



1、五种数据结构的应用场景 2、五种数据机构的底层实现 3、高性能的原因?是不是单线程? 4、scan渐进式遍历键
一、Redis核心对象
在Redis中有一个核心的对象叫做redisObject ,是用来表示所有的key和value的,用redisObject结构体来表示String、Hash、List、Set、ZSet五种数据类型。
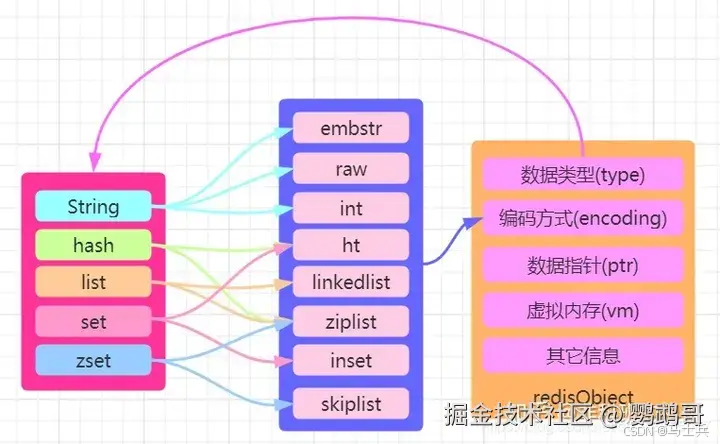
在redisObject中type表示属于哪种数据类型,encoding表示该数据的存储方式,也就是底层的实现该数据类型的数据结构。
二、基本类型和底层实现
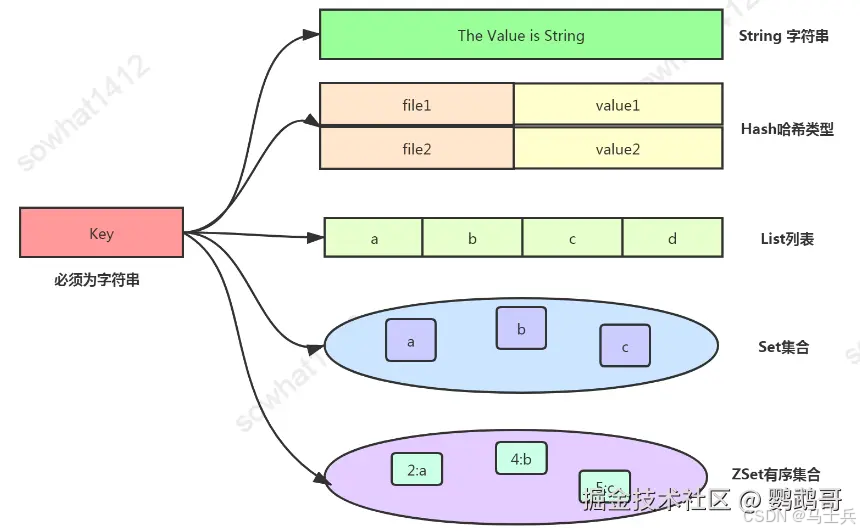
1.1 String
用途:
适用于简单key-value存储、setnx key value实现分布式锁、计数器(原子性)、分布式全局唯一ID。还可以用来存储图片
底层:String类型的数据结构存储方式有三种int、raw、embstr。那么这三种存储方式有什么区别呢?
