






一.为什么要搭建hadoop环境?
第一,本人对hadoop生态圈有一定的兴趣。第二,leader让我了解的,估计是要让我搞这个了。
二.什么是hadoop生态?
其实如果你不知道hadoop生态和大数据是干什么的,你就不用往下看了。
三.总体流程规划。
1.准备虚拟机
2.下载所需要的一些安装包。
3.相关软件的安装与环境变量的配置(只需先安装在某一台机器上,然后进行虚拟机的拷贝)。
4.编译hadoop源码。
5.安装hadoop
6.虚拟机克隆并对克隆后的虚拟机网卡相关信息进行更正。
7.启动hadoop集群。
8.验证hadoop集群是否启动成功。
接下来,我们就着手一步步干把...
1.虚拟机的安装。
本人使用的是centos6.8,我理解这里最好使用centos,因为后续一些软件的安装比较方便,至于centos的版本我理解不是很要紧,只要不要太高或太低都不会有太大的问题。我也就不在这里赘述了。
在安装虚拟机成功后我们需要做下面几件事情:
1.将防火墙关闭。
service iptables stop//关闭防火墙 chkconfig iptables off//不让防火墙开机自启动
2.关闭selinux,将SELINUX 设置为disable。
vim /etc/selinux/config

3.使用静态ip。
vim /etc/sysconfig/network-scripts/ifcfg-eth0 //修改网卡配置DEVICE="eth0"//设备名称 BOOTPROTO="static"//改为static使用静态ip HWADDR="00:0C:29:78:17:FD" IPV6INIT="yes" NM_CONTROLLED="yes" ONBOOT="yes" TYPE="Ethernet" UUID="435015f8-4cb3-4134-ab45-7b82a29e3eca" IPADDR=172.20.10.10//自定义ip地址 NETMASK=255.255.255.0//子网掩码 GATEWAY=172.20.10.1//网关地址 DNS1=8.8.8.8//dns和我配一样就行了,这个是谷歌的 DNS2=8.8.4.4
- 这里面的有些信息你可能不知道从哪里获取,比如网关地址,子网掩码等。
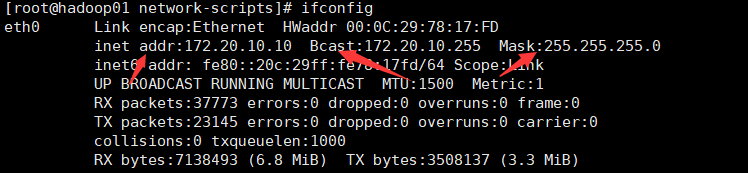
- 你可以在linux界面输入ifconfig出现以下内容能给我们一点信息:
- 可以看出当前ip为172.20.10.10 所以可以得出网关为172.20.10.1(将当前ip的最后变一个点之后变成1就行了) ,后面的Mask就是子网掩码。
- 接下来我们 rm -f /etc/udev/rules.d/70-persistent-net.rules 这是为了清楚以前关于该网卡的缓存记录。
- 最后 输入 reboot 命令重启虚拟机。
4.配置 /etc/hosts文件,完成主机名到ip的映射:
以下是我配置后的示例:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.20.10.10 hadoop01 //前面是每台虚拟机的ip 后面是主机名 172.20.10.11 hadoop02 172.20.10.12 hadoop03
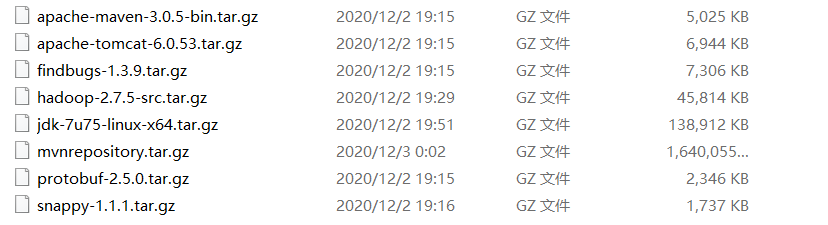
2.相关资源的准备。
一般就以下几个。下方会有相关资源的链接,笑纳!
