




 本文介绍了Facebook提出的Octave Convolution(八度卷积),一种旨在减少计算量和显存占用的卷积方法。通过将特征图分为高频和低频部分,八度卷积在低频部分降低维度,同时保持高频信息。实验表明,这种方法在ResNet/ResNeXt系列网络中提高了性能,降低了计算复杂度,并且适用于不同类型的卷积操作。
本文介绍了Facebook提出的Octave Convolution(八度卷积),一种旨在减少计算量和显存占用的卷积方法。通过将特征图分为高频和低频部分,八度卷积在低频部分降低维度,同时保持高频信息。实验表明,这种方法在ResNet/ResNeXt系列网络中提高了性能,降低了计算复杂度,并且适用于不同类型的卷积操作。
Facebook在2019年时推出了一种新的卷积方法,叫做Octave Convolution,中文名是八度卷积。这个名字借鉴了音乐中高音低音的命名方法,来表示图像中高低频的数据。
图像和特征图的高低频表示
对于一张图片来说,低频的数据是比较平滑的部分,也就是图像的整体结构,高频的数据是那些细节的纹理,也就是边缘像素变化比较大的部分。如图1(a)所示。
图1. 图像和特征图的高低频表示
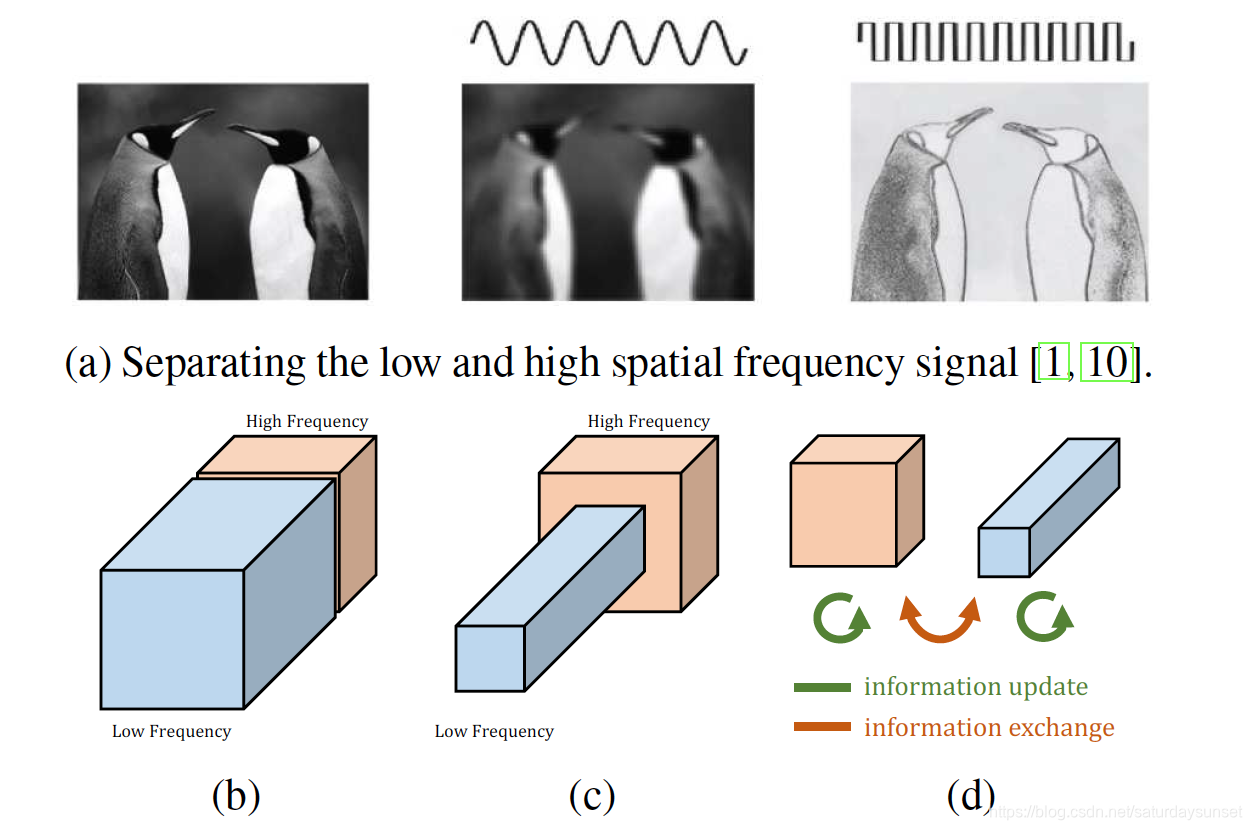
