 Java并发编程的性能优化探究
Java并发编程的性能优化探究




关于性能优化的一些基本概念
性能与可伸缩性的关联
对于性能的提升我们更多是需要去抓住问题的本质,而优化的根本目的就是在有限的资源限定下,用尽可能少的资源做尽可能多的事情,而这里的资源通常的指代下面这些计算机资源:
- CPU时钟周期
- 网络带宽
- IO带宽
- 数据库资源
- 计算机内存
- 磁盘空间
- ......
当程序吞吐量受到这些资源的限制而进入瓶颈时,我们通常称这些任务是资源密集型阻塞,例如:
- 某个线程长时间得不到CPU执行就是CPU密集型
- 文件读取操作因为IO wait时间过长导致阻塞也就是IO密集型
所以在进行性能排查的时候,我们更多要做就是通过观察服务器上各项指标明确任务的类型才能进行更近一步的优化。不能意味的当性能下降的时候就去盲目的增加线程数。因为引入多线程的同时会引入如下开销:
- 上下文切换开销
- 线程创建与销毁
- 资源同步协调
- 线程调度
按照并发编程性能的哲学,要做到性能的优化要求我们尽快的利用到现有的资源,让其时刻保持忙碌(例如CPU时钟周期做有意义的事情,而不是忙于上下文切换)
例如我们有这样一批并发任务,计算时间占用50ms,而io耗时为150毫秒,按照优化方法论,我们应该设定合适的线程数保证每个线程完成运算后进入IO状态就立刻挂起切换下一个线程执行CPU运算任务,保证尽可能的平衡稳定的运算任务并榨取CPU性能。
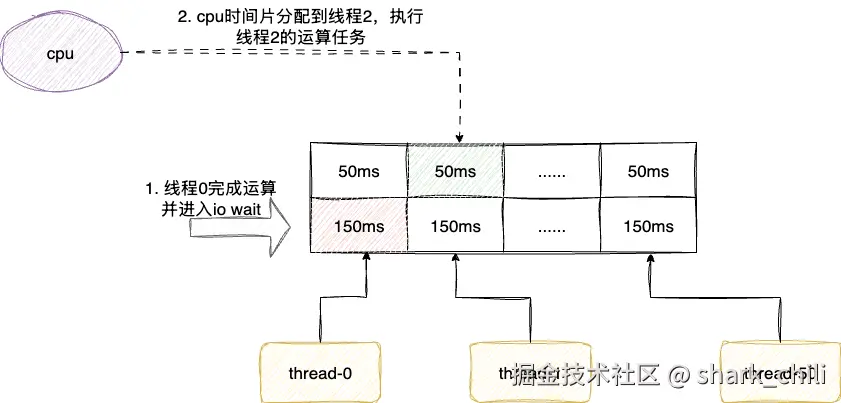
java-concurrency-optimization.drawio
可伸缩性
可伸缩性的概念,即增加计算机资源后,应用程序执行能力亦或者说吞吐量会相应的提高,而这些资源通常指代:
- 计算机内存
- 网络带宽
- 磁盘IO带宽(例如硬盘和SSD磁盘)
- CPU
在性能优化涉及多快和多少我们必须要理解,这是两个概念,有时候这两者是矛盾的,即为了提升资源利用率,我们可能会将一个任务分为无数个子任务在多核CPU中处理,但是性能却不一定提升,例如下面这段简单的运算代码单线程只需要跑2ms,对应多线程并发争抢CPU时间片之后,耗时变为88ms:
long begin = System.currentTimeMillis(); int sum = 0; for (int i = 0; i < 100_0000; i++) { sum ++; } long end = System.currentTimeMillis(); Console.log("sum:{} 耗时:{}", sum, end - begin); AtomicInteger count = new AtomicInteger(0); begin = System.currentTimeMillis(); IntStream.range(0, 100_0000).parallel().forEach(i -> count.incrementAndGet()); end = System.currentTimeMillis(); Console.log("count:{} 耗时:{}", count.get(), end - begin);
亦或者我们通过程序上的优化提高单线程性能的性能表现,即该线程已经尽可能的利用所有限定以内的资源做到尽可能的提高,而这往往会破坏可伸缩性,即资源增加了性能也不会有多少提升。例如我们希望在应用中实现一个懒加载且线程安全的单例模式,一般人可能会想到利用synchronized实现一个DCL双重锁校验的单例模式:
public class SingleObj { private volatile static Object object; public static Object getInstance() { if (object == null) { synchronized (SingleObj.class) { if (object == null) { object = new Object(); } } } return object; } }
实际上,在JVM类加载的特性下,我们完全可以利用static和final关键字保证安全发布的同时,实现只有在线程加载该类的时候再去创建这个静态对象,利用final关键字保证不可变性从而做到线程安全:
public class SafeSingleObj { private static final Object object; static { object = new Object(); } public static Object getInstance() { return object; } }
对应的笔者这里也给出压测代码,感兴趣的读者可以试一下,后者仅仅是利用单线程技术,尽可能的让所有线程尽可能跑满CPU进一步的提升了单例模式的表现,这就是典型单线程层面的优化,破坏了可伸缩性的典型:
long begin = System.currentTimeMillis(); IntStream.range(0, 100_0000).parallel().forEach(i -> { Object instance =SingleObj.getInstance(); if (instance == null) { throw new RuntimeException("单例对象为空"); } }); long end = System.currentTimeMillis(); Console.log("耗时:{}ms", end - begin); begin = System.currentTimeMillis(); IntStream.range(0, 100_0000).parallel().forEach(i -> { Object instance = SafeSingleObj.getInstance(); if (instance == null) { throw new RuntimeException("单例对象为空"); } }); end = System.currentTimeMillis(); Console.log("耗时:{}ms", end - begin);
同理按照现代的分布式架构,一个原本单体的应用程序因为分层或者某些原因分布到不同的机器上,虽然资源利用率提升,但是性能(例如分布式事务问题)却可能会下降,因为它们之间的调度涉及了网络通信以及同步等开销。
性能指标评估标准
性能优化的决策大部分是需要理性的分析思考,要以基准测试为主,不要盲目的去评估,必须有个绝对的标准才能进行评估,例如在小规模的数据排序下,冒泡就是优于快速排序。整体来说,针对性能评估的标准应该是:
- 最差时间
- 平均耗时
- 可预知性(处理时间范围是否波动可控)
总的来说性能优化必须是要有具体标准和场景进行分析才能决策,即程序不要过早的优化,而是先正确的跑起来,然后在必要时再去提升它的速度。毕竟性能优化这件事还有额外的维护负担和测试回归成本,通过优化架构或者设计都会使得程序的复杂度增加,使得整体变得晦涩难懂。
Amadhl定律
什么是Amadhl
有些问题确实是增加更多的资源,执行的速度理论上也就会越快,这也就是著名的Amadhl定律,其理论的对应公式如下,对应语义为:
- F是程序的串行执行部分
- N是处理器个数
对应的公式如下:

image-20250808004057139
基于这个公式,我们假设如下3个场景来印证串行时间对于加速比的限制:
先来说说第一个场景,我们的串行占用50%,假设我们的处理器资源无限大,使得右边的分数几乎趋近于0,这也就意味着一个方法串行时间与并行时间五五开的情况下,加速比最多只有2也就是最多提升2倍。假设我们现在有一个CPU,对应100个线程,这两个线程并行时间和串行时间都500ms也就是上文所说的五五开,试想当前的计算过程:
- 线程0先拿到cpu完成串行和并行(因为当前只有一个cpu,做不到并行)
- 其他线程按照顺序去完成各自的任务
- 线程1同理执行,最终耗时100
此时我们在增加一个处理器,变为两个处理器,对应的计算过程为:
- 线程0和线程1同时执行并行部分,总共耗时500ms
- 线程0先执行串行部分耗时500ms
- 线程1后执行串行部分,再耗时500ms
- 同理单位时间内总有两个线程并行执行,所以并行部分总耗时25000ms
- 串行部分就是100*500ms也就是50000ms
- 最终耗时变为75s,加速比为100/75大约是1.3
基于阿姆达尔定律,我们将处理器提升至100,按照上述的公式计算得并行时间为500ms,串行时间为50s,最终是50.5s换算一下加速比也是无限趋近于2,也符合阿姆达尔定律的说明。
了解阿姆达尔定律的理念之后,我们再来一个场景,假设处理器为10,串行占用时间为10%,对应的加速比差不多是5%左右,对应的计算公式为:
加速比 <= 1/(0.1+(1-0.1)/10) <= 1/0.19 <= 5.3
提升至100个处理器最高使用率也只能达到9%的使用率左右,由此我们也可以知晓,性能瓶颈除了计算资源以外,还有串行时间的耗时,如果能够尽可能得去缩小串行部分耗时,程序的性能表现也会有所提升,就例如下面这段队列获取任务执行的代码段,它的串行时间的瓶颈,就在于多线程并发的访问容器的同步阻塞的开销,此类问题的优化工作,我们也需要更多的去这种同步、加锁等方式的阻塞代码段:
public class WorkThread implements Runnable { private final BlockingQueue<Runnable> queue; public WorkThread(BlockingQueue<Runnable> queue) { this.queue = queue; } @SneakyThrows @Override public void run() { while (true) { //多线程并发访问阻塞队列,这块就是串行部分的性能瓶颈 Runnable task = queue.take(); task.run(); } } }
