




(CVPR2025)Best paper VGGT论文的复现
1.配置环境
vggt github链接地址(https://github.com/facebookresearch/vggt).
①首先使用anaconda激活一个虚拟环境名字叫做vggt,python = 3.10。
conda create -n vggt python=3.10
②安装依赖,这里我们避免torch的cuda或者cpu版本的问题(我们不知道某个pypi源下到底是cuda还是cpu版本,清华为CPU),将torch单独安装,这里是cuda11.8为例,下载较慢挂梯子。
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
pip install Pillow huggingface_hub einops safetensors -i https://pypi.tuna.tsinghua.edu.cn/simple
③克隆仓库
git clone git@github.com:facebookresearch/vggt.git
④下载权重
由于权重是在Hugging Face,国内仍然下载非常慢,因此我们也是挂上梯子后,从(https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt)下载,然后保存到自己的本地路径。
2.运行demo
①非可视化界面运行,修改13行为自己的权重路径,19行为数据集路径
import torch
from vggt.models.vggt import VGGT
from vggt.utils.load_fn import load_and_preprocess_images
import os
device = "cuda" if torch.cuda.is_available() else "cpu"
# bfloat16 is supported on Ampere GPUs (Compute Capability 8.0+)
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
# Initialize the model and load the pretrained weights.
# This will automatically download the model weights the first time it's run, which may take a while.
checkpoint_path = "./checkpoint/model.pt"
state_dict = torch.load(checkpoint_path)
model = VGGT().to(device)
model.load_state_dict(state_dict)
# 指定图片文件夹路径
folder_path = './images'
# 图片格式
image_extensions = ('.png', '.jpg', '.jpeg', '.bmp', '.gif', '.tiff')
# 获取文件夹下所有图片的路径
image_names = [
os.path.join(folder_path, file)
for file in os.listdir(folder_path)
if file.lower().endswith(image_extensions)
]
# 打印结果(可选)
print(image_names)
images = load_and_preprocess_images(image_names).to(device)
with torch.no_grad():
with torch.cuda.amp.autocast(dtype=dtype):
# Predict attributes including cameras, depth maps, and point maps.
predictions = model(images)
运行会报如下错误
You’re encountering this error because a Python module you’re trying to use was compiled against an older version of NumPy (1.x), but you currently have NumPy 2.1.2 installed. NumPy 2 introduced some backward-incompatible changes, which can cause older compiled extensions to malfunction or crash.
numpy 版本问题,需要卸载numpy,执行下面的代码。
pip uninstall numpy
pip install "numpy<2" -i https://pypi.tuna.tsinghua.edu.cn/simple
②可视化交互界面运行,下载可视化界面的依赖
pip install -r requirements_demo.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
执行完上面的代码后,会重新下载numpy 2.*版本,会冲突,再卸载numpy,使用pip install “numpy<2” -i https://pypi.tuna.tsinghua.edu.cn/simple,再下载numpy 1.*的版本,报以下错忽视即可。

修改原仓库的demo_gradio.py,将加载模型的代码改为本地加载。对应32-34行,改为如下代码,checkpoint_path对应自己的路径即可。
checkpoint_path = "./checkpoint/model.pt"
state_dict = torch.load(checkpoint_path)
model = VGGT()
model.load_state_dict(state_dict)
命令行运行 python demo_gradio.py即可。

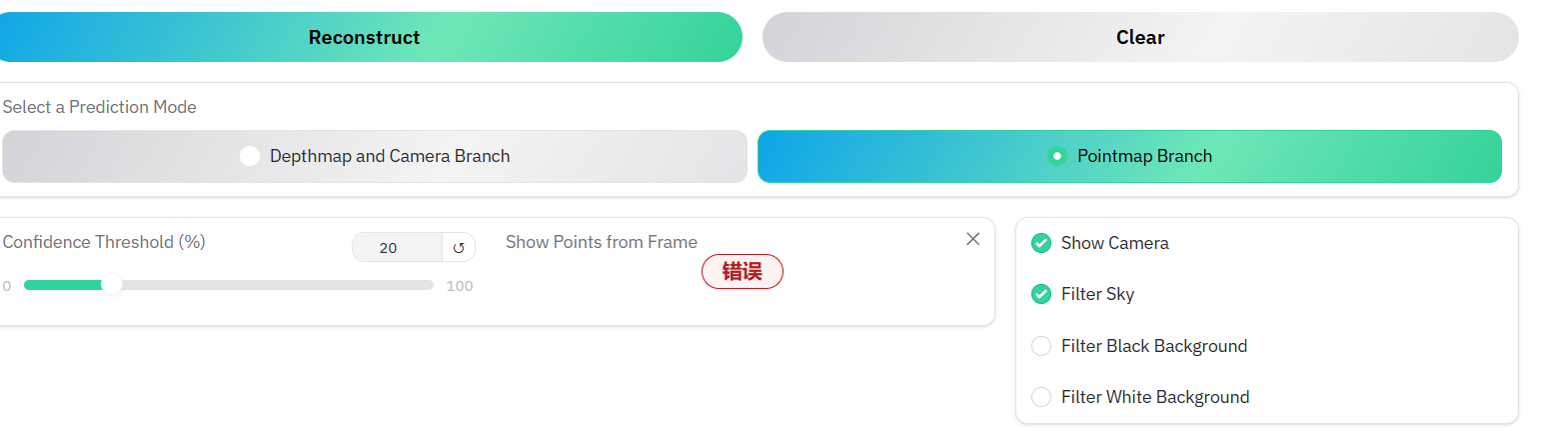
在选项中选择filter Sky如下图的时候会报错,本人认为网络问题,可以选择其他选项。

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









