




 本文深入探讨了XML和JSON这两种流行的数据存储与交换格式。详细介绍了XML的文档结构、优势、命名空间、解析方法(DOM、SAX、JDOM、DOM4J),以及如何使用DOM进行数据读取和维护。同时,概述了JSON的语法规则,以及如何使用FastJson进行Java对象与JSON字符串的转换。
本文深入探讨了XML和JSON这两种流行的数据存储与交换格式。详细介绍了XML的文档结构、优势、命名空间、解析方法(DOM、SAX、JDOM、DOM4J),以及如何使用DOM进行数据读取和维护。同时,概述了JSON的语法规则,以及如何使用FastJson进行Java对象与JSON字符串的转换。
XML技术
任务1使用XML存储数据
关键步骤如下。
➢了解XML文档结构。
➢编写格式良好的XML文档。
➢编写保存图书信息的XML文档。
认识 XML
XML是Extensible Markup Language即可扩展标记语言的缩写,是一种简单的数据存储语言,使用一系列简单的标记来描述数据。XML技术应用广泛,最基本的如网站、应用程序的配置信息一般都采用XML文件描述。
特点
➢XML与操作系统、编程语言的开发平台无关
➢实现不同系统之间的数据交换
➢规范统一。
作用
➢数据交互
➢配置应用程序和网站
➢Ajax基石
XML 文档结构
<?xml version="1.0" encoding="UTF-8"?>
<books>
<!--图书信息-->
<book id="bk101">
<author>王姗</author>
<title> .NET高级编程</title>
<description>包含C#框架和网络编程等</description>
</book>
<book id="bk102">
<author>李明明</author>
<title>XML基础编程</title>
<description>包含XML基础概念和基本用法</description>
</book>
</books>
1.XML声明
<?xml version="1.0" encoding="UTF-8"?>表示XML声明,用以标明该文件是一个XML文档。XML文档总是以XML声明开始,它定义了XML的版本和使用的编码格式等信息。XML 声明由以 下几个部分组成。
➢version: 文档符合XML 1.0规范。
➢encoding:文档字符编码,默认为“UTF-8”。
对于任何一个XML文档,其声明部分都是固定的格式。
2.标签
在XML中,用尖括号<>括起来的各种标签(Tag) 来标记数据,标签需成对使用来界定字符数据,例如,< author> 王娜< /author >这对标签中, < author>是开始标签, < /author>是结束标签,“ 王姗”是标签描述的内容,表示作者信息。XML文件可以包含任意数量的标签。
3. 根元素
每个XML文档必须有且仅有一个根元素,如< books >< /books>
根元素的特点如下。
➢根元素是一个完全 包括文档中其他所有元素的元素。
➢根元素的起始标签要放在所有其他元素的起始标签之前。
➢根元素的结束标签要放在所有其他元素的结束标签之后。
4. 元素
XML文档的主要部分是元素,元素由开始标签、元素内容和结束标签组成。元素内容可以包含子元素、字符数据等。如< author>王姗< /author>就是一个元素。
元素的命名规则如下。
➢名称中可以包含字母、数字或者其他字符。
➢名称不能以数字或者标点符号开始。
➢名称不能以字符xml(或者XML、Xml)开始。
➢名称中不能包含空格。
注意
①XML标签必须成对出现并正确嵌套,如下面的嵌套方式是不正确的。
<?xml version="1.0" encoding="UTF-8" ?>
<title>
<name>
XML编程
</title>
</name>
②元素允许是空元素,如以下元素的写法是允许的。
<title></title>
<title></title>
<title/>
5.属性
在描述图书信息的XML文档中,标签使用id属性描述图书的编号信息。
属性定义语法格式如下。
<元素名 属性名="属性值">
注意
(1)一个元素可以有多个属性,它的基本格式为<元素名 属性名= “属性值” 属性名="属性值“/>,多个属性之间用空格隔开.