Amadhl定律对于并发优化的哲学
基于Amadhl定律的思想,本质上优化并发算法时,在资源限定的情况下,我们更多去去强调降低串行时间,说的更具体一点就是降低java内置锁的粒度:
第一种方式为锁分解,将一个锁分为两个锁,针对职责工作进行分离,针对不同的锁采用不同的策略,例如读写锁,针对读请求不修改的场景,这种方式能够最大化多线程读取临界资源的效率:

java-concurrency-optimization-2.drawio
另一种则是锁分段,将一个锁分解为多个锁段,将多线程相同操作的竞争锁的场景,让线程按照指定算法去获取不同的锁,分散竞争的压力:

java-concurrency-optimization-3.drawio
这也是目前并发编程锁优化最常见的几种优化策略,读者可以了解一下这一块的思想,笔者会在后文中给出详尽的解析。
多线程的瓶颈
上下文切换
先来说说线程上下文切换,从操作系统来说线程调度切换时,CPU是需要保存线程上文信息将其存入寄存器然后才能挂起的,这使得线程上下文切换就存在如下几个开销点:
- 频繁上下文切换,CPU时钟周期都用于切换,而线程运算任务
- 频繁切换导致CPU缓存失效导致局部性原理的优势丢失,导致执行效率降低
以Unix系统为例,一般来说线程上下文的开通过vmstat指令进行查看,如果报告线程上下文切换开销大于10%就表示调度活动频繁了。
以笔者的系统为例,可以看到cs为1,上下文切换开销就不算大:
procs -----------memory---------- ---swap-- -----io---- -system-- -------cpu------- r b swpd free buff cache si so bi bo in cs us sy id wa st gu 0 0 0 6914216 19216 425612 0 0 3371 404 224 1 1 1 98 0 0 0
内存同步语义的危害
为了保证并发可见性,JVM要求指令指令不会重排序,它会在JIT编译器甚至CPU处理器上插入内存屏障解决问题,这使得很多JIT优化都失效。尽管JVM也针对不合理的并发采用了一些手段进行辅助优化,也就是逃逸分析等,但我们建议不涉及同步的代码逻辑尽可能的去避免使用一些并发关键字或者并发工具。
同步阻塞
针对同步块阻塞我们可以结合场景选用自旋锁或者阻塞挂起线程锁,对应的应用场景要求也很简单:
- 如果上锁处理很快且等待时间很短,用自旋等待锁原地自选一会,常见的工具也就是juc包下的原子类,例如AtomicInteger
- 如果并发竞争激烈,自旋锁导致CPU时间片因为各种非必要的自旋等待运算而浪费,这种情况下,我们也更推荐直接使用java内置监视锁,也就是synchronized关键字
当然这以上都是一些比较感性的说法,按照jdk8的优化,synchronized关键字已经有了锁升级的概念,它会根据当前线程的竞争激烈程度依次自动的完成如下的锁升级:
- 无锁
- 偏向锁
- 轻量级锁也就是自旋锁
- 重量级锁也就是涉及内核态调用的操作系统级别的mutex锁
关于逃逸分析和synchronized锁升级的概念,感兴趣的读者可以移步笔者这两篇文章:
逃逸分析在Java中的应用与优化:mp.weixin.qq.com/s/0flB6Hlqo…
深入解析Java中的synchronized 关键字:mp.weixin.qq.com/s/rMvpMSrfU…
减少锁竞争
关于锁的一些优化论
在并发编程中,锁的同步是耗时的重要优化点,对于可伸缩性而言最主要的威胁本质上就是独占锁的资源锁,而判断并发竞争激烈的程度的条件有:
- 独占锁的请求频率
- 每次持有锁的时间
如果二者的乘积很小,那么这个程序的并发竞争就相对激烈,反之亦然。按照并发哲学来说,针对锁的优化有三种方式:
- 减小持有锁的时间(减小锁的范围)
- 降低锁的请求频率(减小锁的管控粒度)
- 采用带有协调性质的独占锁,提升程序的并发度
缩小锁的范围
这里我们先来介绍一个比较基础的优化点,在并发程序中的优化,锁的范围也是影响程序性能的表现的重要指标,假设同步代码块耗时为2ms并且所有的操作都需要这把锁,那么无论有多少个处理器,吞吐量也不会超过500个操作每秒,所以我们可以适当缩小锁的范围降低同步代码块的耗时,以提升程序的并发变现。
例如下面这个例子,为了操作共享资源的map,锁住了整个方法,这其中还包含一段休眠的IO逻辑:
private static HashMap<String, String> map = new HashMap<>(); public static synchronized String getVal(String key) { ThreadUtil.sleep(1000); return map.get(key); }