3.相关软件的安装与环境变量的配置
- 将相关的资料上传到虚拟机上,目录你自己定。
- 将资源解压到指定目录,这个目录以后配置环境变量的时候需要被使用到。
- 配置环境变量。环境变量的配置是一个惊喜的过程每配完一个都测试一下啊。
下面是我配置完后的示意:
#JDK &jdk1.7
export JAVA_HOME=/opt/software/jdk1.7.0_75
export PATH=$JAVA_HOME/bin:$PATH
#maven3.0.5
export MAVEN_HOME=/opt/software/apache-maven-3.0.5
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=$MAVEN_HOME/bin:$PATH
#find bugs 1.3.9
export FIND_BUGS_HOME=/opt/software/findbugs-1.3.9
export PATH=$FIND_BUGS_HOME/bin:$PATH
#hadoop 2.7.5
export HADOOP_HOME=/opt/software/hadoop-2.7.5
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
- 注意,配置完成后记得source 一下配置文件。我是在/etc/profile中配置的。
- 注意,请使用我上面提供的jdk1.7,jdk1.8与hadoop2.7.5有可能出现兼容问题。
- 注意,需要先卸载虚拟机上原有的openjdk,没有的话就不需要卸载了:
-
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 - 注意,安装maven的时候需要指定本地仓库为我们上面提供的本地仓库路径,并且添加一个阿里云的镜像,镜像如下:
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
这样可以使相关依赖jar包的下载速度加快很多。
在线安装一些依赖:
yum install autoconf automake libtool cmake