1.1.1 int
Redis中规定假如存储的是整数型值,比如set num 123这样的类型,就会使用 int的存储方式进行存储,在redisObject的ptr属性中就会保存该值。
1.1.2 SDS
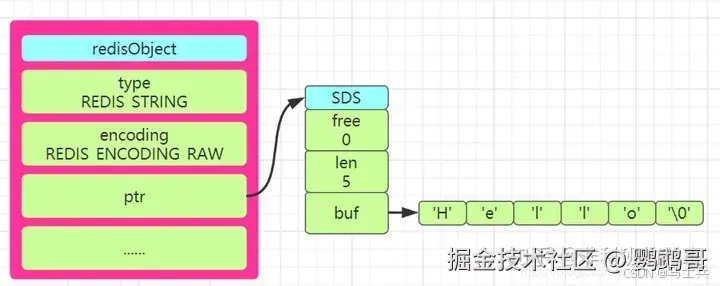
假如存储的字符串是一个字符串值并且长度大于32个字节就会使用SDS(simple dynamic string)方式进行存储,并且encoding设置为raw;若是字符串长度小于等于32个字节就会将encoding改为embstr来保存字符串。 SDS称为简单动态字符串,对于SDS中的定义在Redis的源码中有的三个属性int len、int free、char buf[]。
c
代码解读
复制代码
struct sdshdr{ unsigned int len; // 标记char[]的长度 unsigned int free; //标记char[]中未使用的元素个数 char buf[]; // 存放元素的坑 }
len保存了字符串的长度,free表示buf数组中未使用的字节数量,buf数组则是保存字符串的每一个字符元素。 因此在Redsi中存储一个字符串Hello时,根据Redis的源代码的描述可以画出SDS的形式的redisObject结构图如下图所示:
1.1.3 SDS与c语言字符串对比
SDS对c语言的字符串做了自己的设计和优化,具体优势有以下几点: (1)c语言中的字符串并不会记录自己的长度,因此每次获取字符串的长度都会遍历得到,时间的复杂度是O(n),而Redis中获取字符串只要读取len的值就可,时间复杂度变为O(1)。 (2)c语言中两个字符串拼接,若是没有分配足够长度的内存空间就会出现缓冲区溢出的情况;而SDS会先根据len属性判断空间是否满足要求,若是空间不够,就会进行相应的空间扩展,所以不会出现缓冲区溢出的情况。 (3)SDS还提供空间预分配和惰性空间释放两种策略。在为字符串分配空间时,分配的空间比实际要多,这样就能减少连续的执行字符串增长带来内存重新分配的次数。当字符串被缩短的时候,SDS也不会立即回收不适用的空间,而是通过free属性将不使用的空间记录下来,等后面使用的时候再释放。具体的空间预分配原则是:当修改字符串后的长度len小于1MB,就会预分配和len一样长度的空间,即len=free;若是len大于1MB,free分配的空间大小就为1MB。 (4)SDS是二进制安全的,除了可以储存字符串以外还可以储存二进制文件(如图片、音频,视频等文件的二进制数据);而c语言中的字符串是以空字符串作为结束符,一些图片中含有结束符,因此不是二进制安全的。
1.2 Hash
