




什么样的函数不能声明为虚函数?1)不能被继承的函数。2)不能被重写的函数。
1)普通函数
普通函数不属于成员函数,是不能被继承的。普通函数只能被重载,不能被重写,因此声明为虚函数没有意义。因为编译器会在编译时绑定函数。
而多态体现在运行时绑定。通常通过基类指针指向子类对象实现多态。
2)友元函数
友元函数不属于类的成员函数,不能被继承。对于没有继承特性的函数没有虚函数的说法。
3)构造函数
首先说下什么是构造函数,构造函数是用来初始化对象的。假如子类可以继承基类构造函数,那么子类对象的构造将使用基类的构造函数,而基类构造函数并不知道子类的有什么成员,显然是不符合语义的。从另外一个角度来讲,多态是通过基类指针指向子类对象来实现多态的,在对象构造之前并没有对象产生,因此无法使用多态特性,这是矛盾的。因此构造函数不允许继承。
4)内联成员函数
我们需要知道内联函数就是为了在代码中直接展开,减少函数调用花费的代价。也就是说内联函数是在编译时展开的。而虚函数是为了实现多态,是在运行时绑定的。因此显然内联函数和多态的特性相违背。
5)静态成员函数
首先静态成员函数理论是可继承的。但是静态成员函数是编译时确定的,无法动态绑定,不支持多态,因此不能被重写,也就不能被声明为虚函数。
STL包括几个部分:容器,算法(泛型算法),迭代器三个主要部分
vector的push_back()实现
产生N个不重复的随机数(复杂度要底)
1.重复再随机
这种方法是在[L,R]中先随机一个数,如果这个数之前取过,那么重复这个过程,直到取到不同的数为止。
不过这种方法在n个数取m个随机(m接近于n)时,时间复杂度将会很大。
这种方法的时间复杂度最坏为O(无穷),但是空间复杂度很小为O(1)。
2.队列法
首先我们出师一个[L,R]的一维数组,然后在[L,R]中随机一个下标作为新产生的随机数,然后将该随机数与下标为R的元素交换,然后再在[L,R-1]中随机新的随机数……以此递归,就可以在短时间内取到想要的随机数列。
这种方法的时间复杂度为O(m),但是空间复杂度会达到O(n)。
#include <iostream>
#include <vector>
#include<cmath>
#include<random>
using namespace std;
int main()
{
int N;
cin>>N;
vector<int> vec;
for(int i=0;i<N;i++)
{
vec.push_back(i);
}
for(int i = 0; i < N; i++)
{
int seed = rand()%(vec.size());
cout<<vec[seed]<<" ";
vec[seed]=vec.back();
vec.pop_back();
}
return 0;
}
数组合列表的区别
- Array数组可以包含基本类型和对象类型,ArrayList却只能包含对象类型.
- Array大小是固定的。ArrayList大小是动态增长的。
- Array
malloc能分配的最大内存:1.2G
Linux下虚拟地址空间分配给进程的是3GB,Windows默认是2GB(操作系统为32位)
虚函数表存储在常量区,因为虚函数表里地址是不会改变的。
虚函数表指针的存储位置是跟随对象的存储位置的,对象存在哪,虚函数表指针就存在哪。
C++内存分区
- 栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
- 全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
- 文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
- 程序代码区—存放函数体的二进制代码。
//main.cpp
int a = 0; //全局初始化区
char *p1; //全局未初始化区
main()
{
int b; //栈
char s[] = "abc"; //栈
char *p2; 栈
char *p3 = "123456";// 123456在常量区,p3在栈上。
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); //123456放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
