




OpenCompass介绍
大语言模型(LLM)在理解和生成自然语言文本方面已经取得了显著的进步。随着应用场景的逐渐多样化,利用模型快速写出高质量代码,修复代码 Bug,提升开发效率等需求对大语言模型编程代码的能力提出了新的挑战。
学术社区在代码大模型上发展迅速,如 Code LLaMa,WizardCoder 等在社区获得了广泛关注。那我们该如何进行代码大模型的选型?相信通过全面透明的代码能力评测,你一定可以找到最适合自己需求的代码大模型方案。
评测对象
本算法库的主要评测对象为语言大模型与多模态大模型。我们以语言大模型为例介绍评测的具体模型类型。
基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
工具架构
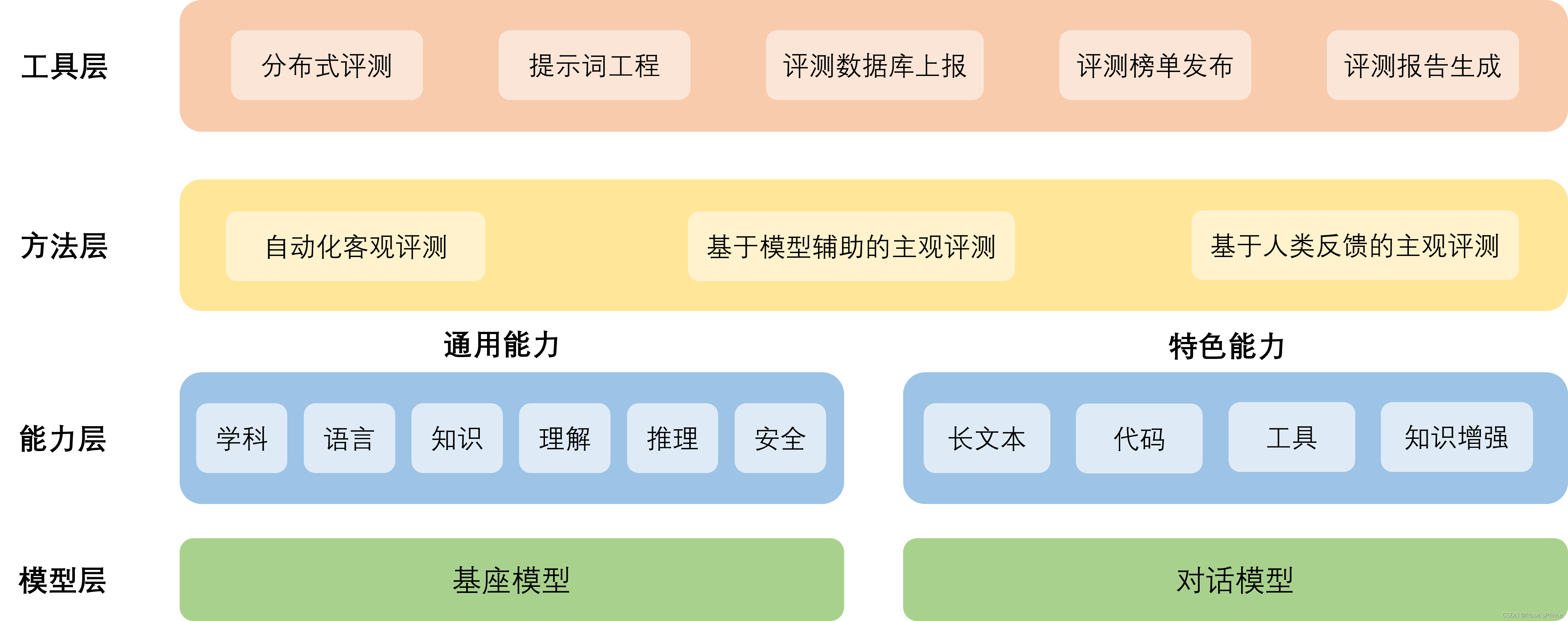
- 模型层:大模型评测所涉及的主要模型种类,OpenCompass以基座模型和对话模型作为重点评测对象。
- 能力层:OpenCompass从本方案从通用能力和特色能力两个方面来进行评测维度设计。在模型通用能力方面,从语言、知识、理解、推理、安全等多个能力维度进行评测。在特色能力方面,从长文本、代码、工具、知识增强等维度进行评测。
- 方法层:OpenCompass采用客观评测与主观评测两种评测方式。客观评测能便捷地评估模型在具有确定答案(如选择,填空,封闭式问答等)的任务上的能力,主观评测能评估用户对模型回复的真实满意度,OpenCompass采用基于模型辅助的主观评测和基于人类反馈的主观评测两种方式。
- 工具层:OpenCompass提供丰富的功能支持自动化地开展大语言模型的高效评测。包括分布式评测技术,提示词工程,对接评测数据库,评测榜单发布,评测报告生成等诸多功能。
能力维度
设计思路
为准确、全面、系统化地评估大语言模型的能力,OpenCompass从通用人工智能的角度出发,结合学术界的前沿进展和工业界的最佳实践,提出一套面向实际应用的模型能力评价体系。OpenCompass能力维度体系涵盖通用能力和特色能力两大部分。
通用能力涵盖学科综合能力、知识能力、语言能力、理解能力、推理能力、安全能力,共计六大维度构造立体全面的模型能力评价体系。
评测方法
OpenCompass采取客观评测与主观评测相结合的方法。针对具有确定性答案的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价。针对体现模型能力的开放式或半开放式的问题、模型安全问题等,采用主客观相结合的评测方式。
客观评测
针对具有标准答案的客观问题,我们可以我们可以通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。同时,由于大语言模型输出自由度较高,在评测阶段,我们需要对其输入和输出作一定的规范和设计,尽可能减少噪声输出在评测阶段的影响,才能对模型的能力有更加完整和客观的评价。
为了更好地激发出模型在题目测试领域的能力,并引导模型按照一定的模板输出答案,OpenCompass采用提示词工程 (prompt engineering)和语境
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









