




目录
第三章(下)来了~觉得还不错的小伙伴可以点赞收藏关注一下,持续更新ing
3.4 外部存储器
外部存储器作为计算机的 “大仓库”,用于长期存储大量的数据和程序,弥补了主存容量的不足。主要的外部存储器包括磁盘存储器和固态硬盘。
3.4.1 磁盘存储器
磁盘存储器 (magnetic disk storage) 是一种利用磁记录技术在涂有磁记录介质的旋转圆盘上进行数据存储的辅助存储器。它就像是一个巨大的图书馆书架,不同的磁道和扇区如同书架上的不同位置,用于存放数据。磁盘存储器具有存储容量大、数据传输率高、存储数据可长期保存等特点。在计算机系统中,常用于存放操作系统、程序和数据,是主存储器的扩充。
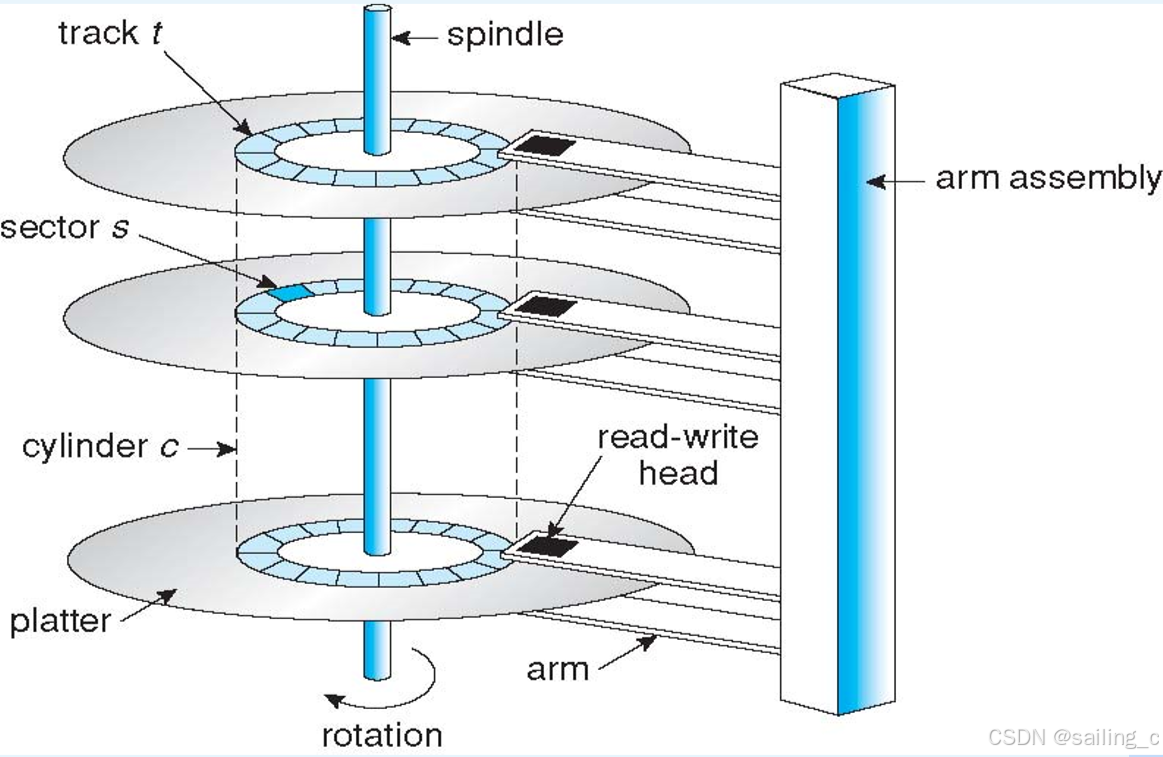
磁盘存储器通常由磁盘、磁盘驱动器 (或称磁盘机) 和磁盘控制器构成。磁盘两面涂有可磁化介质的平面圆片,数据按闭合同心圆轨道记录在磁性介质上,这种同心圆轨道称磁道。其主要技术参数记录密度包括位密度、道密度和面密度。位密度指盘片同心圆轨道上单位长度上记录多少位单元,用位 / 毫米 (bpmm) 表示;道密度是指记录面径向每单位长度上所能容纳的磁道数,常用道 / 毫米 (tpmm) 表示;面密度是指记录面上单位面积所记录的位单元,常用位 / 毫米 ² 表示。磁盘的存储容量是磁盘上所能记录二进制数码的总量,常用千字节 (KB) 或兆字节 (MB) 来表示。存取时间包括磁头从一道移到另一道所需的时间、磁头移动后的稳时间、盘片旋转等待时间、磁头加载时间,常用毫秒 (ms) 表示。误码率指在向设备写入一批数据并回读后,所检出的错误位数与这一批数据总位数的比值。
例如,一个普通的机械硬盘,可能有 500GB 甚至 1TB 的存储容量,其转速常见的有 5400 转 / 分钟或 7200 转 / 分钟,转速影响着数据的读取速度。在读取数据时,磁头需要寻找到对应的磁道和扇区,这个过程就涉及到前面提到的存取时间等参数。
3.4.2 固态硬盘
固态硬盘(Solid State Drive,简称 SSD),是一种基于闪存技术的存储设备,它没有传统机械硬盘的旋转部件,数据存储在闪存芯片中。相比磁盘存储器,固态硬盘具有读写速度快、抗震性强、能耗低、无噪音等优势,就像是一个高效的智能仓库,能够快速地响应数据的存取请求。
