧两根柱状图)与不进行ping请求的情况(第二组柱状图)相比,响应时间减少了17%,但功耗增加了29%。由于我们的实验室 LTE网络不会像商用网络那样积极地指示移动设备节省功耗,因此添加背景ping对功耗的影响更为显著。
¹ 在 /sys/class/power_supply/battery/电流_now 和 /sys/class/power_supply/battery/voltage_now
向云朵卸载时,背景ping的影响并不显著,尽管整体趋势仍然可见。当持续的低响应时间至关重要时,重新添加背景ping可以成为减少长期演进技术链路管理延迟影响的有效工具。
4. 相关工作
本研究量化了云朵卸载与云端卸载的相对优势。采用以应用为中心的视角,认识到移动用户渴望流畅的交互体验和更长的电池续航。对于语音识别和人脸识别等计算密集型和内存密集型应用程序,要在轻便小巧的移动硬件上实现这些特性,唯有通过卸载才能实现。本研究涵盖多种应用程序,考虑了静态和动态分割策略,考察了无线网络和4G LTE网络,探讨了应用交互性的作用,并揭示了一些4G LTE网络的特性。
据我们所知,目前尚无其他研究对云端卸载与云小站卸载进行如此广泛而详细的探讨。在研究思路方面最接近的是Ha等人于2013年报告的测量结果[13]。该研究仅针对预划分应用程序和无线网络进行了考察,未涉及动态分割的应用程序或4G LTE网络。
更广泛相关的是网络觅食领域的长期研究历史。诺布尔等人[19]和弗林等人[8]的奠基性工作已在第1节中提及。弗林的综述[7]和Satyanarayanan的回顾[21]详细阐述了网络觅食的发展历程。
与我们关于在4G LTE网络上进行卸载的研究相关的是Huang等人于2012年对广域无线网络的广泛研究 [14]。该研究考察了多种网络技术,但仅考虑了当前的 Web应用程序。相比之下,我们的工作关注的是能够代表边缘计算未来工作负载的应用程序。一个直接的对比点是商用4G LTE网络上观测到的往返时延(RTT)。Huang等人报告的平均值约为70毫秒,考虑到实验设置的不同,这一结果与我们的测量数据一致。相比之下,我们在实验性4G LTE网络上观测到的RTT约为15毫秒,这表明大部分延迟发生在商用4G LTE网络的演进分组核心网(EPC)中,而非其射频段(RF segment)。
5. 结论
我们的研究表明,对于预划分应用程序以及像 COMET 这样的动态卸载框架而言,选择合适的卸载位置至关重要。与平均云端(EC2‐西海岸)相比,我们证明边缘计算可以显著改善移动设备的响应时间和能耗。这些优势不仅限于无线网络环境。即使通过长期演进技术( LTE)进行卸载,边缘计算依然能够提供更优越的结果。
我们的结果还表明,盲目地将计算任务卸载到云中可能是一种失败的策略。将任务卸载到远程云可能导致性能更低、能耗更高,甚至不如在移动设备上本地运行。对于高度交互的应用程序,即使卸载到附近的云也可能对性能产生负面影响。这类应用最明显地表明,必须采用边缘计算才能通过卸载实现性能和能耗的优化。
人们对移动增强现实和认知辅助等深度沉浸式应用程序的商业兴趣日益增加。对于这类交互式且计算密集型的应用程序,我们的结果表明,业界在构建边缘计算基础设施方面的努力并非徒劳。相反,此类基础设施将成为推动这一新型应用程序发展的关键使能因素。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