断点调试原理:
调试断点,依赖于父进程和子进程之间的通信,打断点实际是在被调试的程序中,改变断点附近程序的代码,这个断点使得被调试的程序,暂时停止,然后发送信号给父进程(调试器进程),然后父进程能够得到子进程的变量和状态。达到调试的目的。
修改断点附近程序的指令地址为0xcc,这个地址的指令就是int 3,含义是,是当前用户态程序发生中断,告诉内核当前程序有断点,那么内核中会向当前进程发送SIGTRAP信号,使当前进程暂停。父进程调用wait函数,等待子进程的运行状态发生改变,这时子进程由于int 3中断,子进程暂停,父进程就可以开始调试子进程的程序了。
虚继承及实现原理https://blog.youkuaiyun.com/bxw1992/article/details/77726390

补充:
1、D继承了B,C也就继承了两个虚基类指针
2、虚基类表存储的是,虚基类相对直接继承类的偏移(D并非是虚基类的直接继承类,B,C才是)
C++编译系统在实例化D类时,只会将虚基类的构造函数调用一次,忽略虚基类的其他派生类(class B,class C)对虚继承的构造函数的调用,从而保证了虚基类的数据成员不会被多次初始化。
对于虚基类的初始化是由最后的派生类中负责初始化。
在最后的派生类中不仅要对直接基类进行初始化,还要负责对虚基类初始化。
C++编译系统只执行最后的派生类对基类的构造函数调用,而忽略其他派生类对虚基类的构造函数调用。从而避免对基类数据成员重复初始化。因此,虚基类只会构造一次。
虚继承和虚函数是完全无相关的两个概念。
虚继承是解决C++多重继承问题的一种手段,从不同途径继承来的同一基类,会在子类中存在多份拷贝。这将存在两个问题:其一,浪费存储空间;第二,存在二义性问题,通常可以将派生类对象的地址赋值给基类对象,实现的具体方式是,将基类指针指向继承类(继承类有基类的拷贝)中的基类对象的地址,但是多重继承可能存在一个基类的多份拷贝,这就出现了二义性。
虚继承可以解决多种继承前面提到的两个问题:
虚继承底层实现原理与编译器相关,一般通过虚基类指针和虚基类表实现,每个虚继承的子类都有一个虚基类指针(占用一个指针的存储空间,4字节)和虚基类表(不占用类对象的存储空间)(需要强调的是,虚基类依旧会在子类里面存在拷贝,只是仅仅最多存在一份而已,并不是不在子类里面了);当虚继承的子类被当做父类继承时,虚基类指针也会被继承。
实际上,vbptr指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚基类表(virtual table),虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员,而虚继承也不用像普通多继承那样维持着公共基类(虚基类)的两份同样的拷贝,节省了存储空间。
在这里我们可以对比虚函数的实现原理:他们有相似之处,都利用了虚指针(均占用类的存储空间)和虚表(均不占用类的存储空间)。
虚基类依旧存在继承类中,只占用存储空间;虚函数不占用存储空间。
虚基类表存储的是虚基类相对直接继承类的偏移;而虚函数表存储的是虚函数地址。
引入原因/纯虚函数的作用
- 为了方便使用多态特性,我们常常需要在基类中定义虚拟函数。
- 在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。
为了解决上述问题,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:virtual ReturnType Function()= 0;),则编译器要求在派生类中必须予以重写以实现多态性。同时含有纯虚拟函数的类称为抽象类,它不能生成对象。这样就很好地解决了上述两个问题。
什么时候需要重定义拷贝构造函数
1、这里有个简单的规则:如果你需要定义一个非空的析构函数,那么,通常情况下你也需要定义一个拷贝构造函数。
2、有一个原则:一般来说你在类中进行了new操作,你就需要析构函数,在你需要析构函数的类中,一般需要加上挎贝构造函数和赋值函数。
3、拷贝构造函数,是一种特殊的构造函数,它由编译器调用来完成一些基于同一类的其他对象的构建及初始化。其唯一的参数(对象的引用)是不可变的(const类型)。此函数经常用在函数调用时用户定义类型的值传递及返回。拷贝构造函数要调用基类的拷贝构造函数和成员函数。如果可以的话,它将用常量方式调用,另外,也可以用非常量方式调用。