图1(a)中左图是一张企鹅的原始图片,中间是图片分离出来的低频的部分,也就是整体轮廓图,右图是图像的高频部分,也就是图片的边缘图(有点像素描)。
图1(b)是普通卷积特征图,通常情况下可以分成高频和低频两个部分。由于低频部分的特征基本上比较平滑,所以在特征图上其实不需要和高频一样的维度去表达图像的信息,如图1(c)所示,论文在低频的特征图上将宽高维度降了一半。
图1(d)表示高低频的特征信息的更新和交换,高低频的特征既有各自频率内的卷积操作,也有低频向高频和高频向低频的特征交换和融合,具体怎么操作下面会介绍。
八度卷积的操作
图2. 八度卷积的操作方式
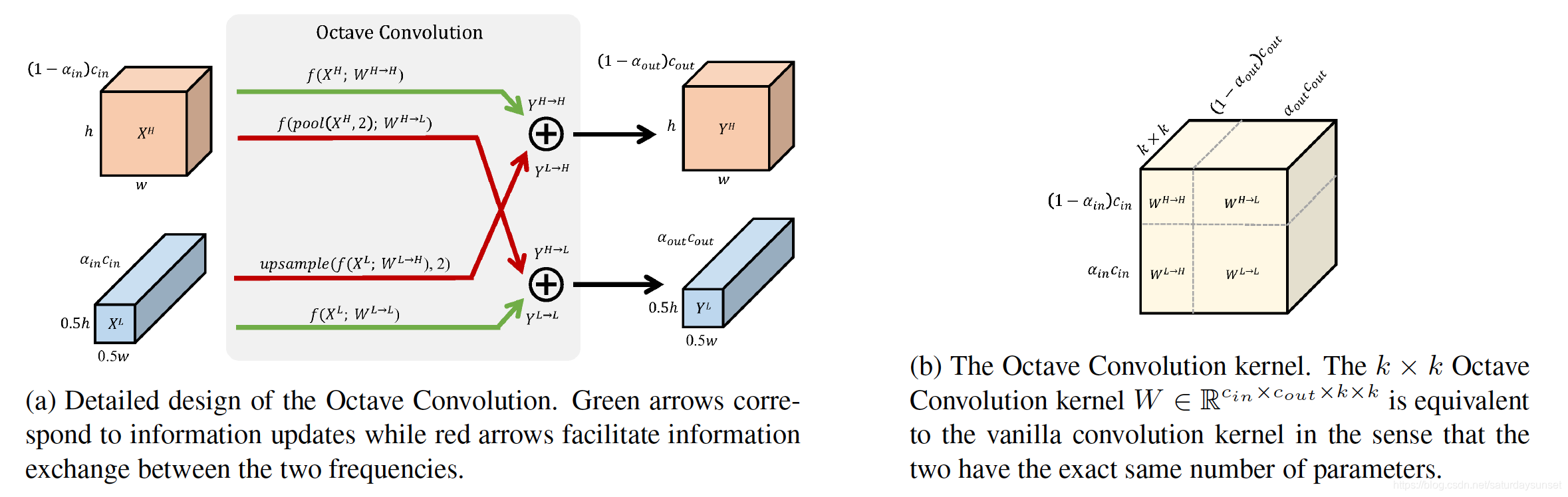
八度卷积的具体操作方式如图2(a)所示。其中αin\alpha_{in}αin和αout\alpha_{out}αout是输入和输出特征图的低频维度在总维度中的占比,在论文中一般假设αin=αout\alpha_{in}=\alpha_{out}αin=αout。图2(b)中间绿色的线表示高低频在各自频域内的卷积,卷积核分别是WH→HW^{H\rightarrow H}WH→H和WL→LW^{L\rightarrow L}W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6197
6197





 到【灌水乐园】发言
到【灌水乐园】发言







