









 本文介绍了如何通过PreparedStatement的addBatch和事务管理优化数据库插入性能,对比了逐条插入和批量插入的效率提升,展示了在Java中利用批处理和事务来加速20000条数据插入的过程。
本文介绍了如何通过PreparedStatement的addBatch和事务管理优化数据库插入性能,对比了逐条插入和批量插入的效率提升,展示了在Java中利用批处理和事务来加速20000条数据插入的过程。
- 使用
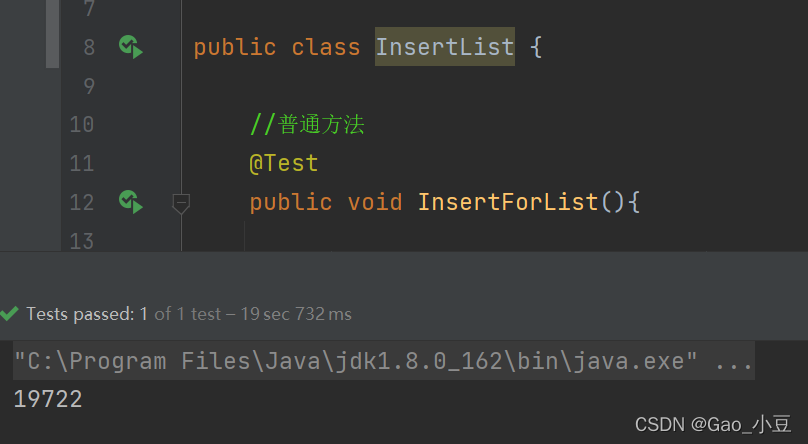
PreparedStatement实现批量插入的普通方法:
@Test
public void InsertForList(){
Connection conn = null;
PreparedStatement ps = null;
long start = System.currentTimeMillis();
try {
conn = DBUtil.connection();
String sql = "insert into goods values (?)";
ps=conn.prepareStatement(sql);
for (int i=0;i<20000;i++){
ps.setString(1,"name"+i);
ps.executeUpdate();
}
long end = System.currentTimeMillis();
System.out.println(end-start);
} catch (Exception e) {
e.printStackTrace();
}finally {
DBUtil.close(conn,ps);
}
}
缺点是一条一条插入,需要的时间很长。
插入两万条数据:时间 19722
2. 优化 ------- 使用 addBatch 实现批量插入。
addBatch(String): 添加需要批量处理的SQL语句或是参数;
executeBatch(): 执行批量处理语句;
clearBatch(): 清空缓存的数据
但是要把属性文件中的 url 修改。 后面添加?rewriteBatchedStatements=true
url=jdbc:mysql://localhost:3306/mytest1?rewriteBatchedStatements=true
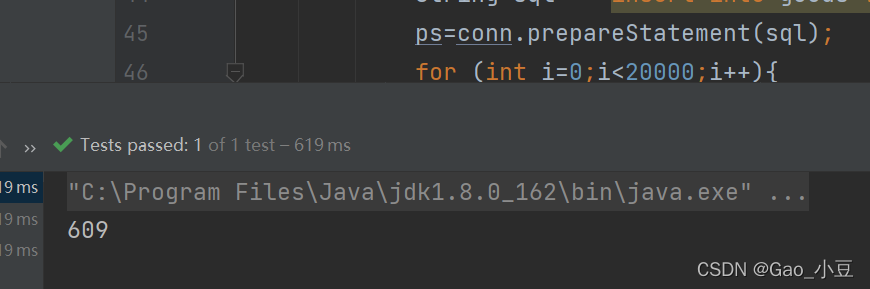
具体代码实现:
@Test
public void InsertForList01(){
Connection conn = null;
PreparedStatement ps = null;
long start = System.currentTimeMillis();
try {
conn = DBUtil.connection();
String sql = "insert into goods values (?)";
ps=conn.prepareStatement(sql);
for (int i=0;i<20000;i++){
ps.setString(1,"name"+i);
//攒sql
ps.addBatch();
if(i%500==0){
ps.executeBatch();
}
ps.clearBatch();
}
long end = System.currentTimeMillis();
System.out.println(end-start);
} catch (Exception e) {
e.printStackTrace();
}finally {
DBUtil.close(conn,ps);
}
}
插入两万条数据时间: 609 很大提升
3、通过事务机制控制提交,进一步优化
conn.setAutoCommit(false);
执行完所有操作以后:
conn.commit();
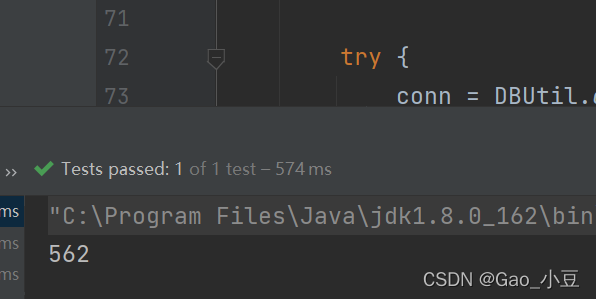
@Test
public void InsertForList02(){
Connection conn = null;
PreparedStatement ps = null;
long start = System.currentTimeMillis();
try {
conn = DBUtil.connection();
String sql = "insert into goods values (?)";
//设置 不让其自动提交
conn.setAutoCommit(false);
ps=conn.prepareStatement(sql);
for (int i=0;i<20000;i++){
ps.setString(1,"name"+i);
//攒sql
ps.addBatch();
if(i%500==0){
ps.executeUpdate();
}
ps.clearBatch();
}
long end = System.currentTimeMillis();
System.out.println(end-start);
conn.commit();
} catch (Exception e) {
e.printStackTrace();
}finally {
DBUtil.close(conn,ps);
}
}
插入两万条数据时间 562 (针对数据更多的效果更有效)

















 2430
2430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