在C++中,下面三种对象需要调用拷贝构造函数(有时也称“复制构造函数”):
- 一个对象作为函数参数,以值传递的方式传入函数体;
- 一个对象作为函数返回值,以值传递的方式从函数返回;
- 一个对象用于给另外一个对象进行初始化(常称为复制初始化);
通常的原则是:①对于凡是包含动态分配成员或包含指针成员的类都应该提供拷贝构造函数;②在提供拷贝构造函数的同时,还应该考虑重载"="赋值操作符号。
如果自己定义了析构函数但是没有重定义拷贝构造函数,则会使用默认的合成的拷贝构造函数。
默认的拷贝构造函数是传值参数,只是简单的将 形参的对象的成员变量,赋值给拷贝变量。
会造成对个对象可能指向相同的内存。两个对象包含相同的指针值,析构时会被delete 两次,发成错误。
含有指针的构造函数,自定义拷贝构造函数时需要深复制,即重新分配内存空间,将值拷过来。
sizeof(class)
- 类中的成员函数不占空间,虚函数除外。只要有虚函数,就会存在虚函数表指针,就会占4个字节。
- 空类占一个字节
- 类中的static静态成员变量不占内存,静态成员变量存储在静态区;并且静态成员变量的初始化必须在类外初始化;
- 函数指针不占字节;
重载和重写的区别:
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的参数列表,有兼容的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求,不能根据返回类型进行区分。
覆盖
覆盖是指派生类中存在重新定义基类的函数,其函数名、参数列、返回值类型必须同父类中相应被覆盖的函数严格一致,覆盖函数和被覆盖函数只有函数体不同,当基类指针指向派生类对象,调用该同名函数时会自动调用子类中的覆盖版本,而不是父类中的被覆盖函数版本。
函数调用在编译期间无法确定,因虚函数表存储在对象中,对象实例化时生成。因此,这样的函数地址是在运行期间绑定。
覆盖的特征
不同的范围(分别位于派生类和基类)
函数名字相同
参数相同
返回值类型相同
基类函数必须有virtual关键字。
重载和覆盖的关系
覆盖是子类和父类之间的关系,是垂直关系;重载是同一个类中方法之间的关系,是水平关系。
覆盖只能由一对方法产生关系;重载是两个或多个方法之间的关系。
覆盖要求参数列表相同;重载要求参数列表不同。
覆盖关系中,调用方法是根据对象的类型来决定的,重载关系是根据调用时的实参表与形参表来选择方法体的。
重载
重载是指同名函数具有不同的参数表。
在同一访问区域内声明的几个具有不同参数列表(参数的类型、个数、顺序不同)的同名函数,程序会根据不同的参数列来确定具体调用哪个函数。
对于重载函数的调用,编译期间确定,是静态的,它们的地址在编译期间就绑定了。
重载不关心函数的返回值类型。
函数重载的特征
相同的范围(同一个类中)
函数名字相同
参数不同
virtual关键字可有可无。
隐藏
隐藏是指派生类的函数屏蔽了与其同名的基类函数。
如果派生类的函数与基类的函数同名,但参数不同,则无论有无virtual关键字,基类的函数都被隐藏。
如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual关键字,此时基类的函数被隐藏。
隐藏的特征
必须分别位于基类和派生类中
必须同名
参数不同的时候本身已经不构成覆盖关系了,所以此时有无virtual关键字不重要
参数相同时就要看是否有virtual关键字,有就是覆盖关系,无就是隐藏关系
原文链接:https://blog.youkuaiyun.com/weixin_40087851/article/details/82012624
C语言编译运行的流程:
- 预处理:宏定义、文件包含、条件编译、布局控制
- 编译:进行语法、词法分析、语义分析,优化后生成汇编代码文件
- 汇编: 汇编代码转换机器码
- 链接:将源文件中用到的库函数与汇编生成的目标文件.o合并生成可执行文件
虚函数和纯虚函数
- virtual void function()=0; 纯虚函数
- virtual void function(); 虚函数
纯虚函数是在基类中声明的虚函数,它在基类中没有定义,但是要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加“=0”,含有纯虚函数的类称为抽象类,它不能生成对象。