yum install ncurses-devel
yum install openssl-devel
yum install lzo-devel zlib-devel gcc gcc-c++
yum install -y bzip2-devel安装protobuf
cd /export/servers/protobuf-2.5.0 //进入protobuf解压后存放的目录 ./configure //初始化配置文件 make && make install//编译,安装
安装snappy
cd ../servers/snappy-1.1.1/ ./configure make && make install
4.编译hadoop源码
1.进入hadoop2.7.5目录下依次运行如下命令
cd /export/servers/hadoop-2.7.5 //进入hadoop目录 mvn package -DskipTests -Pdist,native -Dtar -Drequire.snappy -e -X //编译支持snappy压缩2.等待编译完成(编译hadoop源码的时间很长,大概两个小时,这还是在大部分引用都来自本地maven仓库的情况下)。
编译生程的hadoop-2.7.5存放在/hadoop-2.7.5/hadoop-dist/target 中。
下面为大家提供一个已经编译好的hadoop-2.7.5
5.安装hadoop
1.解压重新编译后的hadoop-2.7.5(或者直接使用我上面提供的)
2.修改配置文件,一共是6个,下面我提供一个链接,你跟着里面的配就行了,基本都有注释:
3.创建一些配置文件中指定的目录(注意根据自己hadoop的安装位置来变化):
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2 mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2 mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
6.虚拟机克隆并对克隆后的虚拟机网卡相关信息进行更正
