




 本文详细介绍了Feature Pyramid Networks (FPN)的原理和在目标检测中的应用,包括其自下而上、自上而下及横向连接的网络结构,以及在Faster R-CNN中的改进,探讨了FPN如何有效提高多尺度目标检测的性能,特别是对小目标检测的提升。
本文详细介绍了Feature Pyramid Networks (FPN)的原理和在目标检测中的应用,包括其自下而上、自上而下及横向连接的网络结构,以及在Faster R-CNN中的改进,探讨了FPN如何有效提高多尺度目标检测的性能,特别是对小目标检测的提升。
论文名称:《Feature Pyramid Networks for Object Detection》
论文链接:https://arxiv.org/abs/1612.03144
参考代码(非官方):https://github.com/jwyang/fpn.pytorch(Pytorch实现)
综述
多尺度目标检测是计算机视觉领域的一个基础且具挑战性的课题,尤其是在目标检测方面。下图是目前常用的四种多尺度处理方法。
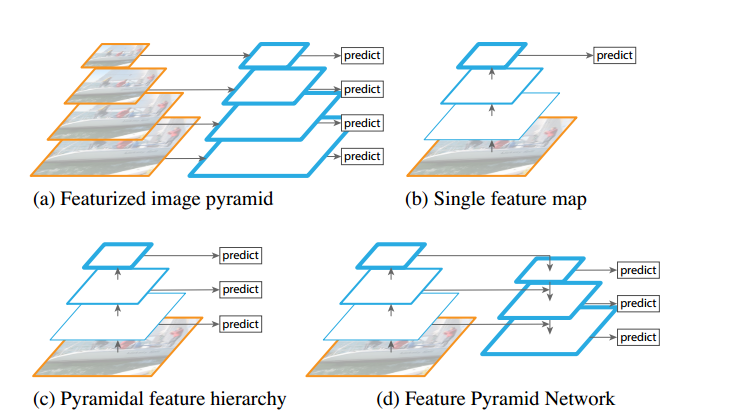
-
特征金字塔
特征金字塔是在图像金字塔基础上构建构建形成的,这种方法早期使用在人工提取的特征上。随着深度学习的流行,深度卷积特征成为主流。特征金字塔结构的优势是可以产生多尺度的特征,其中每一层都是语义信息加强的,包括高分辨率的低层。但这样的方法需要很高的时间及计算量消耗,难以在实际中应用。 -
特征最上层进行预测
由于CNN在计算的时候本身就存在多级特征图,不同层的特征图尺度也不同,天然形成了金字塔结构,其中最上层的特
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









