




 本文介绍了如何在华为手机搭载的鸿蒙系统上,使用AidLux进行车牌检测和识别。通过PC端的模型转换和手机端的代码修改,解决了汉字显示问题,实现了在手机摄像头实时检测车牌并识别车牌号的高准确率效果。
本文介绍了如何在华为手机搭载的鸿蒙系统上,使用AidLux进行车牌检测和识别。通过PC端的模型转换和手机端的代码修改,解决了汉字显示问题,实现了在手机摄像头实时检测车牌并识别车牌号的高准确率效果。
**基于AidLux对车牌检测+识别在华为手机鸿蒙系统上部署**
本文主要描述在手机端用摄像头对实际车辆图片和路边停靠车辆的检测识别效果,代码修改及遇到问题的解决思路。
一、PC上转换运行推理:
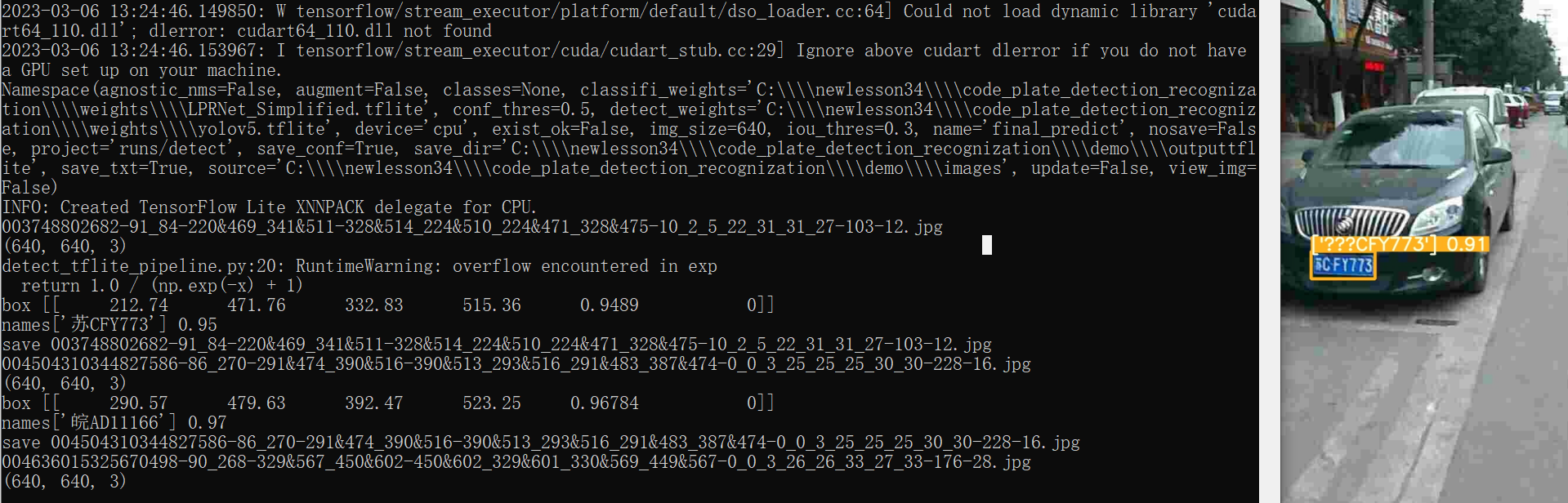
