






 本文围绕Linux操作系统展开,介绍了fork、exec、wait三个常见API的功能,阐述了地址转换、分段、分页等内存管理技术,还提及页面置换算法,如最优替换、FIFO、LRU等。此外,讲解了进程和线程的区别、状态及关键并发术语,最后介绍了锁的初始化、调用、销毁及互斥解决方案。
本文围绕Linux操作系统展开,介绍了fork、exec、wait三个常见API的功能,阐述了地址转换、分段、分页等内存管理技术,还提及页面置换算法,如最优替换、FIFO、LRU等。此外,讲解了进程和线程的区别、状态及关键并发术语,最后介绍了锁的初始化、调用、销毁及互斥解决方案。
操作系统(散记)
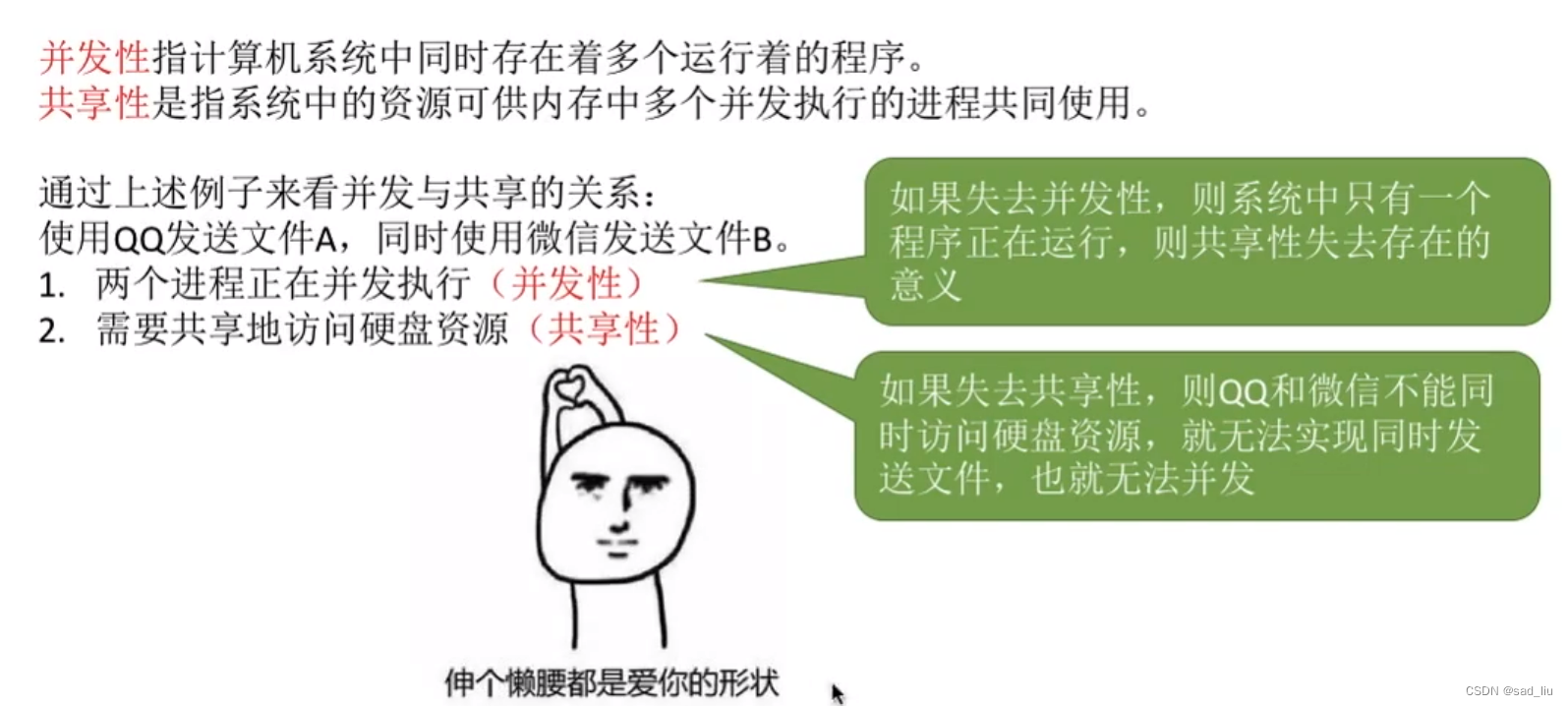
并发性和共享性互为存在条件
fork, exec, wait三个常见API的理解
- fork()系统调用
fork()系统调用是操作系统提供的创建新进程的方法。新创建的进程称为子进程,原来的进程称为父进程,子进程不会从main函数开始执行,而是从fork函数之后开始执行,所以子进程不是完全拷贝了父进程,他们两从fork函数获得到的返回值也是不同的,子进程获得的返回值是0。
- wait()系统调用
在执行完fork系统调用之后会存在一个问题:父、子程序的执行顺序是不确定的。那么需要一个函数来确保程序执行的统一性,这就是wait系统调用,父进程调用wait延迟自己的执行,知道子进程执行完毕。当子进程结束时,wait才返回父进程。这样程序的执行过程有个确定的顺序了。
- exec()系统调用
这个系统调用可以让子进程执行与父进程不同的程序,它并没有创建新进程,而是直接将当前运行的程序替换为不同的运行程序。
地址转换
实现CPU虚拟化时,遵循的一般准则称为受限直接访问(LDE)。让程序运行的大部分指令直接访问硬件,只在 一些关键点(如进程发起系统调用或发生时钟中断)由操作系统介入来确保“在正确时间, 正确的地点,做正确的事”。
地址转换技术:硬件对每次内存访问进行处理(即指令获取、数据读取或写入),将指令中的虚拟地址转换为数据实际存储的物理地址。操作系统必须在关键的位置介入,设置好硬件,以便完成正确的地址转换。因此它必须管理内存,记录被占用和空闲的内存位置,并明智而谨慎地介入,保持对内存使用的控制。
其实我们所看到的地址(编译器运行出来打印的地址)都不是真的,都是虚拟地址。
- 基于硬件的动态重定位
即使只有很少的硬件参与了定位,但取得了很好的效果一个基址寄存器将虚拟地址转换为物理地址,一个界限寄存器确保这个地址在进程地址空间的范围内。它们一起提供了既简单又高效的虚拟内存机制。基址寄存器配合界限寄存器在CPU当中称为内存管理单元(MMU)
分段
- 我们引用哪个段
硬件在地址转换时使用段寄存器。
显示方式:以代码、堆、栈三个段为例,那么需要两位来标识,如果用114位虚拟地址的前两位来标识,那么最高两位表示段,剩下的12位表示偏移量。因此,硬件就用前两位来决定使用哪个段寄存器,然后用后 12 位作为段内偏移。偏移量与基址寄存器相加,硬件就得到了最终的物理地址。
隐式方式:硬件通过地址产生的方式来确定段。例如,如果地址由程序计数器产生(即它是指令获取),那么地址在代码段。如果基于栈或基址指针,它一定在栈段。其他地址则在堆段。
分页
将空间分割成固定长度的分片。在虚拟内存中,我们称这种思想为分页。
我们把物理内存看成是定长槽块的阵列,叫作页帧。
为了记录地址空间的每个虚拟页放在物理内存中的位置,操作系统通常为每个进程保 存一个数据结构,称为页表。页表的主要作用是为地址空间的每个虚拟页面保 存地址转换,从而让我们知道每个页在物理内存中的位置。
分页有许多优点。首先,它不会导致外部碎片,因为分页(按设计)将内存划分为固定大小的单元。其次,它非常灵活,支持稀疏虚拟地址空间。
- 快速地址转换(TLB)
