




专题1:ANN和KNN的对比
K-Nearest Neighbor (KNN):
-
定义: KNN是一种通用的分类与回归分析的算法,它在向量检索中的作用是,通过计算样本之间的欧氏距离来找出k个最近的样本。
-
算法特性:
-
精度:由于它是基于实际距离计算的,所以结果是精确的。
-
时间复杂度:高,寻找最近邻需要对所有样本进行距离计算,时间复杂度为O(n)。
-
空间复杂度:低,通常只存储样本数据。
-
-
适用场景:
-
数据量较小。
-
精度要求非常高的场景。
-
Approximate Nearest Neighbor (ANN):
-
定义: ANN是一种近似算法,用于加速高维空间近邻查询。它通过一些近似方法来避免对所有数据点进行精确距离计算,因此显著提高了检索速度。
-
算法特性:
-
精度:由于是近似方法,可能结果不是绝对精确的,但一般精度可以保证在可接受范围内。
-
时间复杂度:低,通过近似计算和加速结构(如IVF、LSH、VP-Tree、HNSW等)可以大大减少计算量。
-
空间复杂度:通常较高,因为需要额外的信息来加快索引和查询过程。
-
-
适用场景:
-
数据量大(大规模向量数据集)。
-
对实时性能要求高的场景(如实时推荐、搜索等)。
-
可以接受近似答案的场景。
-
专题2:IVF原理
Step1:分割区域
该算法的核心思想是创建每一个数据集点所属的不相交区域. 每一个区域都有自己的质心, 指向该区域的中心.
有时Voronoi(沃罗诺伊, 中文发音)区域(region)也被称为单元(cell)或者分区/划分(partitions)