手机端安装好 AidLux,PC端可以选择GPU电脑,这里选择的是没有GPU的笔记本电脑运行如下图(没有GPU的可参考),通过Anaconda安装需要的Pytorch、Tensorflow等环境后,将经过系列转换后的tflite文件进行推理输出信息如下,此时检测的车牌如右侧汉字部分没有显示出来,后面会详细描述如何修改。
二、修改在华为手机端的推理:
主要的变动在于模型的初始化和模型的推理两个方面,需要通过netron打开tflite模型,确定输入和输出size修改模型初始化的部分。
1.车牌检测部分
使用netron打开yolov5.tflite的模型如下:
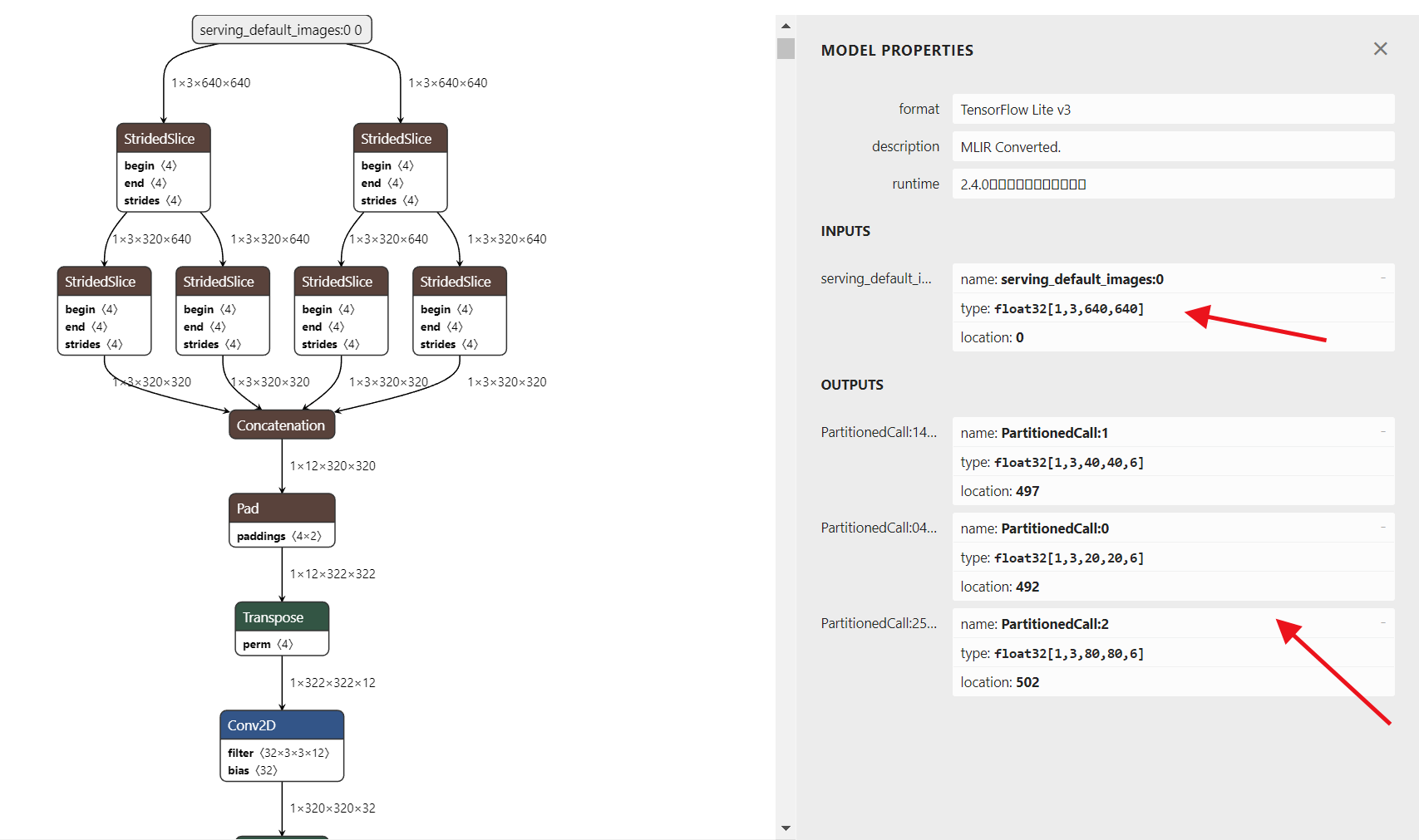
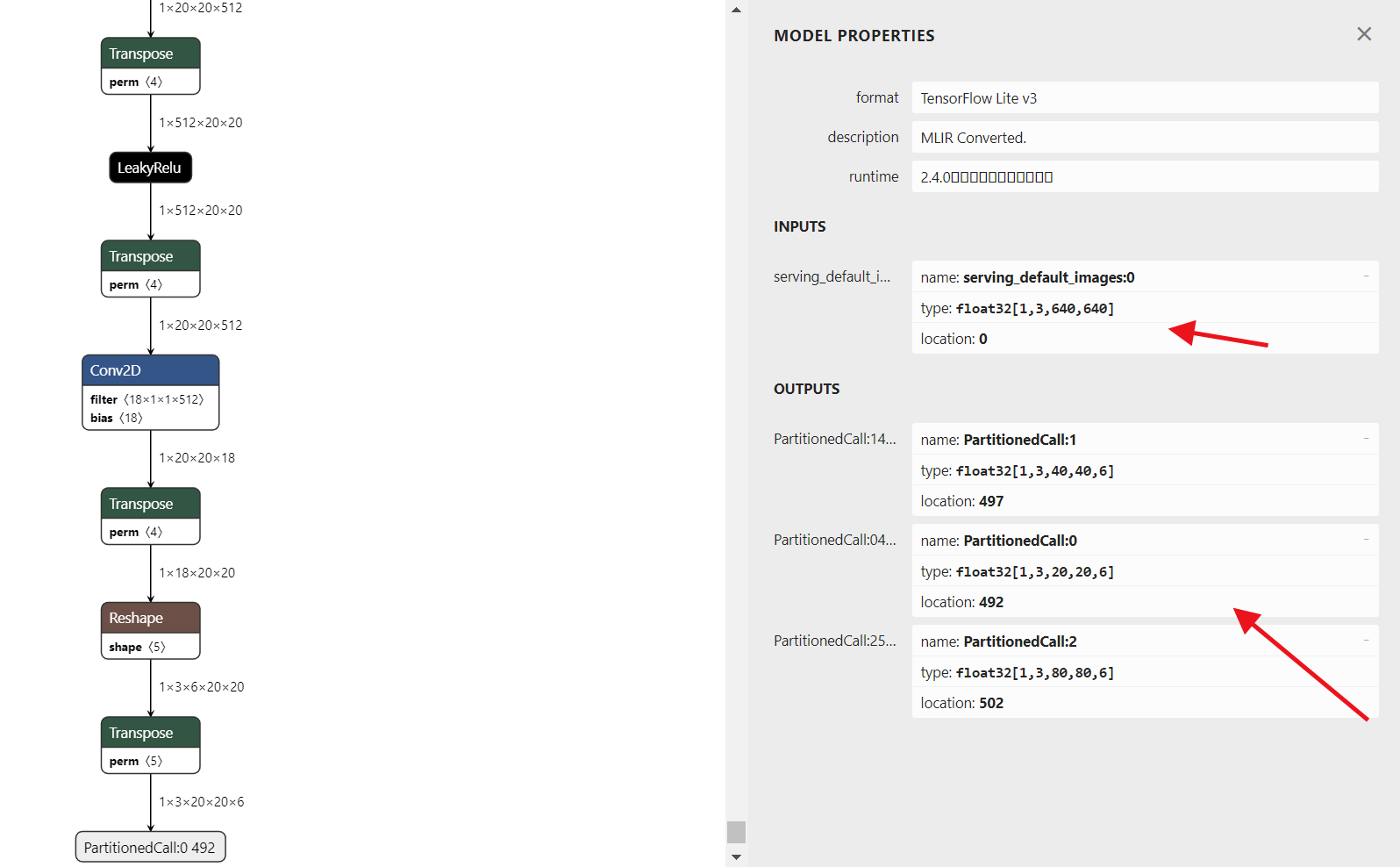