C++ 中数组作为函数参数进行传递时,数组自定退化为同类型的指针。
#include<iostream>
#include<cstdlib>
#include<cstdio>
#include<string>
using namespace std;
int getSize(int data[]) //C++ 中数组作为函数参数进行传递时,数组自定退化为同类型的指针
{
return sizeof(data);
}
int main()
{
int a[]={1,2,3,4,5};
int size1=sizeof(a);
cout<<size1<<endl; // 20=4*5
int *b=a;
int size2=sizeof(b);
cout<<size2<<endl; //指针大小为 4
int size3=getSize(a);
cout<<size2<<endl; //数组退化为指针,所以也是4
return 0;
}
IO模型 参考链接
- 数据准备阶段:数据需要从硬件设备拷贝到内核缓冲区
- 数据拷贝阶段:数据从内核缓冲区拷贝到用户进程空间
- 同步:同步只能让调用者去轮询自己
- 异步:可以通知调用者IO可读或可写
- 阻塞:调用recv()函数时,整个进程或者线程就等待在这里了,直到你recv的fd的所有信息都被send过来,这么做好处就是保证所有信息都能够完整的读取了。缺点是进程或线程在此段时间里,做不了其他事。
- 非阻塞:调用recv()函数后会立马返回,进程或线程可以继续执行下一步工作,不用等。
- 阻塞IO模型:调用recvfrom(),进程阻塞。直到数据准备好后,再进行数据拷贝
- 非阻塞IO模型:轮休调用recvfrom(), 数据准备阶段不阻塞,当检测到数据准备好后,开始进行数据拷贝(阻塞)。
- IO复用模型::本质上和非阻塞IO一样,但是它可以同时在一个进程里监视多个IO端口。调用select() 轮询所有的Sockt当发现有数据准备好后,就调用recvfrom()函数进行数据拷贝
- 异步IO模型:
IO多路复用:单个线程,通过记录跟踪每个I/O流(sock)的状态,来同时管理多个I/O流
select、poll、epoll的区别
select==>时间复杂度O(n)
- select会修改传入的参数数组,对需要多次调用的函数不友好
- 有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,select具有O(n)的无差别轮询复杂度
- select能监视的端口有限。
- select 不是线程安全的,比如你把一个sock加入到select后,在其他线程中关闭了sock,select的结果将是不可预测的
- 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态
- 它没有最大连接数的限制,原因是它是基于链表来存储的
- 轮询方式检测就绪事件,算法复杂度为O(n)
(3)epoll==>时间复杂度O(1)
- epoll是线程安全的
- 不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)
- 虽然连接数有上限,但是很大.没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
- epoll通过内核和用户空间共享一块内存来实现的。
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
当我们定义一个数组a时,编译器根据指定的元素个数和元素的类型分配确定大小(元素类型大小*元素个数)的一块内存,并把这块内存的名字命名为a。名字a一旦与这块内存匹配就不能改变。a[0],a[1]等为a的元素,但并非元素的名字。数组的每一个元素都是没有名字的。
这里&a[0]和&a到底有什么区别呢?a[0]是一个元素,a是整个数组,虽然&a[0]与&a的值一样,但其意义不一样。前者是数组元素的首地址,而后者是数组的首地址。以指针的形式访问和以下标的形式访问时,记住偏移量的单位是元素的个数而不是byte数,在计算新地址时千万别弄错了。
通过下面的例子来看:
#include<iostream>
using namespace std;
int main()
{