(2)属性值中不能直接包含<、”、 &等字符。
(3)属性可以加在任何一个元素的起始标签上,但不能加在结束标签上,
6.XML中的特殊字符的处理
在XML中,有时在元素的文本中会出现一些特殊字符 (如<、>、’、"、&),而XML文档结构本身就用到了这几个特殊字符,有以下两种办法,可以正确地解析包含特殊字符的内容。
(1)对这5个特殊字符进行转义,也就是使用XML中的预定义实体代替这些字件XML中的预定义实体和特殊字符的对应关系
| 实体名称 | 字符 |
|---|---|
| &It; | < |
| > | > |
| & | & |
| " | " |
| ' | ’ |
(2)如果在元素的文本中有大量的的特殊字符,可以使用CDATA节处理。CDATA节中的所有字符都会被当作元元素字符数据的常量部分,而不是XML标签,定义CDATA节的语法格式如下。
<![CDATA[
要显示的字符
]]
7.XML中的注释
注释的语法格式如下。
<!--注释内容-->
8.格式良好的XML文档
格式良好的XML文档儒要遵循如下规则
➢必须有 XML声明语句。
➢必须有且仅有一个根元素 。
➢标签大小写 敏感。
➢属性值用双引号包含起来。
➢标签成对出现。
➢元素正确嵌套。
练习:将如下衣服的尺码信息,使用XML文件保存
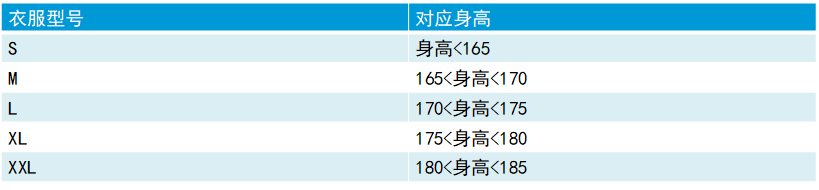
<?xml version="1.0" encoding="UTF-8" ?>
<sizes>
<size id="S">
<!--<range>height <165</range>-->
<min>0</min>
<max>165</max>
</size>
<size id="M">
<min>165</min>
<max>170</max>
</size>
<size id="L">
<min>170</min>
<max>175</max>
</size>
<size id="XL">
<min>175</min>
<max>180</max>
</size>
<size id="XXL">
<min>180</min>
<max>300</max>
</size>
</sizes>
练习:编写XML表示学生成绩
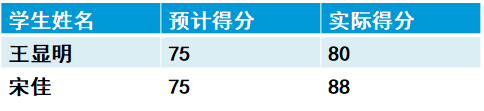
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<studet name="王显明" yujidefen="75" fenshu="80"></studet>
<studet name="宋佳" yujidefen="75" fenshu="88"></studet>
</students>
XML优势
XML独立于计算机平台、操作系统和编程语言来表示数据,凭借其简单性、可扩展性、交互性和灵活性在计算机行业中得到了世界范围的支持持和采纳。XML基于文本格式,允许开发人员描述结构化数据#在各种应用之间发送和交换这些数据,使得不同系统之间交互数据具备了统一的格式。
XML的优势主要体现在以下几点。
➢数据存储: XML与Oracle和SQL Server 等数据库一样, 都可以实现数据的持久化存储。XML极其简单,正是这点使得XML与众不同。
➢数据交换:在实际应用中,由于各个计算机所使用的操作系统、数据库不同,因此数据之间的交换很复杂。现在可以使用XML来交换数据,例如可以将数据库A中的数据转换成标准的XML文件,然后数据库B再将该标准的XML文件转换成适合自己数据要求的数据,以达到交换数据的目的。再比如,气象部门发布了天气预报信息,不同的系统(计算机、手机)以及不同的软件(QQ、MSN)和各种网站都可以去读取和显示这些信息,正是因为天气预报信息以XML格式存储,才使得不同系统、不同软件都能解析统格式的数据并显示。
➢数据配置:许多应用都将配置数据存储在XML文件中。
XML 中的命名空间
命名空间在XML文档中可以用作元素或属性名称的名称集合,它们用来标识来自特定域(标准组织、公司、行业)的名称。
1.命名空间的必要性
XML解析器在解析XML文档时,对于重名的无素,可能出现解析冲突。命名空间有助于标准化元素和属性,并为它们加上唯一的标识。
2.声明命名空间
声明命名空间的语法格式如下。
xmlns:[prefix]="[命名空发空间的URI]"
➢prefix是前缀名称,它用作命名空间的别名。
➢xmlns是保留属性。
3.属性和命名空间
除非带有前缀,否则属性属于它们的元素所在的命名空间。
4. 命名空间的应用
示例 1
在XML中使用命名空间。
关键代码:
<?xml version="1.0" encoding="gb2312" ?>
<cameras xmlns:digital="http://www.digicam.org" xmlns:photo="http://www.photostudio.org">
<dgital:camera prodID="P663"
name="傻瓜相机"
pixels="410000"
