




 本文介绍了一种用于3D点云完整性的PointFractalNetwork (PF-Net) 源码,包括数据集下载、CPU和GPU环境设置,以及如何运行模型进行训练。重点讲解了如何在不同环境(CPU/GPU)下安装依赖并配置权重路径。
本文介绍了一种用于3D点云完整性的PointFractalNetwork (PF-Net) 源码,包括数据集下载、CPU和GPU环境设置,以及如何运行模型进行训练。重点讲解了如何在不同环境(CPU/GPU)下安装依赖并配置权重路径。

下载数据集
https://pan.baidu.com/s/1MavAO_GHa0a6BZh4Oaogug 提取码:3hoe cpu环境
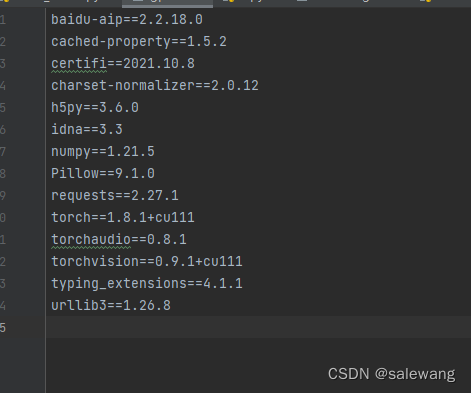
baidu-aip==2.2.18.0
cached-property==1.5.2
certifi==2021.10.8
charset-normalizer==2.0.12
h5py==3.6.0
idna==3.3
numpy==1.21.5
Pillow==9.1.0
requests==2.27.1
torch==1.11.0