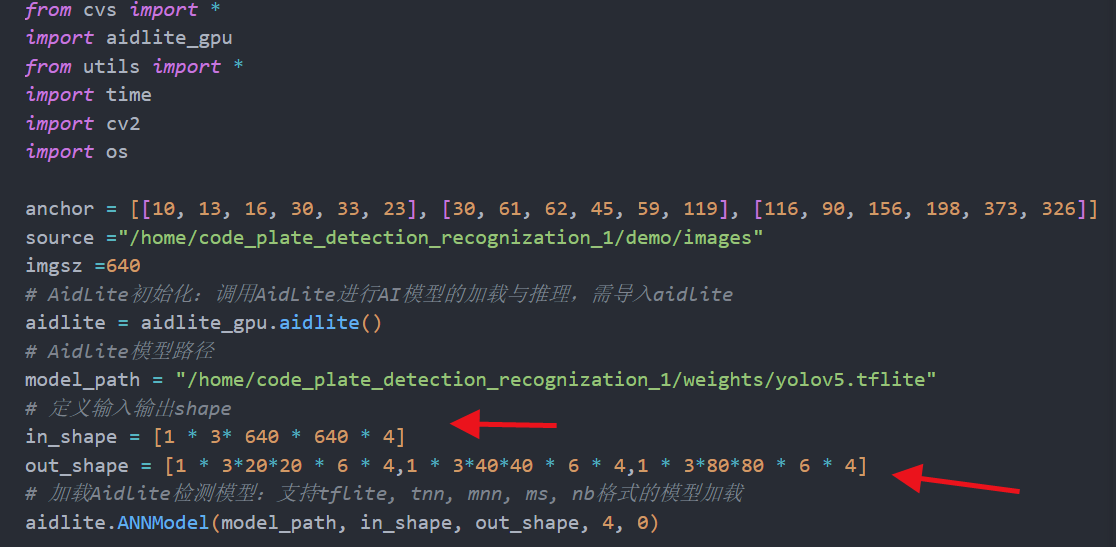
在aidlux文件夹下找到对应脚本的detect部分,修改模型路径,同时in_shape 和out_shape 要与netron中的输入输出保持一致,如下图。
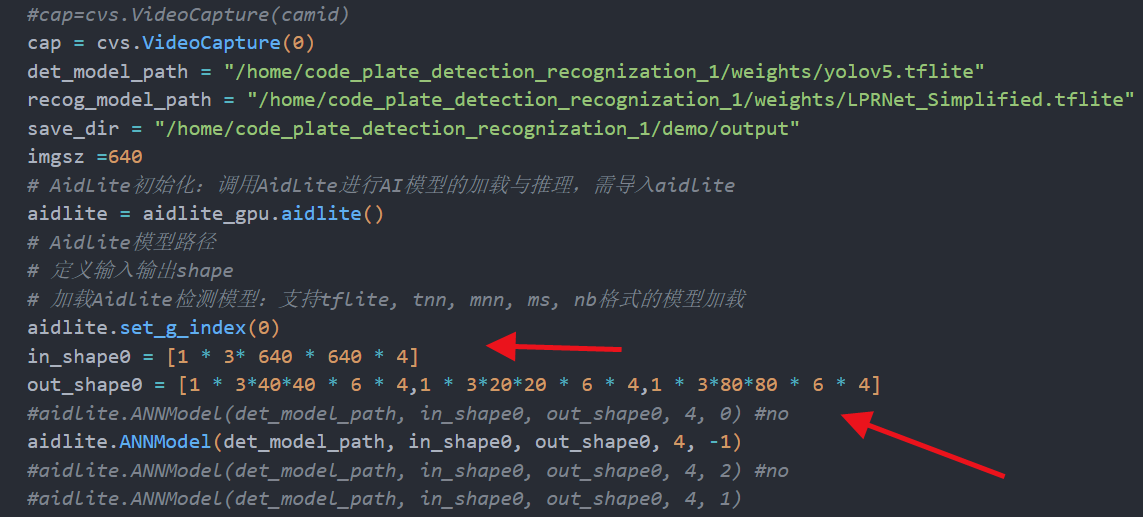
2.车牌识别部分