output_res="640 x 480"
int_mem="2 MB"
price="300.99"/>
<photo:camera productID="K29B3"
name="超级35毫米照相机"
lens="35毫米"
zoom="70毫米"
warranty="1年"
price="99.00"/>
</cameras>
在示例1代码中,声明了两个命名空间,别名分别是digital和photo。对应的UPI分别是http:.//www.digicam.org和htp://www.photostudio.org,第一个camera加上了前缀digital,则它属于digital代表的命名空间,第二个camera加上了前缀photo,则它属于photo代表的命名空间。这样,就使得数据更加精确。
至此,通过任务1,我们认识了XML文档的结构,学会了如何编写格式良好的XML文档。
任务 2) XML文档的验证
关键步骤如下。
➢使用DTD验证XML文档。➢使用Schema验证XML文档。
23:53:50
XML 解析
在实际应用中,经常需要对XML文档进行各种操作。例如,在应用程序启动时读取XML配置文件信息,或者把数据库中的内容读取出来转换为XML文档形式,这时都会用到XML文档的解析技术。
目前常用的XML解析技术有4种。
(1) DOM
基于XML文档树结构的解析
适用于多次访问的XML文档
特点:比较消耗资源
(2) SAX
基于事件的解析
适用于大数据量的XML文档
特点:占用资源少,内存消耗小
(3) JDOM
JDOM的目的是直接为Java编程服务,利用纯Java技术对XML文档实现解析、生成、序列化及其他操作,把SAX和DOM的功能有效结合起来,简化与XML的交互并且比使用DOM更快。JDOM与DOM有两方面不同,首先,JDOM仅使用具体类而不使用接口,这在某些方面简化了API,但是也限制了灵活性;其次,API 大量使用了Collections类,简化了那些已经熟悉这些类的Java开发者的使用。JDOM的优势在于“使用20%的精力解决80%Java/XML的问题”。
(4) DOM4J
非常优秀的Java XML API
性能优异、功能强大
开放源代码
使用DOM读取XML数据
1. DOM概念
DOM是Document Object Model即文档对象模型的简称,DOM把XML文件映射成一棵倒挂的“树”, 以根元素为根节点,每个节点都以对象形式存在。通过存取这些对象就能够存取XML文档的内容。
例如,在C盘创建文件book.xml并保存,book .xml的结构如图所示。
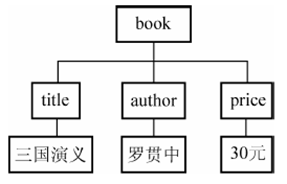
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>三国演义</title>
book
<author>罗贯中</author>
<price>30元</price>
</book>
Oracle公司提供了JAXP(Java API for XML Processing)来解析XML。JAXP会把XML文档转换成一个DOM树。JAXP包含3个包,这3个包都在JDK中:
➢org.w3c.dom: W3C推荐的用于使用DOM解析XML文档的接口。

➢org.xml.sax:用于使用SAX解析XML文档的接口。
➢javax.xml.parsers:解析器工厂工具,程序员获得并配置特殊的分析器。
DOM解析使用到的类都在这些包中,在使用DOM解析XML时需要导入这些包中相关的类。
2.使用DOM读取手机收藏信息
使用DOM解析XML文档的步骤如下。
(1)创建解析器工厂对象,即DocumentBuilderFactory对象。
(2)由解析器工厂对象创建解析器对象,即DocumentBuilder对象。
(3)由解析器对象对指定的XML文件进行解析,构建相应的DOM树,创建Document 对象。
(4) 以Document对象为起点对DOM树的节点进行增加、删除、修改、查询等操作。
下面通过示例3学习使用DOM读取XML数据。
示例3
使用DOM读取手机收藏信息中的品牌和型号信息,XML文档代码如下。
<?xml version="1.0" encoding="GB2312"?>
<PhoneInfo>
<Brand name="华为">
<Type name= "U8650"/>
</Brand>
<Brand name="苹果">
<Type name="iPhone4"/>
<Type name= "iPhone5"/>
</Brand>
</PhoneInfo>
关键代码:
//得到DOM解析器的工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//从DOM工厂获得DOM解析器
DocumentBuilder db = dbf.newDocumentBuilder();
//解析XML文档,得到一个Document对象,即DOM树
