







一、关于scrapy中pipleline的基本认识
首先我们看看Item Pipeline在Scrapy中的架构,如下图所示。
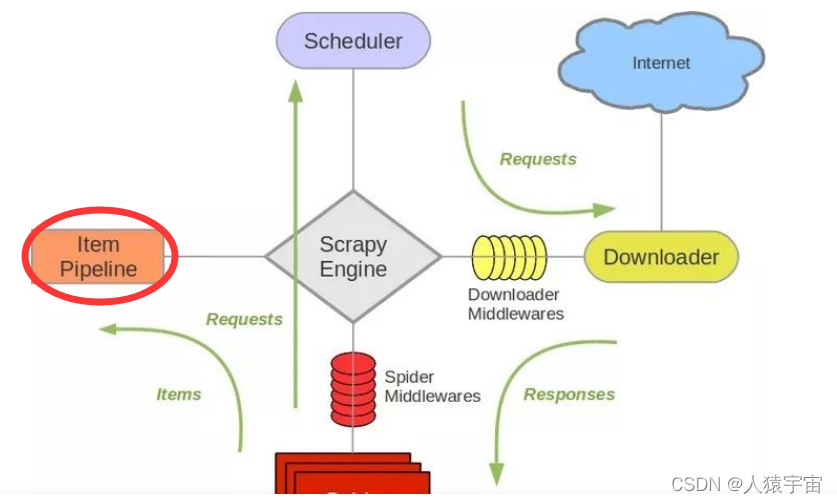
Item Pipeline又称之为管道,顾名思义就是对数据的过滤处理,其主要的作用包括如下:
- 清理HTML数据。
- 验证爬取数据,检查爬取字段。
- 查重并丢弃重复内容。
- 将爬取结果保存到数据库。
二、几个核心的方法
创建一个项目的时候都会自带pipeline其中就实现了process_item(item, spider)方法
- open_spider(spider)就是打开spider时候调用的
- close_spider(spider)关闭spider时候调用
- from_crawler(cls, crawler)一般用来从settings.py中获取常量的
- process_item(item, spider)是必须实现的,别的都是选用的
三、几个常用方法的介绍
- process_item(item, spider)参数介绍 item是要处理的item对象,spider当前要处理的spider对象
- process_item(item, spider)返回值,返回item就会继续给优先级低的item pipeline二次处理,如果直接抛出DropItem的异常就直接丢弃该item
- open_spider(spider)是在开启spider的时候触发的,常用于初始化操作(常见开启数据库连接,打开文件)
- close_spider(spider)是在关闭spider的时候触发的,常用于关闭数据库连接
- from_crawler(cls, crawler)是一个类方法(需要使用@classmethod装饰器标识),常用于从settings.py获取配置信息
四、item pipeline说明
item pipiline组件是一个独立的Python类,其中process_item()方法必须实现
import something
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
五、数据验证
让我们来看一下以下这个假设的pipeline,它为那些不含税(price_excludes_vat 属性)的item调整了 price 属性,同时丢弃了那些没有价格的item:
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