int a[5]={1,2,3,4,5};
int* ptr=(int*)(&a+1);
printf("%d,%d",*(a+1),*(ptr-1));
system("pause");
return 0;
}答案:2,5
解析:
int* ptr=(int*)(&a+1);&a为数组a的首地址,对指针加1操作,得到的是下一个元素的地址,而不是原有地址值直接加1,所以&a+1则为&a的首地址加5*sizeof(int),显然当前指针已经超过了数组的界限。将上一步计算出来的地址,强制转换成int*类型,赋给ptr。
*(a+1);a,&a的值是一样的,但意思不一样。a是数组首元素的首地址,也就是[0]的首地址,a+1是数组下一个元素的首地址,即a[1],&a+1是下一个数组的首地址。所以输出2
*(ptr-1);因为ptr是指向a[5],并且ptr是int*类型,所以*(ptr-1)是指向a[4],输出5。
C++四种强制类型转换符:
static_cast<Type>(expression);
(1) 用于类层次结构中基类(父类)和派生类(子类)之间指针或引用的转换;
——进行上行转换(把派生类的指针或引用转换成基类表示)是安全的;
——进行下行转换(把基类指针或引用转换成派生类表示)时,由于没有动态类型检查,所以是不安全的。
(2)用于基本数据类型之间的转换。如int转换为char,int转换为enum,安全性由开发人员保证;
(3)把空指针(void*)转换成目标类型的指针;
(4)把任何类型的表达式转换成void类型。
dynamic_cast<Type>(expression); //支持运行时类型识别
- Type必须是一个类类型,并且要求该类中含有虚函数,否则编译报错。
- 如果 Type 是类指针类型,那么expression也必须是一个指针;如果 type-id 是一个引用,那么 expression 也必须是一个左值。
应用:类层次间的上行转换和下行转换,还可以用于类之间的交叉转换。假设High和Low是两个类,而ph,pl类型分别是High * 和Low * ,则仅当Low是High的可访问基类(直接或间接)时下面语句才将一个Low* 指针赋给pl: pl=dynamic_cast<Low*> ph. 否则该语句将空指针赋值给pl. - 作用:使得能够在类层次结构进行向上转换,而不予许其他转换。
- 与static_cast相比,(1)dynamic_cast支持运行时类型识别,在下行转换时比static_cast安全;(2)dynamic_cast支持类之间的交叉转换,而static_cast不支持;(3)dynamic_cast要求转换的类类型含有虚函数,而static_cast没有这个限制。
reinterpret_cast<Type>(expression);
const_cast<Type>(expression);
- 将常量转化为非常量,但不能进行类型转换。
- 去掉const,volatile属性。
常见的C++关键字有哪些?各是什么作用?
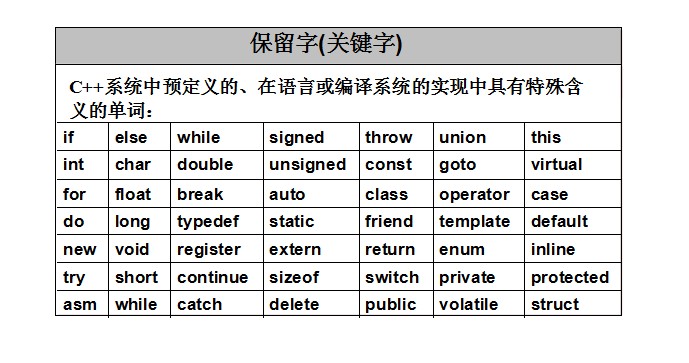
volatile
volatile关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器位置的因素更改,比如:操作系统、硬件或者其它线程等。由于访问寄存器的速度要快过RAM,所以编译器一般都会作减少存取RAM的优化。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
三大特性:
易变性:是在汇编层面反映出来的,就是两条语句,下一条语句不会直接使用上一条语句对应的volatile变量的寄存器内容,而是重新从内存中读取;
不可优化性:volatile所修饰的变量,编译器不会对其进行各种激进的优化;
顺序性:C/C++ 对volatile变量和非volatile变量之间的操作,是可能被编译器交换顺序的(交换后无变化,在有些地方这样处理就会出问题),对volatile变量间的操作,编译器不会交换顺序;
explicit
C++中的explicit关键字只能用于修饰只有一个参数的类构造函数, 它的作用是表明该构造函数是显示的, 而非隐式的, 跟它相对应的另一个关键字是implicit, 意思是隐藏的,类构造函数默认情况下即声明为implicit(隐式).