Document doc = db.parse("src/AAA.xml");//收藏信息.xml 为保存手机收藏信息的 xml文档
//得到所有Brand节点列表信息
NodeList brandList = doc.getElementsByTagName("Brand");
//循环Brand信息
for (int i = 0; i < brandList.getLength(); i++) {
//1获取第i个Brand元素信息
Node brand = brandList.item(i);
//获取第i个Brand元素的name属性的值
Element element = (Element) brand;
String attrValue = element.getAttribute("name");
//获取第i个Brand元素的所有子元素的name属性值NodeList types- -element.getChildNodesO;
for (int j = 0; j < types.getLength(); j++) {
Element typeElement = ((Element) types.item(j)); //Type节点
String type =typeElement.getAttribute("name");//获得手机型号
System.out.println("手机: " + attrValue + type);
}
}
使用DOM解析XML时主要使用到以下对象。
- Document对象
Document对象代表整个XML文档,所有其他的节点(Node) 都以一定的顺序包含在Document对象之内,排列成一个树状结构,可以通过遍历这棵“树”来得到XML文档的所有内容。它也是对XML文档进行操作的起点,人们总是先通过解析XML源文件得到一个Document对象,然后再来执行后续的操作。Document 对象的主要方法如下。➢getElementsByTagName(String name):返回一个NodeList对象,它包含了所有指定标签名称的标签。
➢getDocumentElement():返回一个代表这个DOM树的根节点的Element对象,也就是代表XML文档根元素的对象。 - NodeList 对象
顾名思义,NodeList 对象是指包含了一个或者 多个节点的列表。可以简单地把它看成一个Node数组,也可以通过方法来获得列表中的元素,NodeList对象的常用方法如下。➢getLength(): 返回列表的长度。
➢item(int index):返回指定位置的Node对象。 - Node对象
Node对象是DOM结构中最基本的对象,代表了文档树中的一个抽象节点。在实际使用时,很少会真正用到Node对象,一般 会用Element、 Text 等Node对象的子对象来操作文档。Node对象的主要方法如下。
➢getChildNodes(): 此节点包含的所有子节点的NodeList。
➢getFirstChild(): 如果节点存在子节点,则返回第一个子节点。
➢getLastChild(); 如果节点存在子节点,则返回最后一个子节点。
➢getNextSibling(): 返回DOM树中这个节点的下一个兄弟节点。
➢getPreviousSibling(): 返回DOM树中这个节点的上一个兄弟节点。
➢getNodeName(): 返回节点的名称。
➢getNodeValue(): 返回节点的值。
➢getNodeType():返回节点的类型。 - Element对象
Element对象代表XML文档中的标签元素,继承自Node,也是Node最主要的子对象。在标签中可以包含属性,因而Element对象中也有存取其属性的方法。
➢gerAttribute(String attributename):返回标签中指定属性名称的属性的值。➢getElementsByTagName(String name):返回具有指定标记名称的所有后代Elements的NodeList。
注意
XML文档中的空白字符也会被作为对象映射在DOM树中。因而,直接调用Node对象的getChildNodes()方法有时候会有些问题,有时不能够返回所期望的NodeList元素对象列表。
解决的办法如下。
①使用Element的getElementsByTagName(String name)返回的NodeList就是所期待的对象。然后,可以用item() 方法提取想要的元素。
②调用Node的getChildNodes() 方法得到NodeList对象,每次通过item()方法提取Node对象后判断node.getNodeType()==Node.ELEMENT_NODE,即判断是否是元素节点,如果为true,则表示是想要的元素。
示例4
使用DOM读取手机新闻中的发布日期,XML 文档代码如下。
<?xml version="1.0" encoding="GB2312"?>
<PhoneInfo>
<Brand name="华为">
<Type name="U8650">
<Item>