它就是频繁发生的虚拟到物理地址转换的硬件缓存。对每次内存访问,硬件先检查TLB,看看其中是否有期望的转换映射,如果有,就完成转换(很快),不用访问页表 (其中有全部的转换映射)。TLB 带来了巨大的性能提升。
- 多级页表
时间换空间,通过间接的方式将页表空间缩小,配合TLB达到时间空间的折中
- 局部性原理
时间局部性:最近访问过的指令或数据项可能很快会再次访问。想想循环中的循环变量或指令,它们被多次反复访问。
空间局部性:当程序访问内存地址 x 时,可能很快会访问邻近 x 的内存。想想遍历某种数组,访问一个接一个的元素。
当然,这些性质取决于程序的特点,并不是绝对的定律,而更像是一种经验法则。
通常情况下逻辑地址要比物理地址要大,在逻辑地址到物理地址的映射过程中会查询操作系统预先初始化好的页表,页表里有个独特的位为存在位present bit,其作用是来确定该映射是否在物理地址中有对应的地址,如果没有则会产生异常返回给操作系统,产生中断
超越物理内存:策略(页面置换算法)
- 最优替换策略
最优替换策略能达到总体未命中数量最少。但遗憾的是,很难实现!即替换内存中在最远将来才会被访问到的页,可以达到缓存未命中率最低。该方法强调的是能预知未来。
- FIFO先入先出
页在进入系统时,简单地放入一个队列。当发生替换时,队列尾部的页(“先入”页)被踢出。FIFO 有一个很大的优势:实现相当简单。
有意思的现象:Belady异常。一般来说,当缓存变大时,缓存命中率是会提高的。但在FIFO的情况下命中率反而下降了。相比于其他的策略,如LRU(稍后提到)不会遇到这样的情况。原因是没有栈特性,因此容易出现异常行为。
- 利用历史数据(LRU)“最少最近使用”策略
充分利用了局部性原理的特点,前面的FIFO可能出现剔除一个重要的页的情况,而LRU会根据历史信息的频率为基准来剔除相关页
- 时钟算法
通常硬件会设置两个位:一个使用位、一个脏位。时钟指针开始时指向某个特定的页。当必须进行页替换时,操作系统检查当前指向的页 P 的使用位是 1 还是 0。如果是 1,则意味着页面 P 最近被使用,因此不适合被替换。然后,P 的使用位设置为 0,时钟指针递增到下一页(P + 1)。
进程和线程
描述进程的数据结构:进程控制块(PCB),通常用链表实现
上下文切换是指在多任务操作系统中,将当前运行的进程或线程的状态保存起来,并恢复下一个要执行的进程或线程的状态的过程。
- 进程状态
创建状态、运行态、就绪态、等待状态(又称阻塞状态)、结束状态
- 进程和线程的区别
进程是独立的资源分配单位,拥有独立的地址空间和系统资源,进程之间通信开销较大;线程是在进程内部执行的轻量级执行单元,共享进程的资源,线程之间通信开销相对较小。进程适用于多个任务之间需要独立资源的情况,线程适用于在同一进程内实现并发执行和共享数据的情况。 进程可以由两部分组成:一部分是资源管理,另一部分是线程
- 线程的优缺点
优点:共享进程中的资源、各个线程可以并发的执行、一个进程可以有多个线程
缺点:因为资源的共享,可能导致在一个线程中破坏了进程的资源,安全性得不到保障
- 关键并发术语
临界区:是访问共享资源的一段代码,资源通常是一个变量或数据结构。
竞态条件:出现在多个执行线程大致同时进入临界区时,它们都试图更新共享的数据结构,导致了令人惊讶的(也许是不希望的)结果。解决方法:原子操作(是指一次不存在任何中断或者失败的执行)
不确定性程序:由一个或多个竞态条件组成,程序的输出因运行而异,具体取 决于哪些线程在何时运行。这导致结果不是确定的,而我们通常期望计算机系统给出确定的结果。
为了避免这些问题,线程应该使用某种互斥(mutual exclusion)原语。这样做可以保证只有一个线程进入临界区,从而避免出现竞态,并产生确定的程序输出。
互斥:当一个进程处于临界区并访问共享资源时,没有其他进程会处于临界区并且访问任何相同的共享资源
死锁:两个或以上的进程,在相互等待完成特定任务,而最终没法将自身任务进行下去
