 MySQL日志、主从复制、分库分表及读写分离
MySQL日志、主从复制、分库分表及读写分离




日志
错误日志
记录了当mysqld启动和停止时,以及服务器在运行过程中发生任何任何严重错误时的相关信息;当数据库出现鼓掌导致无法正常使用时,建议首先查看此日志
该日志默认开启,存放在/var/log/mysqld.log
二进制日志
二进制日志(BINLOG)记录了所有的DDL语句和DML语句,也就是记录了表和表数据的变更;但不包括数据查询select, show语句
存放路径 /var/lib/mysql/binlog
二进制日志的一般作用于灾难时的数据恢复、mysql的主从复制
通过 show variables like '%binlog_format%' 查看当前实例的日志格式
 日志格式
日志格式
- STATEMENT:每一条会修改数据的 SQL 语句都会记录在 binlog 中。这种格式可能会有非确定性行为,因为在某些情况下,相同的 SQL 语句在不同的机器或时间点上执行可能会产生不同的结果(例如,如果涉及到当前时间或随机值)。
- ROW:基于行的复制,即记录每一行被修改的内容。这种格式更加确定,但可能会产生更大的 binlog 文件。
- MIXED:MySQL 会根据执行的 SQL 语句自动选择使用 STATEMENT 还是 ROW 格式。如果 MySQL 认为使用 STATEMENT 格式安全,就会使用它;否则,会使用 ROW 格式。
由于日志是以二进制方式存储的,无法直接读取,需要通过二进制日志查询工具查看
mysqlbinlog [参数] filename
-d 指定数据库名称,只列出指定的数据库相关操作-o 忽略日志中的前n行命令
-v 将行事件(数据变更)重构为sql语句,详细模式(verbose mode)。在这种模式下,
mysqlbinlog会输出更多的信息,例如时间戳、执行的线程 ID 等,使得输出更加易于阅读和理解-vv 在上面的前提下同时输出注释信息
对于繁忙的的业务系统,每天生成的binlog数据巨大,长时间不清理会占用大量磁盘空间