<title>标题信息</title>
<link>链接</link>
<description>描述</description>
</Item>
</Type>
</Brand>
</PhoneInfo>
关键代码:
//得到DOM解析器的工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//从DOM工厂获得DOM解析器
DocumentBuilder db = dbf.newDocumentBuilder();
//解析XML文档,得到一个DOM对象,即DOM树
Document doc = db.parse("src/ 收藏信息.xml");
//读取pubDate
NodeList list = doc.getElementsByTagName("pubDate");
//pubDate 元素节点
Element pubDateElement = (Element) list.item(0);
//读取文本节点
String pubDate = pubDateElement.getFirstChild().getNodeValue();
System.out.println(pubDate);
在示例4代码中, String pubDate=pubDateElement. getfirstChild().getNodeValue();用于获取pubDate节点的文本值。
使用DOM读取 XML 其实是对 Document、 NodeList.、Node、 Element 等几个重要对象的灵活运用。
使用DOM维护XML数据
在XML应用中需要经常对数据进行维护,首先来学习如何在XML文档中添加据。
1.添加手机收藏信息
要实现添加手机收藏信息,其实就是在DOM树上添加新的节点对象,然后对树对应的文档进行保存就可以了。
示例5
在示例3的XML文档中添加品牌为“MOTO", 型号为“A1680”的手机收藏信息。
分析如下。
首先,根据收藏信息在内存中构建出它的DOM树要在PhoneInfo的节点上添加品牌节点,需要先找到PhoneInfo节点。然后在此DOM树上创建个新的Brand品牌节点,设置它的属性name为“MOTO”。然后根据它在DOM树的位置,把它添加为PhoneInfo的子节点。这样,此DOM树就有了新的结构,把这个DOM树结构保存到XML文件就可以了。
实现步骤如下。
(1)为XML文档构造DOM树。
(2)创建新节点,并设置name属性。
(3)把节点加到其所属父节点上。
(4)保存XML文档。
关键代码:
//得到DOM解析器的工厂实例
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//从DOM工厂获得DOM解析器
DocumentBuilder db = dbf.newDocumentBuilder();
//解析xml文档,得到一个Doumet对象,即DOM树
Document doc = db.parse("src/信息收藏.xml");
//创建Brand节点
Element brandElemen = ((org.w3c.dom.Document) doc).createElement("Brand");
brandElement.setAttribute("name", "MOTO");
//创建Type节点
Element typeElement = doc.createElement("TYpe");
typeElement.setAttribute("name", "A1680");
//添加父子关系
brandElement.appendChild(typeElement);
Element phoneElement = (Element) doc.getElementsByTagName("PhoneInfo").item(0);
phoneElement.appendChild(brandElement);
//保存XML文件
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer tansformr = transformerFactory.newTransformer();
DOMSource domSource = new DOMSource(doc);
//设置编码类型
transformer.setOutputproperty(OutputKeys.ENCODING, "gb2312");
StreamResult result = new StreamResult(new FileOutputStream(" src/信息收藏.xml"));
//把DOM树转换为XML文件
transformer.transform(domSource, result);
2.修改手机收藏信息
示例6
将保存手机收藏信息的XML文档中的手机品牌信息MOTO修改为“摩托罗拉”。
分析如下。