torchvision==0.12.0
typing_extensions==4.1.1
urllib3==1.26.8
gpu 环境
cuda 11.1的
安装 torch 记得去测能不能加速
pip3 install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio===0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
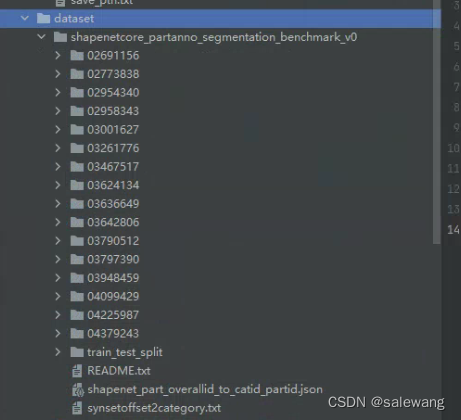
数据这么放 shapenetcore_partanno_segmentation_benchmark_v0
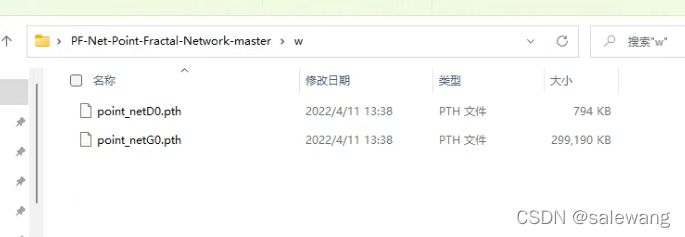
创一个文件夹放权重
修改 把1,2 该 为0
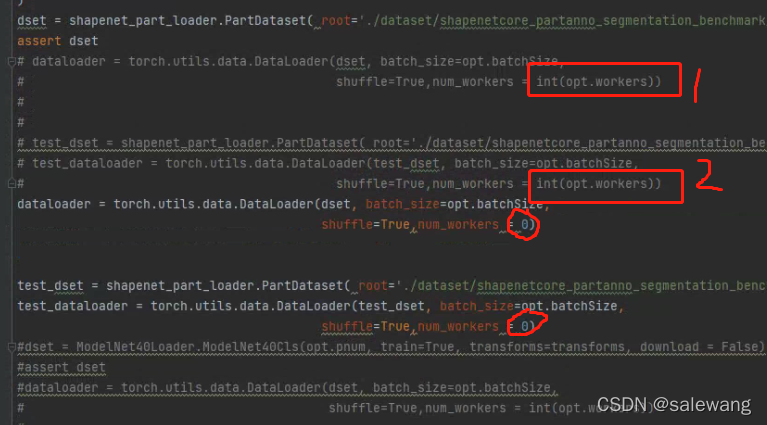
或者加入 if __name__ == '__main__':
if __name__ == '__main__':(这个地方加入if __name__ == '__main__':)
