







字符串匹配就是在一个主串中找到待匹配串的位置,一般是返回第一次出现的位置.一般思路是从待匹配串的第一个字符开始逐个与主串中的字符匹配,如果匹配成功,则主串和待匹配串都后移一位,匹配下一个字符,如果匹配不成功,待匹配串从头开始与主串的下一位匹配.这就是朴素匹配.下面是代码
int Index (String S, String T) {
int i = 1, j = 1;
while (i <= S.length() && j <= T.length()) {
if (S[i] == T[j]) {
++i;
++j;
} else {
i = i - j + 2;
j = 1;
}
}
if (j > T.length())
return i - T.length();
else
return 0;
}
//算法最坏时间复杂度为O(n*m),n,m分别为主串和待匹配串的长度
这种简单匹配有一个简单的问题就是,出现大量没有必要的回退,如
a b a b c a b c a c b a b
..a b c a c
此时c与b不匹配,带匹配串要回到第一个字符a处,而主串要回到第二个b处,但是回退后主串和待匹配串此时要匹配的字符肯定不同,这是我们在上一次匹配是就得到的结论,所以这种回退是没必要的,但怎样才是回退最少呢?由于此时c与b不匹配,但是c之前的都已经匹配了,假如说主串不动,待匹配串向右滑动,那么只需要让待匹配串向右滑动一个距离,使c前面中的字符尽可能多的与主串中的匹配成功,这样就能使主串回退的少,待匹配串也回退的少.如果这句话没理解的话,换句话说就是在在主串和待匹配串已经匹配成功的这部分中,挑主串中后缀中与待匹配串前缀中相同的部分的最大长度.
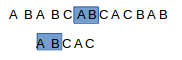
如图,此时C与B不匹配,回退就是让蓝色部分尽可能的长,那么回退的就会少.也就是这部分再次比较了.好了,到这就应该明白我们要干什么了,但是怎么做呢?我们来想想,我们要找的就是不匹配字符串之前的那部分已经匹配的部分中,主串的后缀和待匹配串的前缀相同的最大部分,而我们要找的这部分所在的部分正好就是已经匹配了的部分,即待匹配串发生不匹配处之前的部分,那么其实就和主串没有关系了,只需要在待匹配串的发生不匹配处以前的子串中找到前后缀相同的最大部分就行了.
那好,现在简单了,只需要分析待匹配串的前后缀就行了,但是是分析谁的前后缀呢,是整个待匹配串的前后缀还是待匹配串的子串的前后缀呢?答案肯定是后者,因为我们每次在发生不匹配时才决定要后退多少步(前后缀相同部分的长度),而不匹配可能在任意一个字符处发生,也就是说,每一个字符都应该对应一个后退值,以便于在发生不匹配是,确定后退多少步.而这个步长我们记录下来就叫做next值,顾名思义,就是发生不匹配,下一步得后退多少.
那么next值的求法就是整个算法的关键,这个算法就是KMP算法.
那么next怎么求呢?如果你之前看过其他文章,肯定会看到一个公式,
next[j]={
0,当j=1时Max[k∣1<k<j且‘P1...Pk−1=′Pj−k+1...Pj−1′]1,其他情况next[j] = \begin{cases} 0 ,当j=1时\\ Max [k|1 < k < j 且`P1...Pk-1 = 'Pj-k+1...Pj-1']\\ 1,其他情况\\ \end{cases} next[j]=⎩
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2534
2534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











