 Mysql索引与B+树详解
Mysql索引与B+树详解





 本文详细解析了Mysql中使用的B+树索引结构及其与B树的区别,探讨了B+树的特点及优势,并介绍了Mysql中聚集索引与非聚集索引的工作原理,以及联合索引的最左前缀匹配原则。
本文详细解析了Mysql中使用的B+树索引结构及其与B树的区别,探讨了B+树的特点及优势,并介绍了Mysql中聚集索引与非聚集索引的工作原理,以及联合索引的最左前缀匹配原则。
上一篇讲的是Mysql存储结构
https://blog.youkuaiyun.com/sbitxmdf/article/details/113766970
这篇记录对索引存储结构的理解
目前知道Mysql索引用的数据结构是B+树,那么什么是B+树,和B树有什么区别?
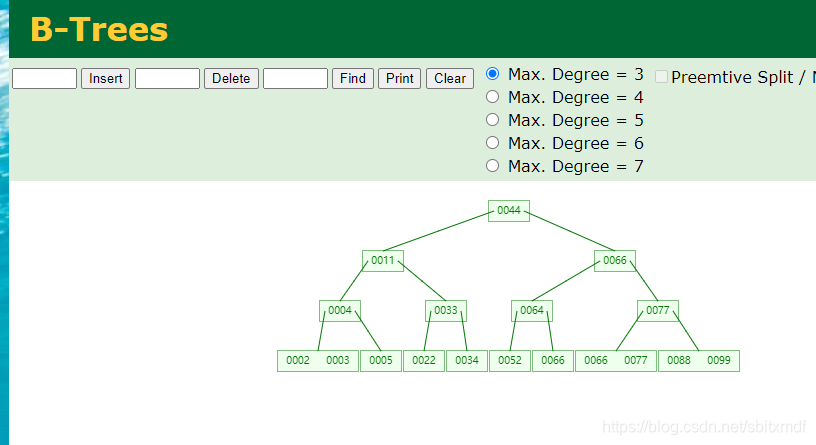
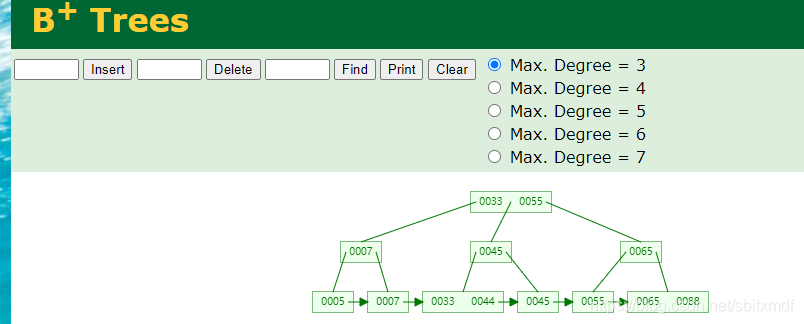
可以看出B树与B+树的区别
1、B+树在叶子节点处都有箭头相连,但B树没有。
2、B-树的非叶子节点在叶子节点没有,但B+树不同,在叶子节点的数据,包含了非叶子节点的所有数据。
为什么有这样的区别?这和他们存储数据的不同有关系。
B树会在非叶子节点和叶子节点都记录值和引用的页指针;B+树只会在叶子节点处存储值和页指针,并且,数据是有序的,因为它是有序的,所以可以用箭头将他们连接起来,对于查询范围内的数据相当有效。
那么B+树肯定比B树更好了?所有的数据结构都有优缺点,直接复制
b树的优点
B树的每一个节点都包含key和value。
所以,经常访问的元素可能离根节点更近,所以访问也是更加的迅速
b+树的优点
1、b+树的中间节点不保存数据,可以容纳更多的节点元素
2、所有的叶子结点使用链表相连,有助于区间查找和遍历
B树的话,就需要进行每一层的递归遍历
相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好
B+树介绍完之后,看下索引存储结构
下面看一下都在用的图(盗图)
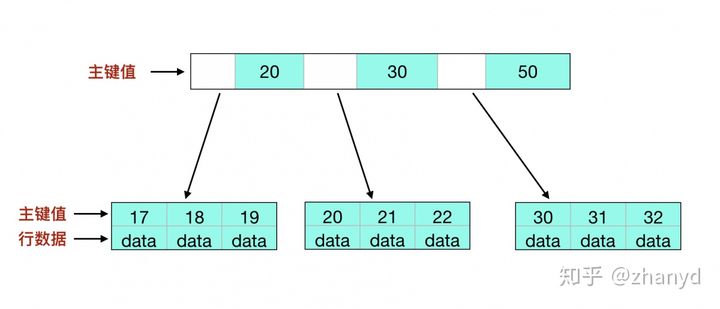
解释下这张图:
存储两类数据,一类是索引值,一类是页物理地址(这里直接写行数据是有问题的)
在索引时,应先找到对应值,然后根据页地址找到数据所在页,然后在页中进行搜索,找到数据所属的糟,再确定数据行的位置,这部分内容可参考上一篇,mysql存储结构
这张图表示的是聚集索引,非聚集索引有些区别,下面说下非聚集索引
先简单说下聚集和非聚集索引,也叫聚簇和非聚簇索引,聚集索引可以理解为主键索引,非聚集索引就是非主键索引,就是平时创建的普通索引,也是二级索引。
也是上面这张图,但存储内容会有变化,
存储两类数据,一类是索引值,一类是主键值,通过索引值找到对应的主键值,再走上面的聚集索引过程,这个过程也叫回表。
下面引用下联合索引存储结构,转载
联合索引