饥饿:一个可执行的进程,被调度器持续忽略,以至于虽然处于可执行状态却不被执行
- 锁
初始化
int rc = pthread_mutex_init(&lock, NULL);
assert(rc == 0); // always check success!
assert()函数是一种断言函数,常用于编程中进行条件检查和调试。如果断言失败则表达式为假,那么assert会引发一个AssertionError异常并程序终止
锁调用
pthread_mutex_t lock;
pthread_mutex_lock(&lock);
x = x + 1; // or whatever your critical section is
pthread_mutex_unlock(&lock);
锁销毁
pthread_mutex_destroy()
锁
-
互斥解决方案
-
-
控制中断:通过在进入临界区之前关闭中断(使用特殊的硬件指令),可以保证临界区的代码不会被中断,从而原子地执行。结束之后,我们重新打开中断(同样通过硬件指令),程序正常运行。
优点:简单,原子地执行,不用担心会被其他线程干扰
缺点:要求我们允许所有调用线程执行特权操作,即信任这种机制不会被滥用。信任一个贪婪的程序是非常糟糕的;案不支持多处理器;关闭中断导致中断丢失,可能会导致严重的系统问题。
-
-
-
自旋锁:应用了硬件技术测试并设置指令(test-and-set),也叫做原子交换(atomic exchange)
具体代码内容
int TestAndSet(int *old_ptr, int new) { int old = *old_ptr; // fetch old value at old_ptr *old_ptr = new; // store 'new' into old_ptr return old; // return the old value }它返回 old_ptr 指向的旧值,同时更新为 new 的新值。当然,关键是这些代码是原子地(atomically)执行。
执行流程
typedef struct lock_t { int flag; } lock_t; void init(lock_t *lock) { // 0 indicates that lock is available, 1 that it is held lock->flag = 0; } void lock(lock_t *lock) { while (TestAndSet(&lock->flag, 1) == 1) ; // spin-wait (do nothing) } void unlock(lock_t *lock) { lock->flag = 0; }首先假设一个线程在运行,调用 lock(),没有其他线程持有锁,所以 flag 是 0。当调用 TestAndSet(flag, 1)方法,返回 0,线程会跳出 while循环,获取锁。同时也会原子的设置 flag 为 1,标志锁已经被持有。当线程离开临界区,调用 unlock()将 flag 清理为 0。
第二种场景是,当某一个线程已经持有锁(即 flag 为 1)。本线程调用 lock(),然后调用TestAndSet(flag, 1),这一次返回 1。只要另一个线程一直持有锁,TestAndSet()会重复返回 1,本线程会一直自旋。当 flag 终于被改为 0,本线程会调用 TestAndSet(),返回 0 并且原子地设置为 1,从而获得锁,进入临界区。
-
评价自旋锁:能确保同步互斥;公平性不能得到保障,自旋的线程在竞争条件下可能会永远自旋,可能会导致程序饿死;对多CPU的情况下性能不错,单CPU的情况下开销比较大
-

















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