Step2:选择TOPk
当给定一个query的时候, 计算它到所有Voronoi分区质心的距离. 然后选择距离最小的质心, 并将该分区中包含的向量作为候选向量.
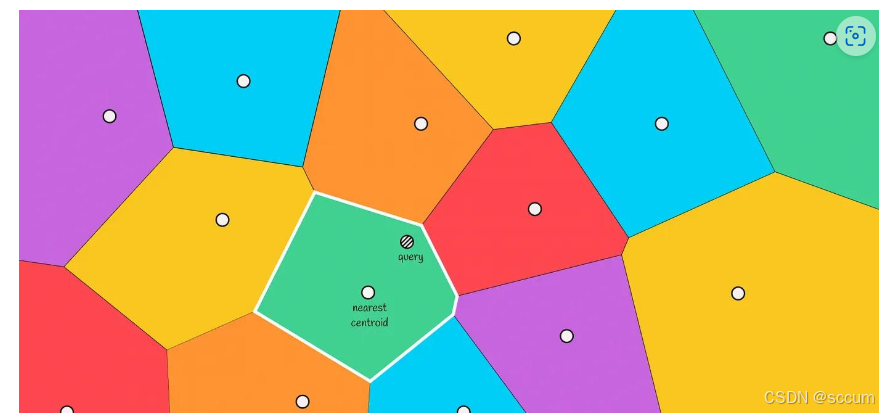
最终, 通过计算query到所有候选向量的距离并选择其中最接近的前$k$个, 作为结果返回.
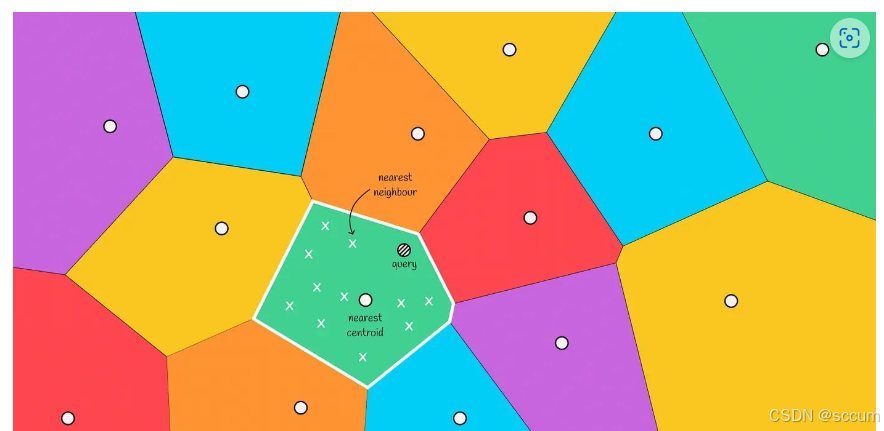
Step3:边缘问题
随着搜索速度的提升, 倒排文件也会有一个缺点: 无法保证找到的对象始终是最近邻.
在下图中, 我们可以看到, 实际的最近邻在红色区域, 但是我们仅仅从绿色区域中选择候选者, 这种情况就是边缘问题
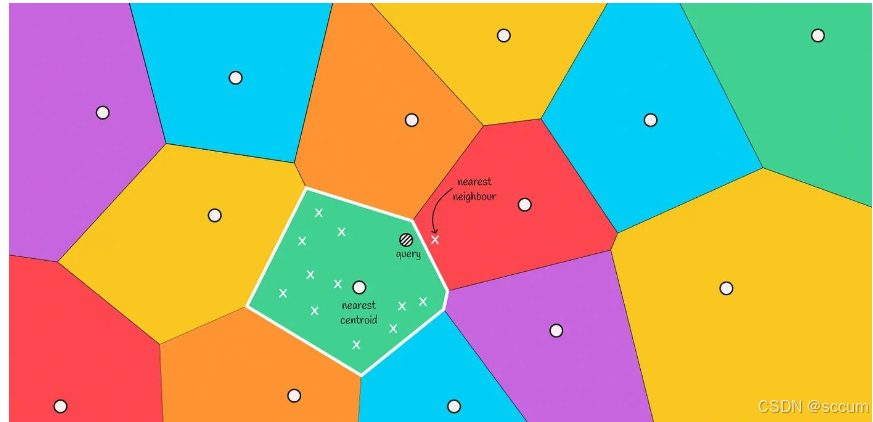
当查询对象位于与另一个区域的边界附近时, 通常会发生这种情况. 为了减少这种情况下的错误数量, 我们可以扩大搜索范围, 并根据与query最接近的前m个质心选择候选区域即可
专题3:HNSW原理
HNSW全称Hierarchical NSW,NSW是Navigable Small World,即“可导航小世界网络”算法。
何为小世界网络?现实世界中,处处都是小世界网络。比如A跟B是微信好友,B跟C是微信好友,但A跟C不是,但是A跟C可以通过B建立起连接。也就是说,世界上任何事物都可以通过间接的途径建立起连接。
https://zhuanlan.zhihu.com/p/379372268
专题3:评价指标
3.1 Hit Rate
计算公式:

假设有5个查询,每个查询的相关文档按如下方式分布(假设相关文档标记为1,非相关文档标记为0):
-
查询1: [0, 1, 0, 0, 0]
-
查询2: [1, 0, 0, 0, 0]
-
查询3: [0, 0, 0, 0, 0]
-
查询4: [0, 0, 0, 1, 0]
-
查询5: [0, 0, 1, 0, 0]
计算Hit Rate@3,表示在前3个检索结果中是否有相关文档:
-
查询1: 前3个结果 [0, 1, 0],包含1(相关文档),所以命中。
-
查询2: 前3个结果 [1, 0, 0],包含1(相关文档),所以命中。
-
查询3: 前3个结果 [0, 0, 0],不包含相关文档,所以未命中。
-
查询4: 前3个结果 [0, 0, 0],不包含相关文档,所以未命中。
-
查询5: 前3个结果 [0, 0, 1],包含1(相关文档),所以命中。
Hit Rate@3 = (3/5) = 0.6 或 60%。
3.2 召回率

3.3 精确率

3.4 F1-score


















 4727
4727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