所谓联合索引,也称多列所谓,就是建立在多个字段上的索引,这个概念是跟单列索引相对的。联合索引依然是B+树,但联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
例如在a和b字段上建立联合索引,索引结构将如下图所示:
一目了然,当我们再执行SELECT score FROM student WHERE name='叶良辰';时,可以直接通过扫描非聚集索引直接获取score的值,而不再需要到聚集索引上二次扫描了。
最左前缀匹配
联合索引中有一个重要的课题,就是最左前缀匹配。
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
这是为什么呢?我们再仔细观察索引结构,可以看到索引key在排序上,首先按a排序,a相等的节点中,再按b排序。因此,如果查询条件是a或a和b联查时,是可以应用到索引的。如果查询条件是单独使用b,因为无法确定a的值,因此无法使用索引。
假如在table表的a,b,c三个列上建立联合索引,简要分类分析下联合索引的最左前缀匹配。
首先看等值查询:
1、全值匹配查询时(where子句搜索条件顺序调换不影响索引使用,因为查询优化器会自动优化查询顺序 ),可以用到联合索引
SELECT * FROM table WHERE a=1 AND b=3 AND c=2
SELECT * FROM table WHERE b=3 AND c=4 AND a=2
- 1
- 2
2、匹配左边的列时,可以用到联合索引
SELECT * FROM table WHERE a=1
SELECT * FROM table WHERE a=1 AND b=3
- 1
- 2
3、未从最左列开始时,无法用到联合索引
SELECT * FROM table WHERE b=1 AND b=3
- 1
4、查询列不连续时,无法使用联合索引(会用到a列索引,但c排序依赖于b,所以会先通过a列的索引筛选出a=1的记录,再在这些记录中遍历筛选c=3的值,是一种不完全使用索引的情况)
SELECT * FROM table WHERE a=1 AND c=3
- 1
再看范围查询:
1、范围查询最左列,可以使用联合索引
SELECT * FROM table WHERE a>1 AND a<5;
- 1
2、精确匹配最左列并范围匹配其右一列(a值确定时,b是有序的,因此可以使用联合索引)
SELECT * FROM table WHERE a=1 AND b>3;
- 1
3、精确匹配最左列并范围匹配非右一列(a值确定时,c排序依赖b,因此无法使用联合索引,但会使用a列索引筛选出a>2的记录行,再在这些行中条件 c >3逐条过滤)
SELECT * FROM table WHERE a>2 AND c>5;

















 2811
2811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