散列非常适用于将一些相关的数据存储在一起,比如用户的购物车。 注意:Redis中只有一个K,一个V。其中 K 绝对是字符串对象,而 V 可以是String、List、Hash、Set、ZSet任意一种。 因为Hash对象的实现方式有两种分别是ziplist、hashtable,其中hashtable的存储方式key是String类型的,value也是以key value的形式进行存储。 hash的底层主要是采用字典dict的结构,字典类型的底层就是hashtable实现的。整体呈现层层封装。从小到大如下:
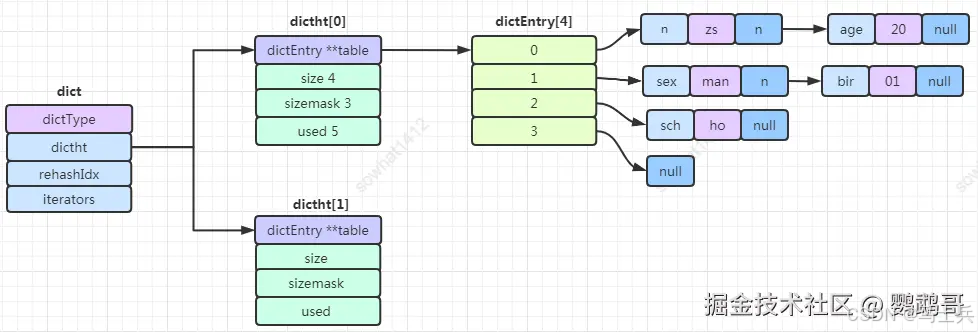
1.2.1 dict
dictEntry
真正的数据节点,包括key、value 和 next 节点。
![]()
dictht
1、数据 dictEntry 类型的数组,每个数组的item可能都指向一个链表。 2、数组长度 size。 3、sizemask 等于 size - 1。 4、used表示当前 dictEntry 数组中包含总共多少节点。

dict
1、dictType 类型,包括一些自定义函数,这些函数使得key和value能够存储 2、rehashidx 其实是一个标志量,如果为-1说明当前没有扩容,如果不为 -1 则记录扩容位置。 3、dictht数组,两个Hash表。 4、iterators 记录了当前字典正在进行中的迭代器
组合后结构就是如下:
渐进式扩容
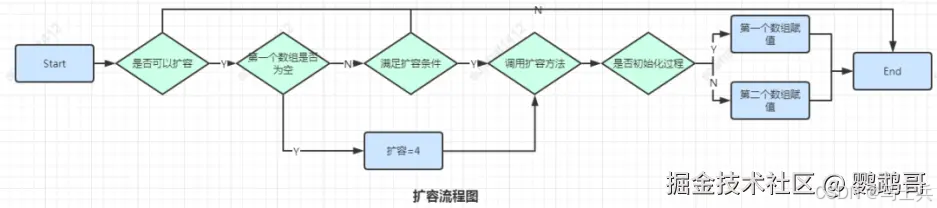
在字典的底层实现中,value对象以每一个dictEntry的对象进行存储,当hash表中的存放的键值对不断的增加或者减少时,需要对hash表进行一个扩展或者收缩。 为什么 dictht ht[2]是两个呢?目的是在扩容的同时不影响前端的CURD,慢慢的把数据从ht[0]转移到ht[1]中,同时rehashindex来记录转移的情况,当全部转移完成,将ht[1]改成ht[0]使用。 rehashidx = -1说明当前没有扩容,rehashidx != -1则表示扩容到数组中的第几个了。 扩容之后的数组大小为大于used * 2的2的n次方的最小值,收缩操作时used 的第一个大于等于的 2 的整数幂。然后挨个遍历数组同时调整rehashidx的值,对每个dictEntry[i] 再挨个遍历链表将数据 Hash 后重新映射到 dictht[1]里面。并且 dictht[0].used 跟 dictht[1].used 是动态变化的。
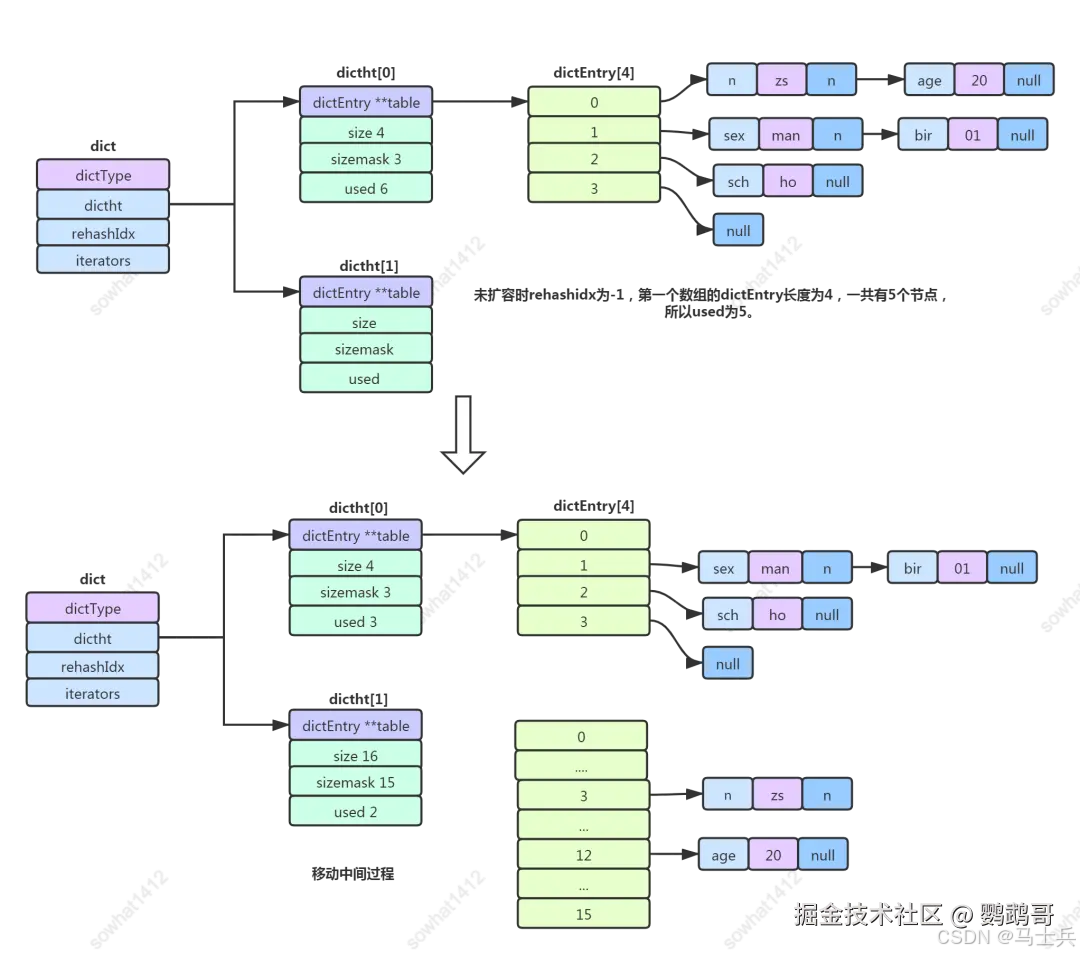
整个过程的重点在于rehashidx,其为第一个数组正在移动的下标位置,如果当前内存不够,或者操作系统繁忙,扩容的过程可以随时停止。 停止之后如果对该对象进行操作,那是什么样子的呢?