关键字用来修饰类的构造函数,表明该构造函数是显式的。举例说说明如下:
假设我们这样定义了一个c++类
class MyClass
{
public:
MyClass( int num ){}
};
那么如果构造函数MyClass前没有关键字,下面的语句
MyClass obj = 10; //ok,convert int to MyClass
在编译时(VC++ 6.0测试)是可以通过的,进行了一个隐式转换,相当于执行了下面的语句
MyClass temp(10);
MyClass obj = temp;
但是如果我们在构造函数前面加上explicit 关键字,即
class MyClass
{
public:
explicit MyClass( int num ){}
};
就表明构造函数不能进行上面所说的隐式转换
编译时(VC++ 6.0)会给出error C2440: 'initializing' : cannot convert from 'const int' to 'class MyClass'
的错误报告!
inline
inline是为了解决一些频繁调用的小函数大量消耗栈空间的问题而引入的。一般函数代码在10行之内,并且函数体内代码简单,不包含复杂的结构控制语句例如:while、switch,并且函数本身不是直接递归函数(自己调用自己)。
extern
extern(外部的)声明变量或函数为外部链接,即该变量或函数名在其它文件中可见。被其修饰的变量(外部变量)是静态分配空间的,即程序开始时分配,结束时释放。用其声明的变量或函数应该在别的文件或同一文件的其它地方定义(实现)。在文件内声明一个变量或函数默认
C和C++有什么区别?
设计思想上:
C++是面向对象的语言,而C是面向过程的结构化编程语言
语法上:
C++具有封装、继承和多态三种特性
C++相比C,增加多许多类型安全的功能,比如强制类型转换、
C++支持范式编程,比如模板类、函数模板等
C++11智能指针
介绍:智能指针主要用于管理在堆上分配的内存,它将普通的指针封装为一个栈对象。当栈对象的生存周期结束后,会在析构函数中释放掉申请的内存,从而防止内存泄漏。C++ 11中最常用的智能指针类型为shared_ptr,它采用引用计数的方法,记录当前内存资源被多少个智能指针引用。该引用计数的内存在堆上分配。当新增一个时引用计数加1,当过期时引用计数减一。只有引用计数为0时,智能指针才会自动释放引用的内存资源。对shared_ptr进行初始化时不能将一个普通指针直接赋值给智能指针,因为一个是指针,一个是类。可以通过make_shared函数或者通过构造函数传入普通指针。并可以通过get函数获得普通指针。
智能指针的作用:普通指针new出的内存必须由程序员手动delete掉,否则会内存泄露。智能指针则是在将new获得的地址(直接或间接的)赋值给智能指针对象,在智能指针过期时,自动调用析构函数使用deletel来释放内存。方便内存管理。
智能指针类似于指针的类对象,下面介绍3中智能指针模板类。
- auto_ptr : 由C++98提出,被C++11摒弃。
采用所有权模式。
auto_ptr< string> p1 (new string ("I reigned lonely as a cloud.”));
auto_ptr<string> p2;
p2 = p1; //auto_ptr不会报错.
此时不会报错,p2剥夺了p1的所有权,但是当程序运行时访问p1将会报错。所以auto_ptr的缺点是:存在潜在的内存崩溃问题!
- unique_ptr :“唯一”拥有其所指对象,同一时刻只能有一个unique_ptr指向给定对象(通过禁止拷贝语义、只有移动语义来实现)。
unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。
采用所有权模式,还是上面那个例子
unique_ptr<string> p3 (new string ("auto")); //#4
unique_ptr<string> p4; //#5
p4 = p3;//此时会报错!!