手机收藏信息的修改操作仍然要先构建DOM树,要把品牌信息MOTO修改为“摩托罗拉”,先要找到属性为MOTO的Brand节点,然后把namne属性设置为“摩托罗拉”,最后将DOM树的修改保存到XML文件中。
实现步骤如下。
(1)为XML文档构造DOM树。
(2)找到符合修改条件的节点。
(3)设置该节点的属性为修改值。
(4)保存XML文档。
关键代码:
//省略构建DOM树的代码
//找到修改的节点
NodeList list = doc.getElementsByTagName("Brand");
for (int i = 0; i < list.getLength(); i++) {
Element brandElement = (Element) list.item();
String brandName = brandElement.getAttribute("name");
if (brandName.equals("MOTO")) {
brandElemet.setAttribute("name", "摩托罗拉"); //1 修改属性值
}
}
//省略保存 XML文件的代码
3. 按手机品牌和型号删除收藏信息
示例7
从保存手机收藏信息的XML文档中,删除手机品牌信息“摩托罗拉”。
分析如下。
手机收藏信息的删除操作也要先构建DOM树,在DOM树中找到name属性为“摩托罗拉”的品牌节点,然后删除,这时需要先找到要删除节点的父节点,通过Brand节点的父节点PhoneInfo去实现最终的删除功能。
实现步骤如下。
(1)为XML文档构造DOM树。
(2)找到符合删除条件的节点。
(3)找到该节点的父节点实现其子节点的删除功能。
(4)保存XML文档。
关键代码:
// 省略构建DOM树的代码
//找到删除的节点
NodeList list doc.getElementsByTagName("Brand");
for (int i = 0; i < list.getLength(); i++) {
Element brandElement = (Element) list.item();
String brandName brandElement getribut name ");
if (brandName.equals("摩托罗拉") {
brandElement.getParentNode().removeChild(brandElement);
//省略保存XML文件的代码
}
}
使用DOM对XML数据进行添加、修改和删除的操作步骤基本一样, 只是使用的类及方法有些不同。再次强调,通过本任务。需要理解DOM常见对象的用法,掌握使用DOM解析XML的步骤。
JSON简介
1.JSON(JavaScript Object Notation)是JavaScript中的对象表示法
2.轻量级的文本数据交换格式,独立于JavaScript语言
3.具有自我描述性
4.比XML传输速度快
JSON语法规则
1.数据由名称/值对构成
2.数据之间由逗号分隔
3.大括号内为对象
4.中括号内为数组
{
"name":"jason",
"age":20,
"skills":["Java","Hadoop","Python"]
}
FastJson简介
由阿里开源的JSON解析框架
下载地址:
http://central.maven.org/maven2/com/alibaba/fastjson/1.2.47/fastjson-1.2.47.jar
Java对象转为JSON字符串
class Student{
private String name="";
private int age;
private List<String> skills;
public Student(String name, int age, List<String> skills) {
this.name = name;
this.age = age;
this.skills = skills;
}
……//省略getter和setter
}
Student stu=new Student("Jason",20,
Arrays.asList("Java", "Hadoop", "Python"));
String stuJson=com.alibaba.fastjson.JSON.toJSON(stu).toString();
System.out.println(stuJson);
JSON字符串转为Java对象
String json="{
\"skills\":[\"Java\",\"Hadoop\",\"Python\"],
\"name\":\"Jason\",
\"age\":20
}";
Student stuNew= com.alibaba.fastjson.JSON.parseObject(json,Student.class);
System.out.println(stuNew.getName());

















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









