







给你一个字符串 s 和一个整数 t,表示要执行的 转换 次数。每次 转换 需要根据以下规则替换字符串 s 中的每个字符:
- 如果字符是
'z',则将其替换为字符串"ab"。 - 否则,将其替换为字母表中的下一个字符。例如,
'a'替换为'b','b'替换为'c',依此类推。
返回 恰好 执行 t 次转换后得到的字符串的 长度。
由于答案可能非常大,返回其对 10^9 + 7 取余的结果。
示例 1:
输入: s = "abcyy", t = 2
输出: 7
解释:
- 第一次转换 (t = 1)
'a'变为'b''b'变为'c''c'变为'd''y'变为'z''y'变为'z'- 第一次转换后的字符串为:
"bcdzz"
- 第二次转换 (t = 2)
'b'变为'c''c'变为'd''d'变为'e''z'变为"ab"'z'变为"ab"- 第二次转换后的字符串为:
"cdeabab"
- 最终字符串长度:字符串为
"cdeabab",长度为 7 个字符。
示例 2:
输入: s = "azbk", t = 1
输出: 5
解释:
- 第一次转换 (t = 1)
'a'变为'b''z'变为"ab"'b'变为'c''k'变为'l'- 第一次转换后的字符串为:
"babcl"
- 最终字符串长度:字符串为
"babcl",长度为 5 个字符。
提示:
1 <= s.length <= 10^5s仅由小写英文字母组成。1 <= t <= 10^5
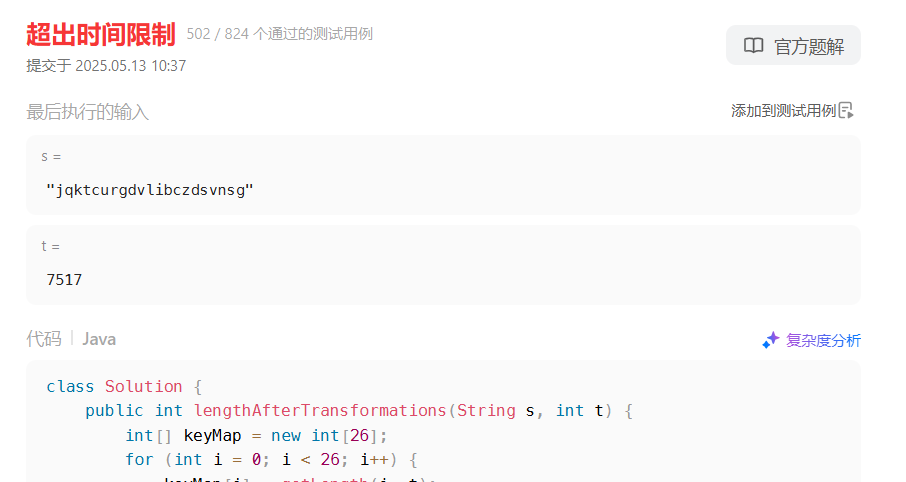
第一次解题思路:因为题目限定了字符串的范围a~z,就26个小写的英文字母,所以想能不能先求得每个字母进行t次转换后的字符串长度。如果能得到的话,就只需要再遍历一遍s的字符,将每个字符t次转换后的长度累加一下就可以了。
而要求得f(x,y)(x为字符,y为进行转换的次数),首先想到的是用递归来解(暴力解法)
class Solution {
//递归查找,效能极差,leetCode超时了
public int lengthAfterTransformations(String s, int t) {
int[] keyMap = new int[26];
for (int i = 0; i < 26; i++) {
keyMap[i] = getLength(i, t);
}
int total = 0;
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
total += keyMap[(int) chars[i] - 97] % (1e9 + 7);
}
return total;
}
/**
* 求得字符x经过y次转换后的位数
* @param x
* @param y
* @return
*/
public int getLength(int x, int y) {
if (x + y < 26) {
return 1;
}
return getLength(0, x + y - 26) + getLength(1, x + y - 26);
}
}逻辑上好像没啥问题,但是效能比较差,跑到500多个用例的时候就超时了
看了下评论区,第一次题解的大体思路可以用,但是要用到一个动态规划的思想
动态规划(Dynamic Programming,DP)基本思想
动态规划算法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解。每一个解都对应于一个值,我们希望找到具有最优值的解。动态规划算法与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。若用分治法来解这类问题,则分解得到的子问题数目太多,有些子问题被重复计算了很多次。如果能够保存已解决的子问题的答案,而在需要时再找出已求得的答案,这样就可以避免大量的重复计算,节省时间。我们可以用一个表来记录所有已解的子问题的答案。不管该子问题以后是否被用到,只要它被计算过,就将其结果填入表中。这就是动态规划法的基本思路。具体的动态规划算法多种多样,但它们具有相同的填表格式
可以 将每次计算的结果存储起来,这样一来后续的计算可以直接使用之前计算的结果,避免大量的重复计算。
附上评论区大佬的解法,采用二维数组存储了a~z 26个字符,经历t次转换后的字符长度,且每一步的计算依赖上一步的计算结果,不会造成重复计算的场景,大大提示了效率
class Solution {
private static final int MOD = (int) (1e9 + 7);
private static final int MAX_T = (int) 1e5; // 题目给定的 t 的最大范围
private static final int MX = 26; // 字母表大小(a-z)
private static final long[][] dp = new long[MX][MAX_T + 1];
// 静态初始化块,在类加载时执行预处理
static {
// 初始化:t=0 时,每个字符的长度都是 1
for (int ch = 0; ch < MX; ch++) {
dp[ch][0] = 1; // 还未转换时,只有自己
}
// 动态规划预处理
for (int t = 1; t <= MAX_T; t++) {
for (int ch = 0; ch < MX; ch++) {
if (ch == 25) {
// 如果当前字符是 'z',则替换为 'a' 和 'b',长度变为两者之和
dp[ch][t] = (dp[0][t - 1] + dp[1][t - 1]) % MOD;
} else {
// 其他字符替换为下一个字符
dp[ch][t] = dp[ch + 1][t - 1];
}
}
}
}
public int lengthAfterTransformations(String s, int t) {
long res = 0;
for (char c : s.toCharArray()) {
int ch = c - 'a'; // 将字符转换为 0-25 的索引
res = (res + dp[ch][t]) % MOD;
}
return (int) res;
}
}
作者:wxyz
链接:https://leetcode.cn/problems/total-characters-in-string-after-transformations-i/solutions/3675715/si-jie-bao-li-chang-gui-dp-kong-jian-you-3m0v/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。最后附上官方的题解,本质上与上面评论区的题解思路差不多,只是初始值数组是用的字符串s每个字符出现的次数
class Solution {
private static final int MOD = 1000000007;
public int lengthAfterTransformations(String s, int t) {
int[] cnt = new int[26];
for (char ch : s.toCharArray()) {
++cnt[ch - 'a'];
}
for (int round = 0; round < t; ++round) {
int[] nxt = new int[26];
nxt[0] = cnt[25];
nxt[1] = (cnt[25] + cnt[0]) % MOD;
for (int i = 2; i < 26; ++i) {
nxt[i] = cnt[i - 1];
}
cnt = nxt;
}
int ans = 0;
for (int i = 0; i < 26; ++i) {
ans = (ans + cnt[i]) % MOD;
}
return ans;
}
}
作者:力扣官方题解
链接:https://leetcode.cn/problems/total-characters-in-string-after-transformations-i/solutions/3674706/zi-fu-chuan-zhuan-huan-hou-de-chang-du-i-rw3x/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