编译器认为p4=p3非法,避免了p3不再指向有效数据的问题。因此,unique_ptr比auto_ptr更安全。
另外unique_ptr还有更聪明的地方:当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果源 unique_ptr 将存在一段时间,编译器将禁止这么做,比如:
unique_ptr<string> pu1(new string ("hello world")); unique_ptr<string> pu2; pu2 = pu1; // #1 not allowed unique_ptr<string> pu3; pu3 = unique_ptr<string>(new string ("You")); // #2 allowed - share_ptr: 多个指针指向相同的对象,采用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr 是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的), 在使用引用计数的机制上提供了可以共享所有权的智能指针。
- .weak_ptr: 是一种不控制所指向对象生存期的智能指针,它指向一个由shared_ptr管理的对象。 将一个weak_ptr绑定到 一个share_ptr上,不会改变shared_ptr的引用计数。一旦最后一个指向对象的shared_ptr被销毁,对象就会被释放,即使有weak_ptr指向对象,对象也会被释放。weak_ptr 字面意思:“弱共享对象” 也就是这么来的。
我们创建一个weak_ptr时,要有一个shared_ptr来初始化它。
因为weak_ptr指向的对象可能不存在(最后一share_ptr销毁时,释放了对象),所以不能使用weak_ptr直接访问对象。必须调用lock()函数,如果weak_ptr<int> wp指向的对象被释放了,wp.lock()则会返回一个空shared_ptr,否则返回一个指向对象的shared_ptrauto p=make_shared<int>(42) ; weak_ptr<int> wp(p); //wp弱共享p; p的引用计数未改变if(shared_ptr<int> np=wp.lock()) { // 如果np 不为空 则条件成立 }
指针和引用的区别:
1、指针有自己的一块空间,而引用只是一个别名;
2、使用sizeof看一个指针的大小是4,而引用则是被引用对象的大小;
3、指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象的引用;
4、作为参数传递时,指针需要被解引用才可以对对象进行操作,而直接对引用的修改都会改变引用所指向的对象;
5、可以有const指针,但是没有const引用;
6、指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能 被改变;
7、指针可以有多级指针(**p),而引用至于一级;
8、指针和引用使用++运算符的意义不一样;
9、如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露。
stl::list 不支持随机访问迭代器
随机访问相当于重载[ ],list不支持常数时间的随机访问。
map的底层实现:
map本质是关联类容器,
map内部自建一棵红黑树,这棵树对数据有自动排序的功能,所以map内部所有数据都是有序的。
虚函数除了存函数地址还存了什么?
堆和栈的区别:
- 申请方式不同:栈由操作系统自动分配回收,堆则需要程序员手动分配回收
- 申请效率:栈由系统分配,速度快,不会有内存碎片。堆由程序员分配,速度较慢,可能由于操作不当产生内存碎片。
- 申请大小限制不同:栈是由高地址向低地址扩展,是一块连续的内存区域,栈顶的地址和栈的容量是系统预先规定好的。
堆则是由低地址向高地址扩展的,是不连续的内存区域。堆获得的空间比较灵活也比较大。
内存碎片:
- 内部碎片是由于采用固定大小的内存分区,当一个进程不能完全使用分给它的固定内存区域时就产生了内部碎片,通常内部碎片难以完全避免;
- 外部碎片是由于某些未分配的连续内存区域太小,以至于不能满足任意进程的内存分配请求,从而不能被进程利用的内存区域。
- 通常采用段页式内存管理方式减少内存碎片的产生。
static作用:
- 隐藏:static全局变量和函数,对其他文件不可见。可以利用这个特性,在不同的文件定义同名函数和变量。
- 默认初始化为0,:未初始化的全局变量和未初始化的静态变量都存储在BSS段,BSS段中所有字节默认值都是0x00.
- 保持局部变量内容的持久:static局部变量存储在BSS段或数据段中,可以保持其上次的赋值。具有记忆性,退出该函数后,变量继续存在,但是作用域任然与局部变量相同,所以退出函数后不可访问。
类中的static需要注意的问题:
- 静态成员变量必须在类定义体外部定义和初始化
- 静态成员函数不能访问非静态成员函数和非静态成员,可以访问静态成员及函数。非静态函数则无限制。
- 静态成员函数没有this指针,因为它不属于任何对象。
- static成员函数不能声明为const, 毕竟将函数声明为const就是承诺不会通过该函数修改该函数所属的对象。而static成员函数不属于任何对象。
const修饰符
- const修饰指针时:
const int *ptr 常量指针,ptr不用初始化,ptr指向常量数据,不能通过ptr去修改 指向的常量,但是ptr指针自身可以被改变.
