







 BlendMask是一种结合Top-down和Bottom-up思想的实例分割方法,它在FCOS基础上增加了Bottom Module和Blender模块。实验表明,BlendMask在COCO数据集上的精度和速度优于Mask R-CNN。Blender模块融合了不同层次的特征,提高了实例分割的质量和效率。
BlendMask是一种结合Top-down和Bottom-up思想的实例分割方法,它在FCOS基础上增加了Bottom Module和Blender模块。实验表明,BlendMask在COCO数据集上的精度和速度优于Mask R-CNN。Blender模块融合了不同层次的特征,提高了实例分割的质量和效率。
论文名称:《BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation》
论文链接:https://arxiv.org/abs/2001.00309
参考代码:暂无
写在前面
BlendMask是一阶段的密集实例分割方法,结合了Top-down和Bottom-up的方法的思路。它通过在anchor-free检测模型FCOS的基础上增加了Bottom Module提取low-level的细节特征,并在instance-level上预测一个attention;借鉴FCIS和YOLACT的融合方法,作者提出了Blender模块来更好地融合这两种特征。最终,BlendMask在COCO上的精度(41.3AP)与速度(BlendMask-RT 34.2mAP, 25FPS on 1080ti)都超越了Mask R-CNN。
这篇文章的创新点不能算突出,但是实验做的很充足,优化模型的思路也很值得借鉴,最后还专门对比了下Mask R-CNN,好评~
目录
背景介绍
本文主要讨论的是密集实例分割( Dense instance segmentation),密集实例分割也同样有top-down和bottom-up两类方法。
Top-down 方法
自上而下的密集实例分割的开山鼻祖是DeepMask,它通过滑动窗口的方法,在每个空间区域上都预测一个mask proposal。这个方法存在以下三个缺点:
-
mask与特征的联系(局部一致性)丢失了,如DeepMask中使用全连接网络去提取mask
-
特征的提取表示是冗余的, 如DeepMask对每个前景特征都会去提取一次mask
-
下采样(使用步长大于1的卷积)导致的位置信息丢失
Bottom-up 方法
自下而上的密集实例分割方法的一般套路是,通过生成per-pixel的embedding特征,再使用聚类和图论等后处理方法对其进行分组归类。这种方法虽然保持了更好的低层特征(细节信息和位置信息),但也存在以下缺点:
-
对密集分割的质量要求很高,会导致非最优的分割
-
泛化能力较差,无法应对类别多的复杂场景
-
后处理方法繁琐
混合方法
本文想要结合 top-down和bottom-up两种思路,利用top-down方法生成的instance-level的高维信息(如bbox),对bottom-up方法生成的 per-pixel prediction进行融合。因此,本文基于FCOS提出简洁的算法网络BlendMask。融合的方法借鉴FCIS(裁剪)和YOLACT(权重加法)的思想,提出一种Blender模块,能够更好地融合包含instance-level的全局性信息和提供细节和位置信息的低层特征。
总体思路
BlendMask的整体架构如下图所示,包含一个detector module和BlendMask module。文中的detector module直接用的FCOS,BlendMask模块则由三部分组成:bottom module用来对底层特征进行处理,生成的score map称为Base;top layer串接在检测器的box head上,生成Base对应的top level attention;最后是blender来对Base和attention进行融合。
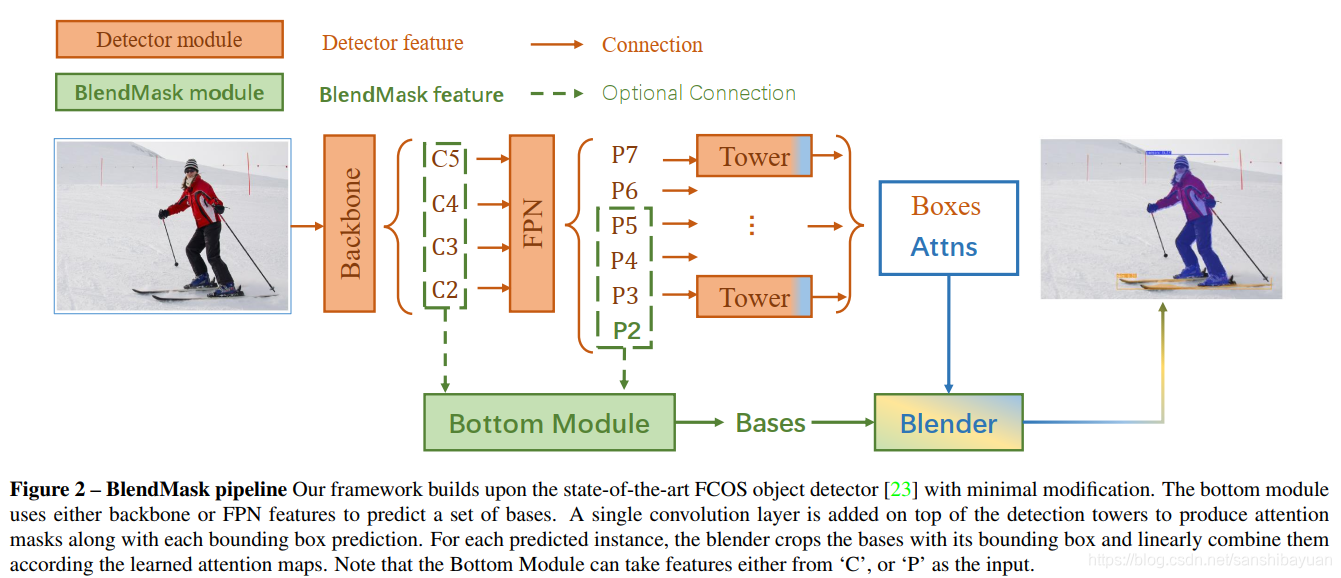
Bottom Module
这部分的结构类似FCIS和YOLACT,输入为 的低层特征,由骨干网络或FPN输出。通过一系列的decode(上采样和卷积),生成score maps,称为Base(B)。文中使用的是DeeplabV3+的decoder,其他分割网络的decoder同样适用。
上式中的N为batch size,K为Base的数量,H和W是输入图像的大小,s则是Base的输出步长。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









