




构建高性能 ClickHouse 集群表的五层建表结构
在生产环境中,为了实现高效的数据摄取、存储、查询以及分布式计算性能优化,可以基于 ClickHouse 的特性设计五层建表结构。以下是基于 Kafka 数据流和 ClickHouse 的集群表设计方案。
总体表架构图
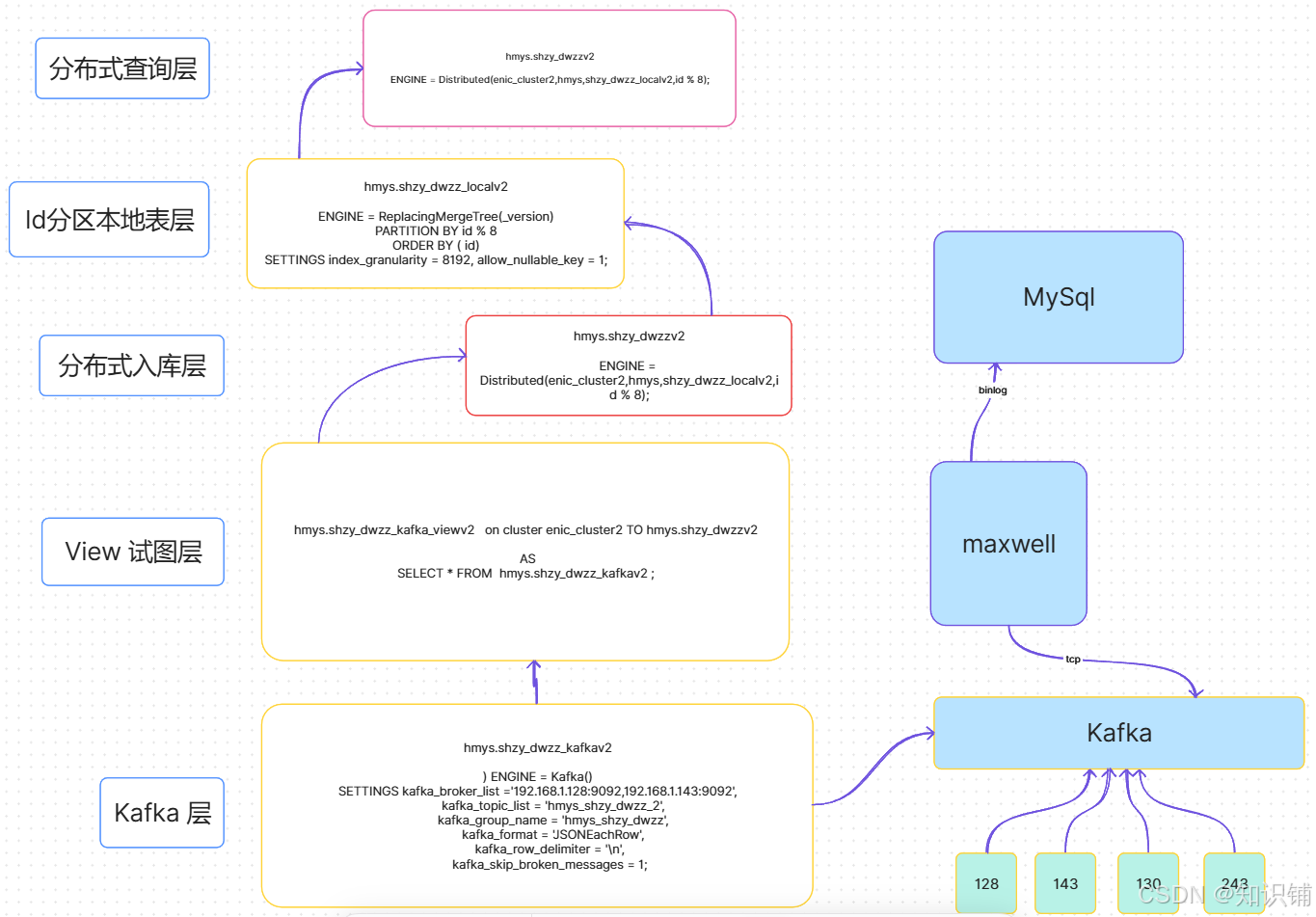
五层建表架构简介
Kafka 驱动表层
使用 Kafka 引擎表实现对 Kafka 消息的实时消费和摄取。
View 视图层
通过物化视图消费 Kafka 表中的数据,实现实时数据导入,同时保留必要的转换逻辑。
分布式入库层
分布式表用于管理多个节点上的本地表,以实现水平扩展和集群化数据分布。
Id 分区本地表层
以分区机制存储数据的本地表,分区可以基于 ID、时间等,提供高效查询和存储性能。
分布式查询层
分布式表的读写层,用于对整个集群中的数据进行统一查询和管理。
1. 创建kafka引擎表
CREATE TABLE hmys.shzy_dwzz_kafkav2 on cluster enic_cluster2
(
`id` Int32,
`uuid` Nullable(String) COMMENT '外部uuid唯一标识',
`user_no` Nullable(Int32) COMMENT '用户ID',
`member_no` Nullable(Int32) COMMENT '登陆者ID',
`device_sn` Nullable(String) COMMENT '设备SN码',
`device_no` Nullable(Int32) COMMENT '设备编号',
`device_type` Nullable(Int32) COMMENT '',
`created_at` Nullable(DateTime) COMMENT '创建时间',
`creator` Nullable(String) COMMENT '创建者',
`updated_at` Nullable(DateTime) COMMENT '修改时间',
`modifier` Nullable(String) COMMENT '修改者',
`ecg_feq` Nullable(Int32) COMMENT '采样频率',
`ecg_len` Nullable(Int32) COMMENT '波形长度',
`begin_time` Nullable(DateTime) COMMENT '开始时间',
`end_time` Nullable(DateTime) COMMENT '结束时间',
`take_time` Nullable(DateTime) COMMENT '检查时间',
`file_image_path` Nullable(String) COMMENT '一段图URL',
`file_image_detail` Nullable(String) COMMENT '详情图URL',
`ecg_image_index_path` Nullable(String) COMMENT 'HW首页透明色背景',
`type` Nullable(Int32) COMMENT ' ',
`_version` UInt32
) ENGINE = Kafka()
SETTINGS kafka_broker_list ='192.168.1.128:9092,192.168.1.143:9092',
kafka_topic_list = 'hmys_shzy_dwzz_2',
kafka_group_name = 'hmys_shzy_dwzz',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n',
kafka_skip_broken_messages = 1;
2。 创建本地表
CREATE TABLE hmys.shzy_dwzz_localv2 on cluster enic_cluster2
(
`id` Int32,
`uuid` Nullable(String) COMMENT '外部uuid唯一标识',
`user_no` Nullable(Int32) COMMENT '用户ID',
`member_no` Nullable(Int32) COMMENT '登陆者ID',
`device_sn` Nullable(String) COMMENT '设备SN码',
`device_no` Nullable(Int32) COMMENT '设备编号',
`device_type` Nullable(Int32) COMMENT '',
`created_at` Nullable(DateTime) COMMENT '创建时间',
`creator` Nullable(String) COMMENT '创建者',
