






 本文探讨了使用OpenCV和深度学习技术进行钢印识别的过程,包括样本定制、分割钢印文本、钢印号码识别及模型改进等内容。通过深度学习模型的训练,实现了较好的钢印识别效果。
本文探讨了使用OpenCV和深度学习技术进行钢印识别的过程,包括样本定制、分割钢印文本、钢印号码识别及模型改进等内容。通过深度学习模型的训练,实现了较好的钢印识别效果。
采用OpenCV和深度学习的钢印识别
[这个帖子标题党了很久,大概9月初立贴,本来以为比较好做,后来有事情耽搁了,直到现在才有了一些拿得出手的东西。肯定不会太监的。好,转入正题:]
原始需求:
系统将使用手机等设备利用光学字符识别技术实现钻具编号自动识别,减少作业人员的工作量
隐含分析:
对场景本身来说,要进行人工核对(或者修改)是必不可少的,因此工作量未必是减少。但是该场景具有智能化的意义,这是隐含的目的。
在识别效果和工作业务上结合起来才能出最好的结果。
样本定制:
步骤:
1、从前期手机拍取的照片中选取了一些效果较好的图片
2、在图片中截取钢印部分做为样本

3、对样本图片进行标定:将钢印的号码标定为目标标签,作为深度学习的训练目标
4、采集样本:将每幅图片网格化,网格内的小图片作为样本,样本的标签与小图片中的目标标签一致
5、划分训练集和测试集:将所有样本(小图片)的80%作为训练集,其余作为测试集。所有的样本不重复,因此训练集和测试集没有重合。

分割钢印文本
流程如下:
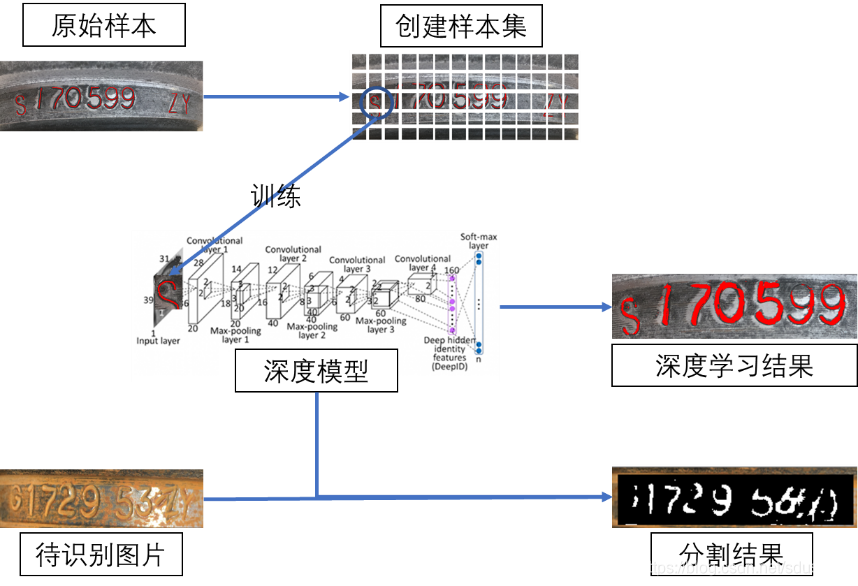
采用深度学习的方法进行训练后,对训练集中比较典型的图片有较高的分割效果。
对测试的新图片效果较差。原因可能是样本少,测试的新图片与样本集中的色差和亮度差异较大。

样本外的图片普遍分割效果较差,究其原因可能有以下几个方面:
1、样本数量较少,训练的不够充分
2、图片整体与样本图片的色差明显,也是与样本少有关系
3、钢印号码本身较不够明显,对比度较差

钢印号码识别
将钢印的号码分别手工切割成小图片作为样本进行训练
有两种方案正在研究:
方案1:根据上一节中分割的钢印位置,进行识别
方案2:直接作为样本进行训练

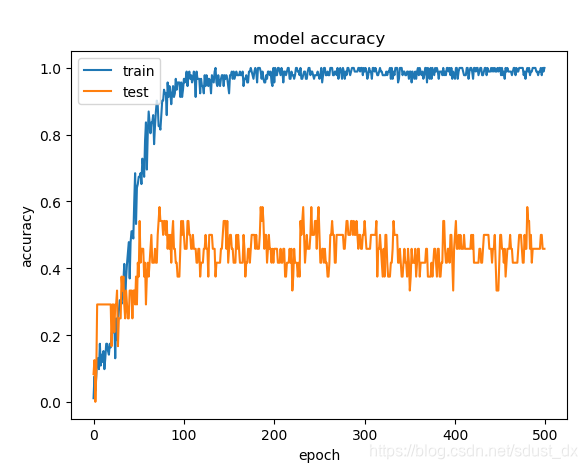
样本集较少,导致训练集效果好,而测试集效果很差。
预期增加样本后训练的效果会有较大的提高。
由于训练结果差,识别未进行
对原始图先进行同态:消除(降低)光照影响(上图为原图,下图为处理后的图像)

改进后的钢印文本分割效果:这样看着就比较有戏了。

写在最后:
实际上经过很多次尝试之后,发现上面的效果都不理想。直到设计了更好的深度学习模型之后,才有了较好的结果。
比如结果是下面这样的:按照这个样子继续训练,就可以出比较好的结果了。


















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