dset = shapenet_part_loader.PartDataset( root='./dataset/shapenetcore_partanno_segmentation_benchmark_v0/',classification=True, class_choice=None, npoints=opt.pnum, split='train')
assert dset
dataloader = torch.utils.data.DataLoader(dset, batch_size=opt.batchSize,
shuffle=True,num_workers = int(opt.workers))
test_dset = shapenet_part_loader.PartDataset( root='./dataset/shapenetcore_partanno_segmentation_benchmark_v0/',classification=True, class_choice=None, npoints=opt.pnum, split='test')
test_dataloader = torch.utils.data.DataLoader(test_dset, batch_size=opt.batchSize,
shuffle=True,num_workers =int(opt.workers))修改权重路径
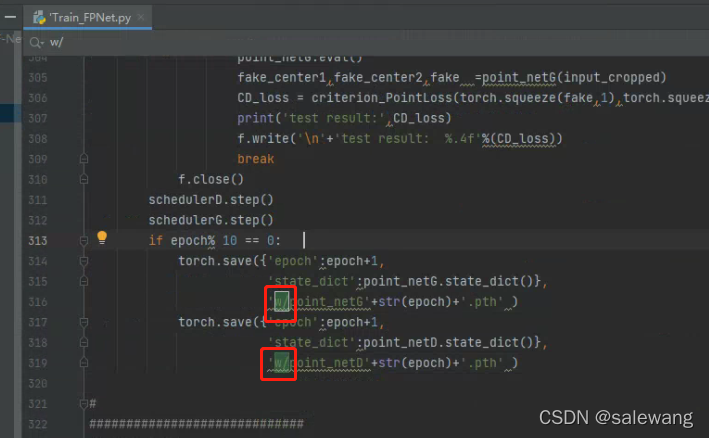
右键 run 就可以了 这是cpu的
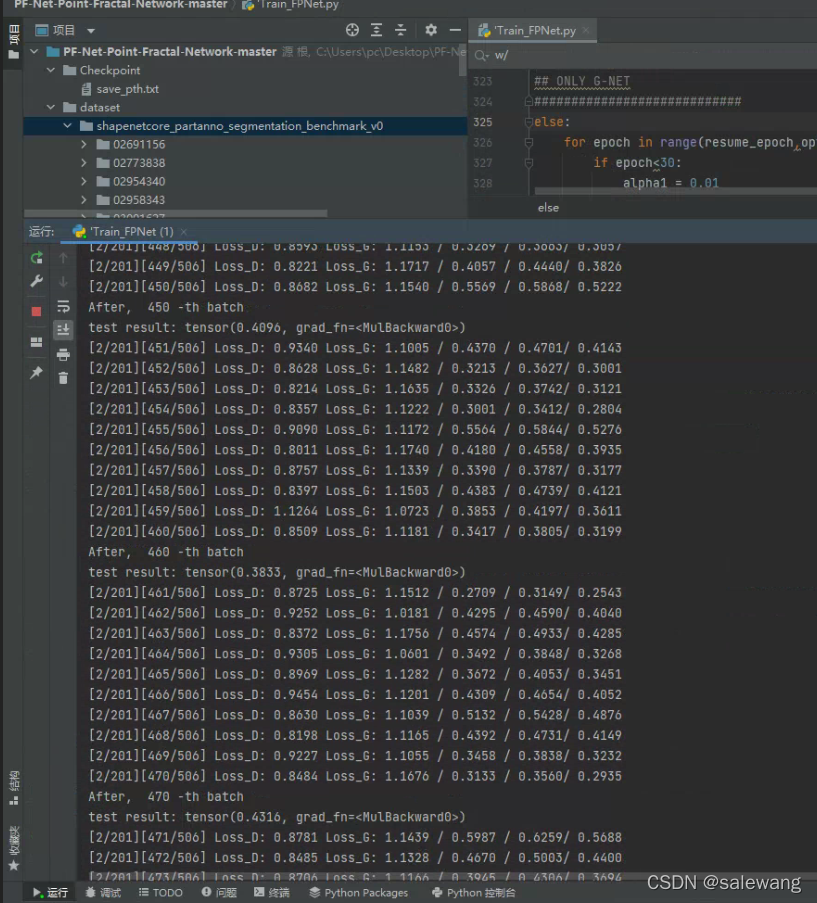
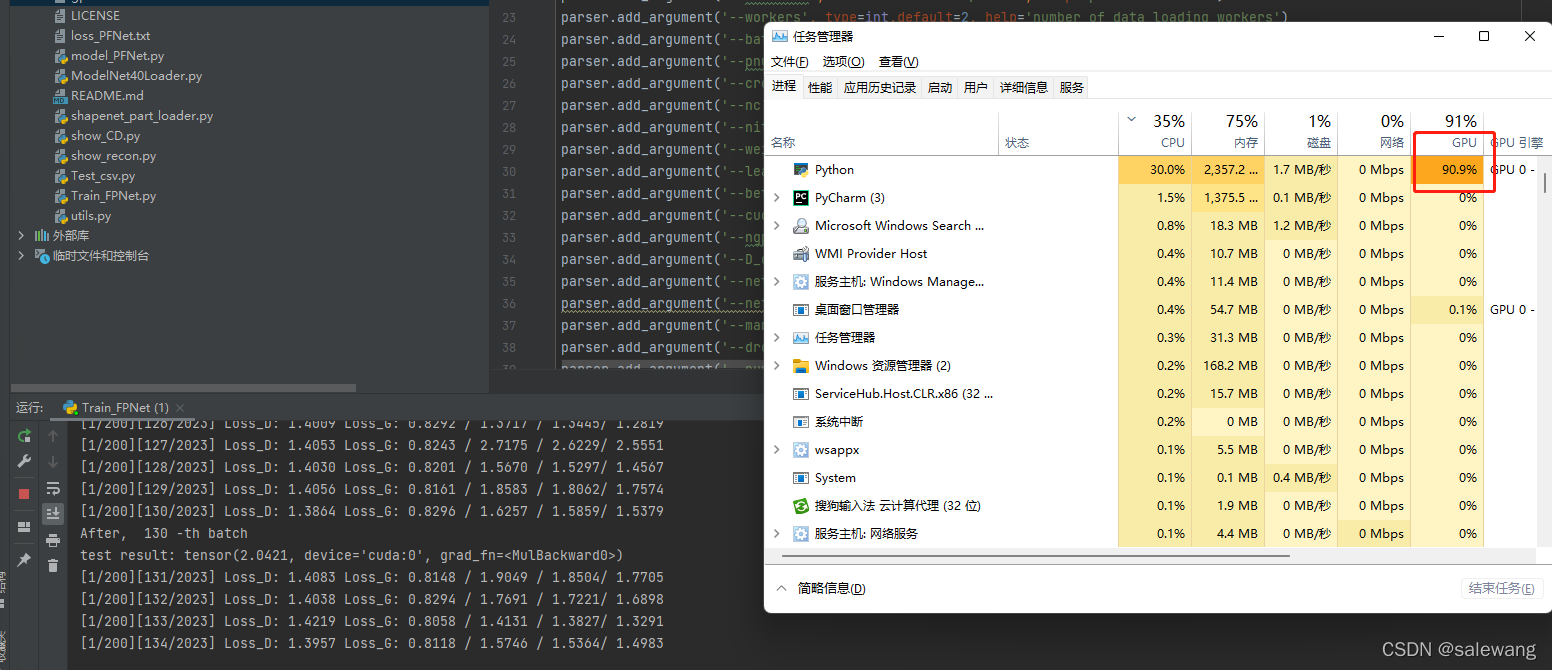
还在训练中。
gpu
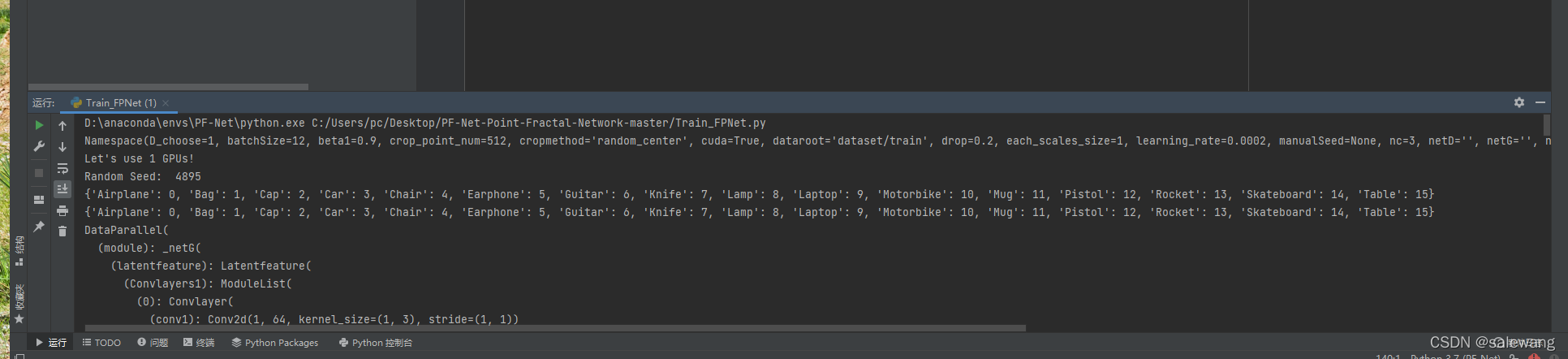
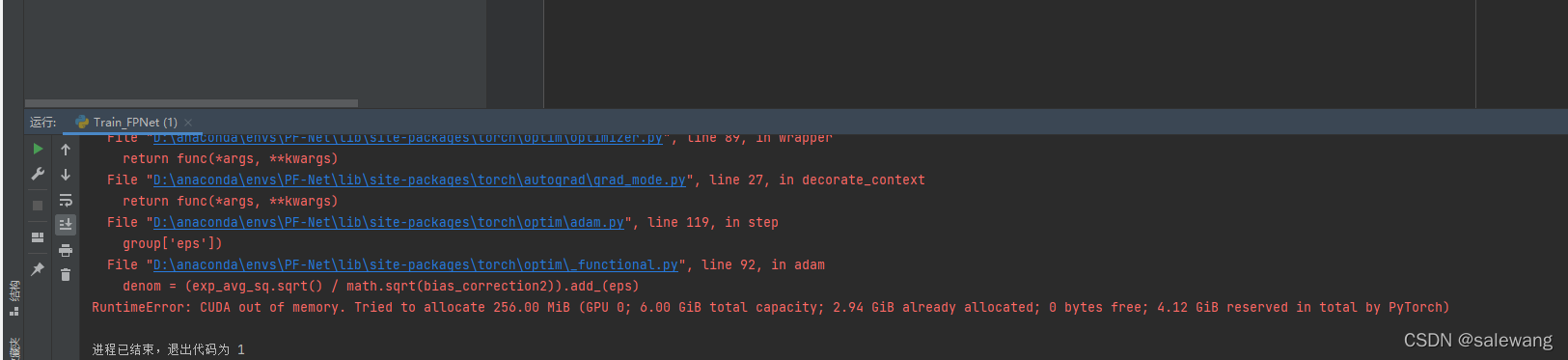
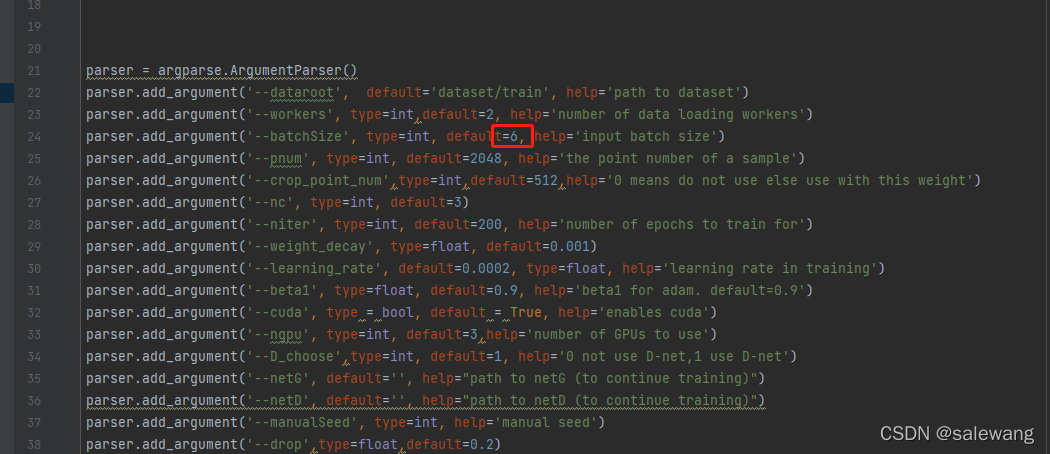
内存不够 GPU对2的幂次的batch可以发挥更佳的性能(我的电脑太小了跑的太慢了)
代写中(等我训练好)


















 1795
1795









 到【灌水乐园】发言
到【灌水乐园】发言