`updated_at` Nullable(DateTime) COMMENT '修改时间',
`modifier` Nullable(String) COMMENT '修改者',
`ecg_feq` Nullable(Int32) COMMENT '采样频率',
`ecg_len` Nullable(Int32) COMMENT '波形长度',
`begin_time` Nullable(DateTime) COMMENT '开始时间',
`end_time` Nullable(DateTime) COMMENT '结束时间',
`take_time` Nullable(DateTime) COMMENT '检查时间',
`file_image_path` Nullable(String) COMMENT '一段图URL',
`file_image_detail` Nullable(String) COMMENT '详情图URL',
`ecg_image_index_path` Nullable(String) COMMENT 'HW首页透明色背景',
`type` Nullable(Int32) COMMENT ' ',
`_version` UInt32
)
ENGINE = ReplacingMergeTree(_version)
PARTITION BY id % 8
ORDER BY ( id)
SETTINGS index_granularity = 8192, allow_nullable_key = 1;
3. 创建分布式表-管理本地表
CREATE TABLE hmys.shzy_dwzzv2 on cluster enic_cluster2 (
`id` Int32,
`uuid` Nullable(String) COMMENT '外部uuid唯一标识',
`user_no` Nullable(Int32) COMMENT '用户ID',
`member_no` Nullable(Int32) COMMENT '登陆者ID',
`device_sn` Nullable(String) COMMENT '设备SN码',
`device_no` Nullable(Int32) COMMENT '设备编号',
`device_type` Nullable(Int32) COMMENT '',
`created_at` Nullable(DateTime) COMMENT '创建时间',
`creator` Nullable(String) COMMENT '创建者',
`updated_at` Nullable(DateTime) COMMENT '修改时间',
`modifier` Nullable(String) COMMENT '修改者',
`ecg_feq` Nullable(Int32) COMMENT '采样频率',
`ecg_len` Nullable(Int32) COMMENT '波形长度',
`begin_time` Nullable(DateTime) COMMENT '开始时间',
`end_time` Nullable(DateTime) COMMENT '结束时间',
`take_time` Nullable(DateTime) COMMENT '检查时间',
`file_image_path` Nullable(String) COMMENT '一段图URL',
`file_image_detail` Nullable(String) COMMENT '详情图URL',
`ecg_image_index_path` Nullable(String) COMMENT 'HW首页透明色背景',
`type` Nullable(Int32) COMMENT ' ',
`_version` UInt32
) ENGINE = Distributed(enic_cluster2,hmys,shzy_dwzz_localv2,id % 8);
4. 创建物化视图表,消费kafka表数据,导入到分布式表中
CREATE MATERIALIZED VIEW hmys.shzy_dwzz_kafka_viewv2 on cluster enic_cluster2 TO hmys.shzy_dwzzv2 AS
SELECT * FROM hmys.shzy_dwzz_kafkav2 ;
总结
五层建表结构实现了从数据摄取到查询的高效数据处理流程:
Kafka 驱动表层:实时数据接入。
View 视图层:负责数据的转换和消费。
分布式入库层:构建全局分布式存储。
Id 分区本地表层:优化单节点存储和查询性能。
分布式查询层:高效的跨节点查询。


















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