- 如果是新增,则直接新增后第二个数组,因为如果新增到第一个数组,以后还是要移过来,没必要浪费时间
- 如果是删除,更新,查询,则先查找第一个数组,如果没找到,则再查询第二个数组。
1.2.2 ziplist
压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。 压缩列表是列表键和哈希键底层实现的原理之一,压缩列表并不是以某种压缩算法进行压缩存储数据,而是它表示一组连续的内存空间的使用,节省空间,压缩列表的内存结构图如下:

压缩列表中每一个节点表示的含义如下所示:
- zlbytes:4个字节的大小,记录压缩列表占用内存的字节数。
- zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点的地址。
- zllen:2个字节的大小,记录压缩列表中的节点数。
- entry:表示列表中的每一个节点。
- zlend:表示压缩列表的特殊结束符号'0xFF'。
在压缩列表中每一个entry节点又有三部分组成,包括previous_entry_ength、encoding、content。
- previous_entry_ength表示前一个节点entry的长度,可用于计算前一个节点的起始地址,因为地址是连续的。
- encoding:这里保存的是content的内容类型和长度。
- content:content保存的是每一个节点的内容。

1.3 List
Redis中的列表在3.2之前的版本是使用ziplist和linkedlist进行实现的。在3.2之后的版本就是引入了quicklist。 linkedlist是一个双向链表。插入、修改、更新的时间复杂度尾O(1),但是查询的时间复杂度确实O(n)。 linkedlist和quicklist的底层实现是采用链表进行实现,在c语言中并没有内置的链表这种数据结构,Redis实现了自己的链表结构。
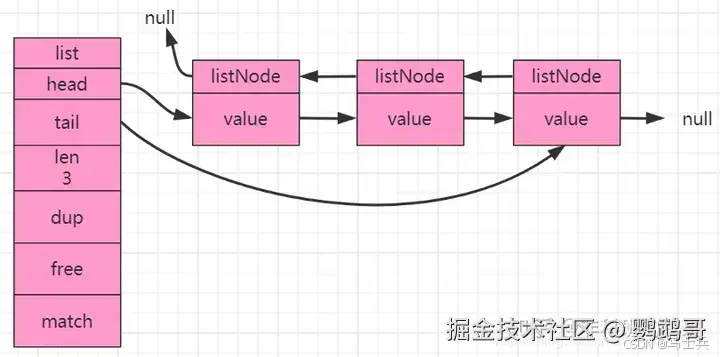
Redis中链表的特性:
- 每一个节点都有指向前一个节点和后一个节点的指针。
- 头节点和尾节点的prev和next指针指向为null,所以链表是无环的。
- 链表有自己长度的信息,获取长度的时间复杂度为O(1)。
lpush + lpop = stack 先进后出的栈 lpush + rpop = queue 先进先出的队列 lpush + ltrim = capped collection 有限集合 lpush + brpop = message queue 消息队列
一般可以用来做简单的消息队列,并且当数据量小的时候可能用到独有的压缩列表来提升性能。当然专业点还是要 RabbitMQ、Kafka等。
1.4 Set
Redis中列表和集合都可以用来存储字符串,但是Set是不可重复的集合,而List列表可以存储相同的字符串,Set集合是无序的和ZSet有序集合相对。 Set的底层实现是ht和intset,ht就是hashtable。 inset也叫做整数集合,用于保存整数值的数据结构类型,它可以保存int16_t、int32_t 或者int64_t 的整数值。 在整数集合中,有三个属性值encoding、length、contents[],分别表示编码方式、整数集合的长度、以及元素内容,length就是记录contents里面的大小。 在整数集合新增元素的时候,若是超出了原集合的长度大小,就会对集合进行升级,具体的升级过程如下:
- 首先扩展底层数组的大小,并且数组的类型为新元素的类型。
- 然后将原来的数组中的元素转为新元素的类型,并放到扩展后数组对应的位置。