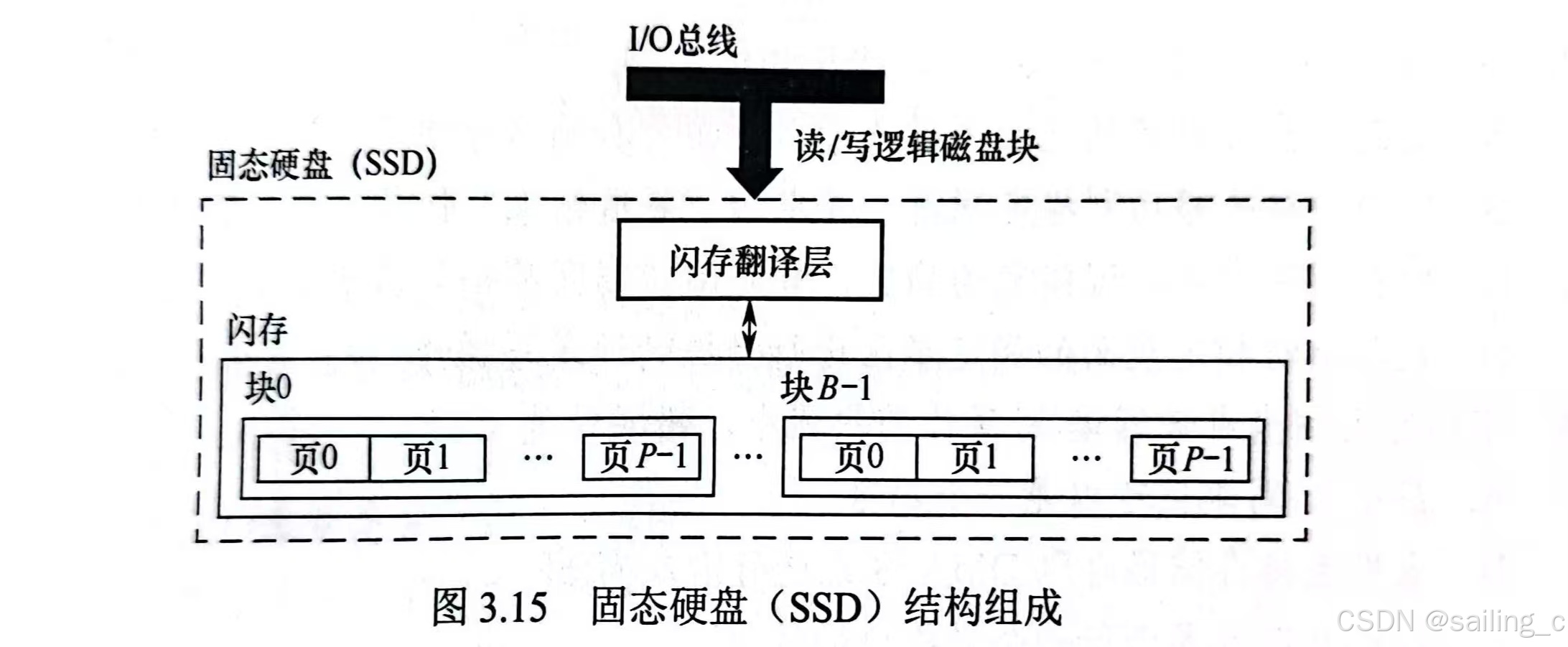
以常见的 SATA 接口固态硬盘为例,其连续读取速度可达 500MB/s 以上,而连续写入速度也能达到 400MB/s 左右,远远超过普通机械硬盘。而采用 NVMe 协议的 M.2 接口固态硬盘,性能更为强劲,连续读取速度甚至可以突破 3000MB/s。比如三星的 980 PRO NVMe M.2 固态硬盘,在高性能 PC 或笔记本电脑中被广泛使用,极大地提升了系统的启动速度和软件的加载速度,让用户能够快速进入工作或娱乐状态。
3.5 高速缓冲存储器
高速缓冲存储器(Cache)宛如一座桥梁,搭建在 CPU 与主存之间,是一块高速且小容量的存储器。其诞生的核心目的在于化解 CPU 与主存速度不匹配的矛盾,类比图书馆设置的热门书籍专区,方便读者快速获取高频使用资料,Cache 能够让 CPU 迅速访问常用数据与指令,提升计算机整体运行效率。
3.5.1 程序访问的局部性原理
程序访问的局部性原理是 Cache 得以存在并高效运作的理论根基。该原理表明,CPU 在访问存储器时,无论是指令读取还是数据存取,所涉及的存储单元往往集中在一个相对较小的连续区域内。具体而言,可细分为三种不同类型的局部性:
- 时间局部性(Temporal Locality):若一个信息项此刻正被访问,那么在不久的将来,它极有可能再次被访问。以程序中的循环结构为例,循环体内的指令和数据会在每次循环时反复被调用,这便是时间局部性的典型体现。比如一段计算 1 到 100 累加和的循环代码,每次循环都会访问累加变量和循环控制变量,这些变量在短时间内会被多次访问。
- 空间局部性(Spatial Locality):在即将到来的时刻要使用的信息,大概率与当前正在使用的信息在空间地址上紧密相邻。例如,数组在内存中以连续存储的方式存放,当程序访问数组中的某个元素时,其周边相邻的元素也极有可能在后续操作中被访问。假设存在一个存储学生成绩的数组,当程序读取某个学生的成绩时,很可能紧接着会读
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