int * const ptr=&a 指针常量,ptr必须初始化,ptr本身不允许被修改,但是可以通过ptr修改 指向的数据。 - const修饰函数参数和返回值:参数为指针或引用时,若不想函数对参数进行修改,则参数前加const, 返回值前加const也是保证返回不允许被修改。
- 类中 const成员常量,不能在类的声明体中初始化,必须在构造函数里初始化,因为不同的对象可以有不同的 const 常量值,所以只能在构造函数初始化,而不能在声明体或定义体里初始化。
- 类里的const,修饰成员函数,修饰成员函数参数,修饰对象。
new / delete 和 malloc / free 的区别
- malloc/free是C/C++语言的标准库函数,new/delete是C++的运算符。
- new 可以自动计算空间大小,malloc不行
指针数组和数组指针
- 指针数组:是指一个数组里面装着指针,也即指针数组是一个数组; 定义形式: int *a[10];
- 数组指针:数组指针:是指一个指向数组的指针,它其实还是一个指针,只不过是指向数组而已;定义形式:int (*p)[10]; 其中,由于[]的优先级高于*,所以必须添加(*p).
结构体和联合体的区别:
- struct和union都是由多个不同的数据类型成员组成, 但在任何同一时刻, union中只存放了一个被选中的成员, 而struct的所有成员都存在。在struct中,各成员都占有自己的内存空间,它们是同时存在的。一个struct变量的总长度等于所有成员长度之和。在Union中,所有成员不能同时占用它的内存空间,它们不能同时存在。Union变量的长度等于最长的成员的长度。
- 对于union的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存在了, 而对于struct的不同成员赋值是互不影响的。
抽象类和接口的区别:https://blog.youkuaiyun.com/qq_33098039/article/details/78075184
- 抽象类可以有构造方法,接口中不能有构造方法。
- 抽象类中可以有普通成员变量,接口中没有普通成员变量
- 抽象类中可以包含静态方法,接口中不能包含静态方法
- 一个类可以实现多个接口,但只能继承一个抽象类。
- 接口可以被多重实现,抽象类只能被单一继承
- 如果抽象类实现接口,则可以把接口中方法映射到抽象类中作为抽象方法而不必实现,而在抽象类的子类中实现接口中方法
抽象类:
- 抽象方法只作声明,而不包含实现,可以看成是没有实现体的虚方法
- 抽象类不能被实例化
- 如果一个类中有一个抽象方法,那么当前类一定是抽象类;抽象类中不一定有抽象方法。
- 抽象类中的抽象方法,需要有子类实现,如果子类不实现,则子类也需要定义为抽象的。
- 抽象派生类可以覆盖基类的抽象方法,也可以不覆盖。如果不覆盖,则其具体派生类必须覆盖它们
接口:
- 接口不能被实例化
- 接口只能包含方法声明
- 接口的成员包括方法、属性、索引器、事件
- 接口中不能包含常量、字段(域)、构造函数、析构函数、静态成员
const和define的区别,以及const的优势:
区别:
- 就起作用的阶段而言: #define是在编译的预处理阶段起作用,而const是在 编译、运行的时候起作用。
- 就起作用的方式而言: #define只是简单的字符串替换,没有类型检查。而const有对应的数据类型,是要进行判断的,可以避免一些低级的错误。
- 就存储方式而言:#define只是进行展开,有多少地方使用,就替换多少次,它定义的宏常量在内存中有若干个备份;const定义的只读变量在程序运行过程中只有一份备份。
- 从代码调试的方便程度而言: const常量可以进行调试的,define是不能进行调试的,因为在预编译阶段就已经替换掉了。
const优势:
- const常量有数据类型,而宏常量没有数据类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且在字符替换可能会产生意料不到的错误。
- 有些集成化的调试工具可以对const常量进行调试,但是不能对宏常量进行调试。
- const可节省空间,避免不必要的内存分配,提高效率

















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