对此我们也给出一个10个并发的压测逻辑,最终的耗时差不多在10s左右:
int size = 10; ExecutorService threadPool = Executors.newFixedThreadPool(size); CountDownLatch countDownLatch = new CountDownLatch(size); long begin = System.currentTimeMillis(); for (int i = 0; i < size; i++) { threadPool.execute(() -> { getVal("1"); countDownLatch.countDown(); }); } countDownLatch.await(); long end = System.currentTimeMillis(); Console.log("总耗时:{}ms", end - begin);
所以我们可以通过缩小synchronized 的范围缩小同步范围来减少持有锁时需要处理的指令数量以降低同步代码块的耗时,让CPU单位时间内可以处理尽可能多的线程以提升程序的并发度。
于是我们将代码改成下面这样,将非必要保证线程安全的操作放在锁之外,经过压测耗时基本稳定在1s左右,提升非常明显:
private static HashMap<String, String> map = new HashMap<>(); public static String getVal(String key) { ThreadUtil.sleep(1000); synchronized (Main.class) { return map.get(key); } }
当然这样的做法我们还是需要考虑到原子性,例如并发操作的更新,此时可能缩小锁的范围就可能存在一致性问题。
降低锁的请求频率
另一种减小锁持有时间的方式是,缩小锁的请求频率,如果一个锁需要保护多个独立状态的同步,这就导致许多非必要的同步阻塞,就像下面这段代码,获取user和获取shop的并发操作都采用了同一个对象实例锁,这就可能导致获取user期间shop的操做被阻塞,程序的吞吐量下降:
public synchronized void getUser() { //...... } public synchronized void getShop() { //...... }
所以解决方案就是将锁分解,将不同资源交由不同的锁管控,将锁的请求频率分解到不同的锁进行管控,从而提升程序的并发性能表现:
public synchronized void getUser() { synchronized (userLock){ System.out.println("getUser"); } } public void getShop() { synchronized (shopLock) { System.out.println("getShop"); } }
锁分段的哲学
把竞争激烈的锁分解为两个锁,这两个锁还是存在激烈的竞争,虽然采用两个线程提升的一部分的可伸缩性,但是在多核处理器中,仍然无法做到资源的最大化利用,所以我们也可以参考ConcurrentHashMap的思想,将锁分解计数拓展为通过一组独立对象进行统一管控,这也就是著名的锁分段技术,通过4个锁的数组,在散列算法和数据分布均匀的情况下,竞争的激烈程度将会压缩至原来的1/4:
public class SyncMap<K, V> { private final static int buckets = 1 << 2; private final static int mask = buckets - 1; private final Node<K, V>[] table = new Node[buckets]; private final Object[] locks = new Object[buckets]; private int size = 0; public SyncMap() { //初始化分段锁 for (int i = 0; i < locks.length; i++) { locks[i] = new Object(); } } /** * 链表的node节点 */ private class Node<K, V> { private K key; private V value; private Node next; public Node(K key, V value) { this.key = key; this.value = value; } } public V get(Object key) { //取模运算获得索引的位置 int idx = key.hashCode() & mask; //上分段锁 synchronized (locks[idx]) { Console.log("线程获取分段锁:{}", idx); for (Node<K, V> node = table[idx]; node != null; node = node.next) { if (node.key.equals(key)) { return node.value; } } return null; } } public void put(K key, V value) { int idx = key.hashCode() & mask; //上锁读取数据 synchronized (locks[idx]) { Node<K, V> node = table[idx]; //若为空则直接初始化节点 if (node == null) { table[idx] = new Node<>(key, value); size++; } else { Node pre = null; while (node != null && !node.key.equals(key)) { pre = node; node = node.next; } if (node == null) { pre.next = new Node(key, value); size++; } else { node.value = value; } } } } public int size() { return size; } }
很多读者反馈对于并发编程的程序测试无从下手,基于此问题,笔者索性将ai关闭以沉浸式的方式完成编码并给出测试单元的用例,总体来说并发编程测试的方式主要是抓住多线程操作后一些可以验证状态的的字段在程序结束后进行校验,例如我们现在想验证相同的key是否会完成覆盖,那么对应在我们的程序中的结果就是size不变值被覆盖
SyncMap<Integer, String> syncMap = new SyncMap<>(); //塞到底层的bucket0 Thread t0 = new Thread(() -> { syncMap.put(0, "0"); }); //塞到底层的bucket0模拟冲突 Thread t1 = new Thread(() -> { syncMap.put(0, "new"); }); t0.start(); t1.start(); t0.join(); t1.join(); //基于最终状态进行校验 Assert.equals(1, syncMap.size()); Assert.equals("new", syncMap.get(0));
然后就是测试多个bucket下是否可以完成拉链法,例如key为0和4都会落到bucket-0上,那么我们的最终校验就是判断这两个键值对是否都可以查出来,然后查看bucket-0这个桶下的链表size是否为2即可,这里笔者就简单的做个值查询,关于bucket桶的校验在断点上做个确认:
SyncMap<Integer, String> syncMap = new SyncMap<>(); //塞到底层的bucket0 Thread t0 = new Thread(() -> { syncMap.put(0, "0"); }); //塞到底层的bucket0模拟冲突 Thread t1 = new Thread(() -> { syncMap.put(4, "4"); }); t0.start(); t1.start(); t0.join(); t1.join(); //基于最终状态进行校验 Assert.equals("4", syncMap.get(4)); Assert.equals("0", syncMap.get(0));
针对其他类型的测试也是差不多意思,读者可以根据自己的用例场景自行覆盖。
避免热点域
另一个方面,我们也可以使用缓存技术将热点数据进行缓存,当然这些热点域可能也会限制可伸缩性。例如HashMap进行修改操作时会使用维护一份size变量,保证容量和判空操作的时间复杂度压降为O(1),但是在并发操作下,因为需要同步的原因,同步的等待耗时又会导致可伸缩问题(即增加硬件资源之后,程序的吞吐量不减反增):

java-concurrency-optimization-4.drawio
对此ConcurrentHashMap则是采用分段进行技术枚举遍历不同分段中的容器数进行累加,来提升并发计数维护的效率,如下图,从宏观角度来说,ConcurrentHashMap进行size累加时默认会先通过CAS的方式进行累加,一旦失败就回尝试累加到counterCells中,同时考虑到键值对的增加counterCells竞争也会变变得激烈,该数组也会根据激烈情况进行动态扩容,这种理念也存在于jkd8的计数工具LongAddr。
然后在进行size计算时就会讲baseCount和counterCells数组遍历累加,得到size的值:


















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