虚拟机克隆我就不说了,我在这里说几个坑点:
1.克隆后的虚拟机的ip和mac地址uuid都需要修改,不然会产生冲突。
mac地址可以关闭虚拟机后再重新生成,记得一定要关闭虚拟机!就是关机!
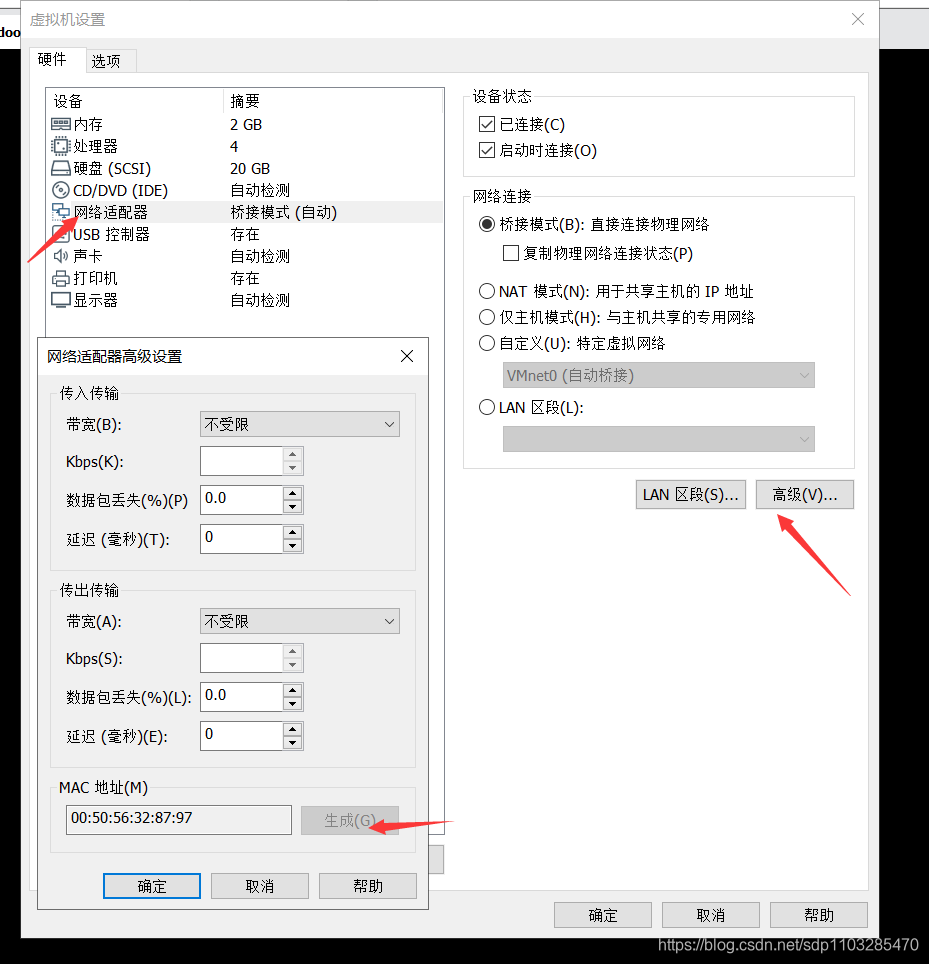
2.清除网卡相关缓存后重启虚拟机
rm -f /etc/udev/rules.d/70-persistent-net.rules //这是为了清楚以前关于该网卡的缓存记录 reboot //重启
7.启动hadoop集群
1.格式化
cd /export/servers/hadoop-2.7.5/ //进入hadoop-2.7.5目录 bin/hdfs namenode -format //对namenode进行格式化,只有第一次启动的时候需要执行,后续不可执行,会导致数据丢失。
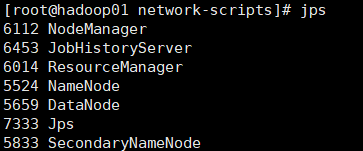
2.启动hadoop集群
sbin/start-dfs.sh //启动文件系统 sbin/start-yarn.sh //启动雅安 sbin/mr-jobhistory-daemon.sh start historyserver //启动任务监控主节点:
从节点:
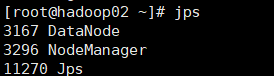
8.验证hadoop集群是否启动成功
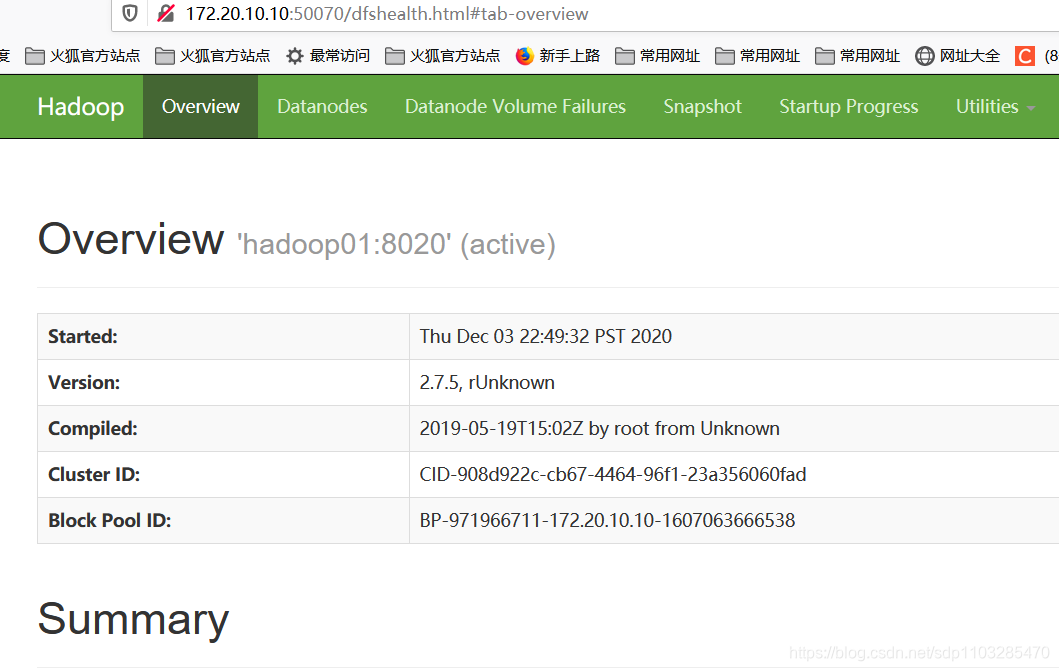
http://node01:50070 查看hdfs
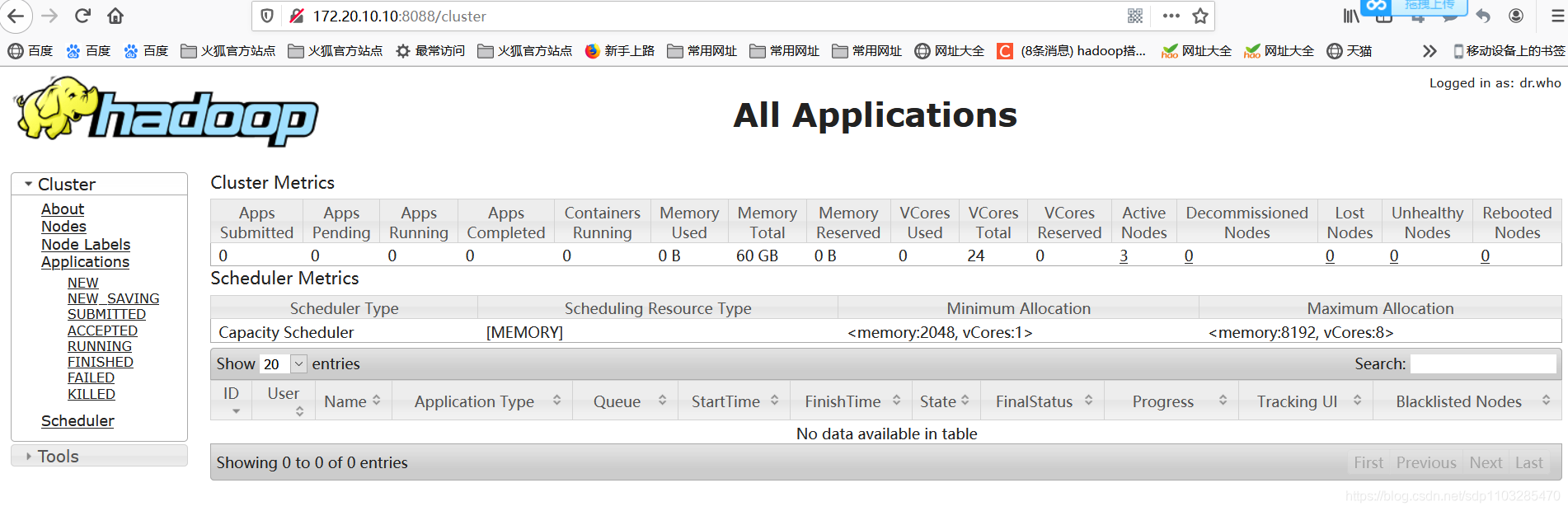
http://node01:8088 查看yarn集群
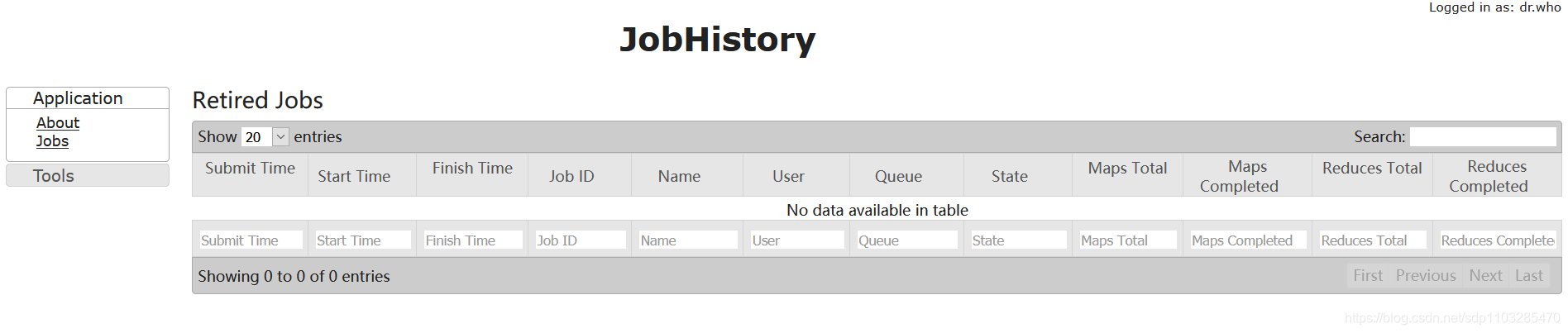
http://node01:19888查看历史完成的任务
注意,node01应该是你的namenode的ip。
如果着三个页面均能访问那就证明你的hadoop集群启动成功了!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