也可以设置日志过期时间,在my.cnf中设置binlog_expire_logs_seconds的参数 单位为秒
查询日志
查询日志中记录了客户端的所有操作语句,不同于二进制日志不包含查询数据的sql语句。默认情况下查询日志是关闭的,通过修改my.cnf文件开启
general_log = 1
general_log_file = /var//log/host_name.log
设置日志的文件名,默认为host_name.log
慢查询日志
慢查询日志默认关闭状态
在 /etc/my.cnf 文件中添加以下配置
# 开启慢日志查询开关
slow_query_log = 1
# 设置慢日志时间为1秒,超过两秒的会被标记为慢查询,记录到日志中long_query_time = 1
配置完重启mysql服务后,日志生成在 /var/lib/mysql/localhost-slow.log 中,通过对日志中记录的低效率语句进行sql优化来提升性能
主从复制
mysql支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制。
主从复制的好处主要包含:
1、主库出现问题,可以快速切换到从库提供服务
2、实现读写分离,降低单库读写压力
3、可以在从库中执行备份,避免备份期间影响主库服务
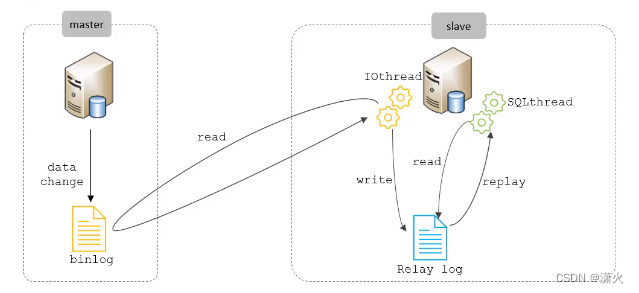
主从复制原理
主库中进行DML和DDL语句时,二进制日志binlog会记录所有的语句,从库中有两组线程,IOThread读取主库中的binlog并将其返回给从库并写到从库中的relay log中,SQLThread读取relay log并将里面的语句在从库中执行,将主库中的数据变化同步到自身,保证主从同步
配置
主库配置
1、修改 /etc/my.cnf 配置文件
# mysql服务ID,保证整个集群环境中唯一
server-id = 1
# 1表示只读,0表示读写
read-only = 0
2、重启mysql服务
3、登录mysql,创建远程连接的用户,并赋予该用户主从复制权限
CREATE USER 'slave01'@'%' IDENTIFIED WITH mysql_native_password BY 'psw';
GRANT REPLICATION SLAVE ON *.* TO 'slave01'@'%';
4、查看二进制日志坐标show master status
查询当前二进制文件写到哪一个文件(file)和哪一个位置(position),将当前位置往后的记录同步至从库
从库配置
1、修改 /etc/my.cnf 配置文件
# mysql服务ID,保证整个集群环境中唯一
server-id = 2
# 1表示只读,0表示读写
read-only = 1从库只要负责查询操作,不需要负责写入操作,仅针对普通用户,无法限制超级管理员,可以通过
super-read-only = 1
来限制超级管理员的只读
2、重启mysql服务
3、登录mysql 设置主库配置CHANGE REPLICATION SOURCE TO
SOURCE_HOST='P1',SOURCE_USER='P2',SOURCE_PASSWORD='P3',
SOURCE_LOG_FILE='P4',SOURCE_LOG_POS='P5';
P1:主服务器的IP地址或主机名。
P2:连接到主服务器的MySQL用户名。
P3:上述用户的密码。
P4:开始复制的二进制日志文件名。
P5:开始复制的二进制日志位置。
4、开启同步start replica;
5、查看同步show replica status;
分库分表
单数据库存在以下性能瓶颈:
1、IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低;请求数据太多,带宽不够,网络IO效率低
2、CPU瓶颈:排序、分组、连接查询、聚合统计等sql会消耗大量的CPU资源
以上两种情况很影响服务器的性能
分库分表的中心思想就是将数据分散存储,使得单一数据库/表的数据量变小,缓解单一数据库的压力,达到提升数据库性能的目的
拆分策略
垂直拆分
垂直分库:以表为依据,根据业务将不同表拆分到不同库中
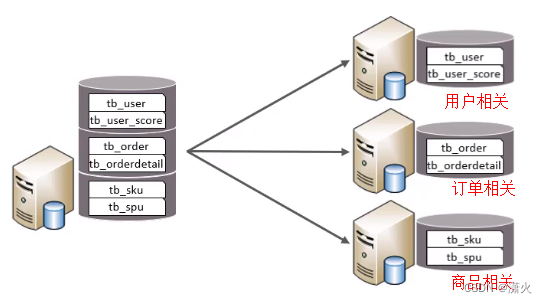
特点:
1、每个库的表结构都不一样
2、每个库的数据也不一样
3、所有库的并集是全量数据
垂直分表:以字段为依据,将不同字段拆分到不同的表中
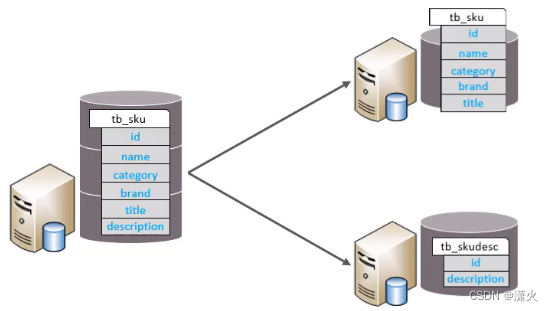
特点:
1、每个表的结构都不一样
2、每个表的数据也不一样,一般通过主键/外键关联
3、所有表的并集是全量数据
水平拆分
水平分库:以字段为依据,按一定策略,将一张表中的数据分散存储在多个数据库中,每个数据库中都有一张相同结构的表
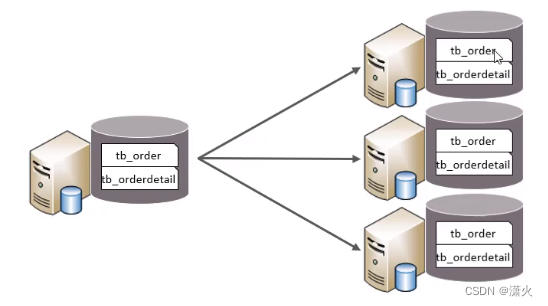
特点:
1、每个库的结构都一样
2、每个库的数据都不一样
3、所有库的并集是全量数据
水平分表:以字段为依据,按一定策略,将一个表的数据拆分到多个表中
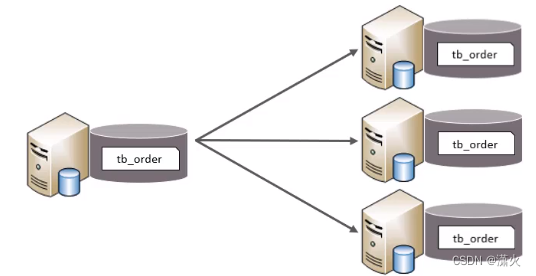
特点:
1、每个表的结构都一样
2、每个表的数据都不一样
3、所有表的并集是全量数据
实现技术:
1、shardingJDBC:基于AOP原理(面向切面的编程,对业务逻辑进行隔离,降低耦合度,提高重用性和开发效率),在应用程序中对本地执行的sql进行拦截、解析、改下、路由处理,只支持java语言
2、mycat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者
读写分离

















 2236
2236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