- 整数集合升级后就不会再降级,编码会一直保持升级后的状态。
Set集合的应用场景可以用来去重、抽奖、共同好友、二度好友等业务类型。
1.5 ZSet集合
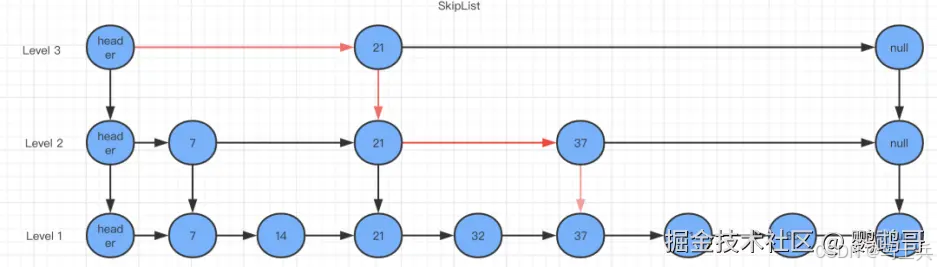
ZSet是有序集合,ZSet的底层实现是ziplist和skiplist实现的。 skiplist也叫跳跃表,跳跃表是一种有序的数据结构,是多层链表的结合体,跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。 skiplist由如下几个特点:
- 有很多层组成,由上到下节点数逐渐密集,最上层的节点最稀疏,跨度也最大。
- 每一层都是一个有序链表,只扫包含两个节点,头节点和尾节点。
- 每一层的每一个节点都含有指向同一层下一个节点和下一层同一个位置节点的指针。
- 如果一个节点在某一层出现,那么该以下的所有链表同一个位置都会出现该节点。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在找出值为37的节点为例,来对比说明跳表和普遍的链表。
- 没有跳表查询 比如我查询数据37,如果没有上面的索引时候路线如下图:
![]()
2. 有跳表查询 有跳表查询37的时候路线如下图:
- 应用场景:
积分排行榜、时间排序新闻、延时队列。
1.6 Redis Geo
核心原理可以参考:Redis Geo核心原理解析。核心思想就是将地球近似为球体来看待,然后 GEO利用 GeoHash 将二维的经纬度转换成字符串,来实现位置的划分跟指定距离的查询。
1.7 HyperLoglog
HyperLogLog :是一种概率数据结构,它使用概率算法来统计集合的近似基数。而它算法的最本源则是伯努利过程 + 分桶 + 调和平均数。 功能:误差允许范围内做基数统计 (基数就是指一个集合中不同值的个数) 的时候非常有用,每个HyperLogLog的键可以计算接近2^64不同元素的基数,而大小只需要12KB。错误率大概在0.81%。所以如果用做 UV 统计很合适。 HyperLogLog底层 一共分了 2^14 个桶,也就是 16384 个桶。每个(registers)桶中是一个 6 bit 的数组,这里有个骚操作就是一般人可能直接用一个字节当桶浪费2个bit空间,但是Redis底层只用6个然后通过前后拼接实现对内存用到了极致,最终就是 16384*6/8/1024 = 12KB。
1.8 bitmap
BitMap 原本的含义是用一个比特位来映射某个元素的状态。由于一个比特位只能表示 0 和 1 两种状态,所以 BitMap 能映射的状态有限,但是使用比特位的优势是能大量的节省内存空间。 在 Redis 中BitMap 底层是基于字符串类型实现的,可以把 Bitmaps 想象成一个以比特位为单位的数组,数组的每个单元只能存储0和1,数组的下标在 Bitmaps 中叫做偏移量,BitMap 的 offset 值上限 2^32 - 1。

- 用户签到
key = 年份:用户id offset = (今天是一年中的第几天) % (今年的天数)
- 统计活跃用户
使用日期作为 key,然后用户 id 为 offset 设置不同offset为0 1 即可。 PS : Redis 它的通讯协议是基于TCP的应用层协议 RESP(REdis Serialization Protocol)。

















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









