







Beautiful Soup4(BS4)是Python的一个第三方库,用来从HTML和XML中提取数据。
安装
使用Beautiful Soup4提取HTML内容,一般要经过以下两步。
(1)处理源代码生成BeautifulSoup对象。

这里的“解析器”,可以使用html.parser:
soup = BeautifulSoup(open('test.html', encoding='utf-8'), features='html.parser')
如果安装了lxml,还可以使用lxml:

(2)使用find_all()或者find()来查找内容。
如下html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<div class="userful">
<ul>
<li class="info">我需要的信息1</li>
<li class="test">我需要的信息2</li>
<li class="strange">我需要的信息3</li>
</ul>
</div>
<div class="useless">
<ul>
<li class="info">垃圾1</li>
<li class="info">垃圾2</li>
</ul>
</div>
</body>
</html>查找单个元素的文本内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('test.html', encoding='utf-8'), features='html.parser') #解析源代码生成BeautifulSoup对象
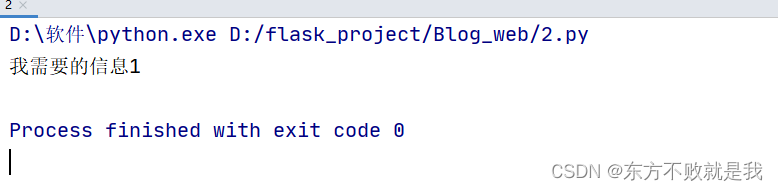
info=soup.find(class_='info') #利用标签查找到元素
print(info.string) #用元素的string属性输出元素的text
 根据标签查找查找多个元素文本
根据标签查找查找多个元素文本
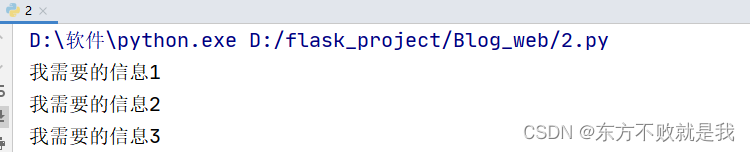
from bs4 import BeautifulSoup soup = BeautifulSoup(open('test.html', encoding='utf-8'), features='html.parser')#抓大放小 userful=soup.find(class_='userful') li_list=userful.find_all('li')#直接根据标签查找 且能查找到所有li标签元素 for li in li_list: print(li.string) #输出我需要的信息1 我需要的信息2 我需要的信息3

find_all
find_all(self, name=None, attrs={}, recursive=True, string=None,
limit=None, **kwargs)
name就是HTML的标签名,类似于body、div、ul、li。
· attrs参数的值是一个字典,字典的Key是属性名,字典的Value是属性值

这种写法,class就不需要加下划线。
· recursive的值为True或者False,当它为False的时候,BS4不会搜索子标签。
· text可以是一个字符串或者是正则表达式,用于搜索标签里面的文本信息,因此,要寻找所有以“我需要”开头的信息,还可以使用下面的写法
content=soup.find_all(text=re.compile('我需要'))
for each in content:
print(each.string)
· **kwargs表示Key=Value形式的参数。这种方式也可以用来根据属性和属性值进行搜索。这里的Key是属性,Value是属性值。在这里如果需要搜索HTML标签的class属性,就需要写成“class_”

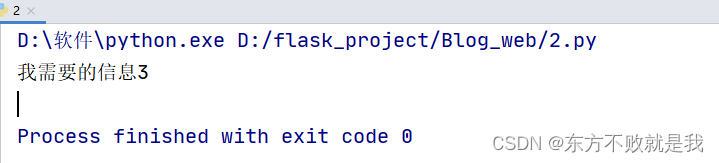
这种写法也支持正则表达式。例如对于“我需要的信息3”,它的class属性的属性值为“strange”,因此如果使用正则表达式,就可以写为
content=soup.find_all(class_=re.compile('strange'))
for each in content:
print(each.string)
获取属性值
除了获取标签里面的文本外,BS4也可以获取标签里面的属性值。如果想获取某个属性值,可以将BeautifulSoup Tag对象看成字典,将属性名当作Key
userful=soup.find(class_='userful')
all_conent=userful.find_all('li')
for li in all_conent:
print(li['class'])

总结:对于xpath查找html内容,和BS查找html内容来说,BS方法,主要是利用标签,属性和属性值,来查找文本,用起来非常简单,而xpath方法,还需要费劲去写xpath,看起来也不容易分辨。
内容来源:


















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