使用netron打开LPRNet_Simplified.tflite的模型如下:
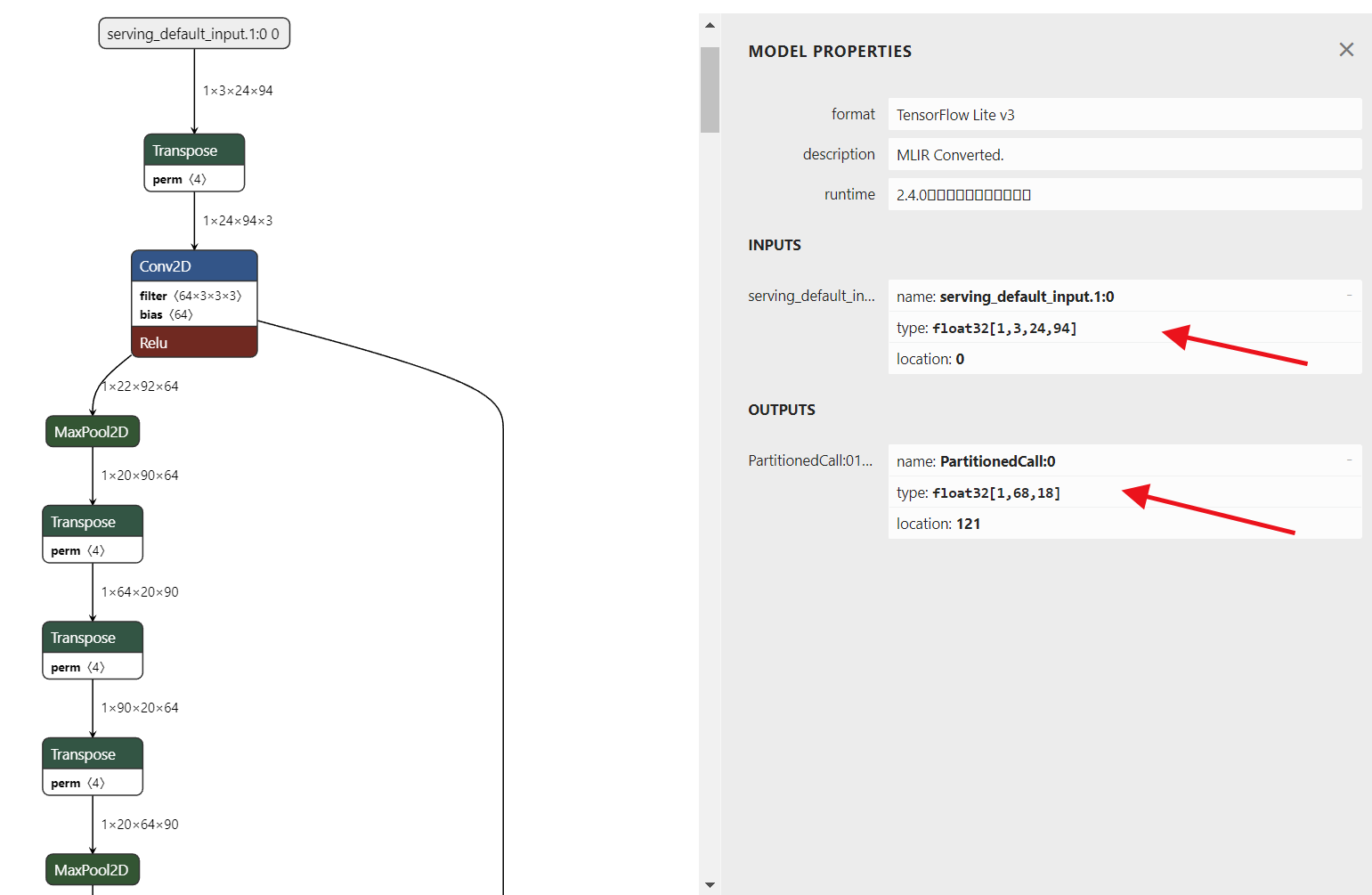
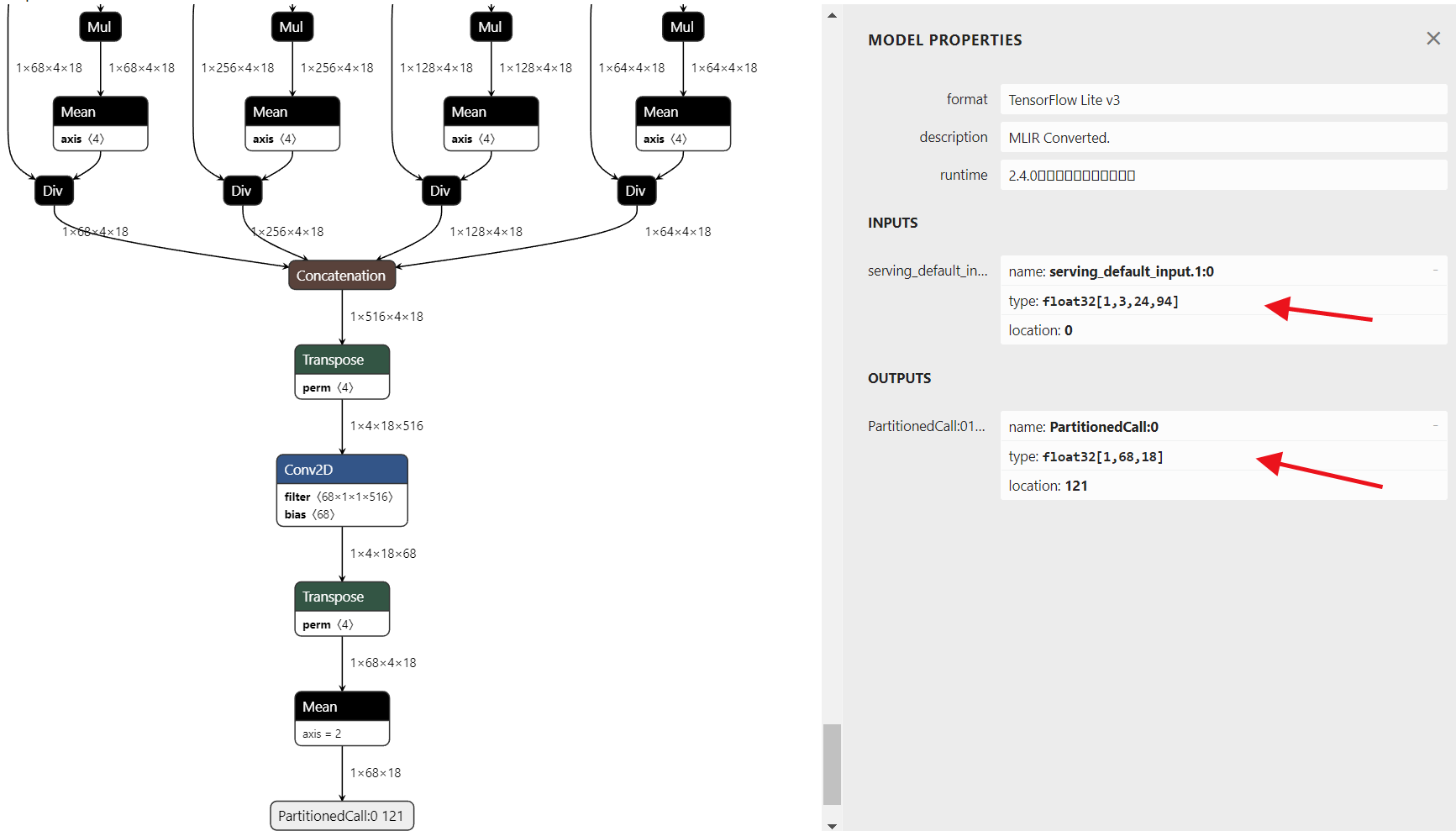</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









