




发表时间:Oct 2024
论文链接:https://readpaper.com/pdf-annotate/note?pdfId=2609030709939626752¬eId=2609030834543745536
作者单位:University of Adelaide
Motivation:Generalist robot manipulation policies (GMPs) have the potential to generalize across a wide range of tasks, devices, and environments. However, existing policies continue to struggle with out-of-distribution scenarios due to the inherent difficulty of collecting sufficient action data to cover extensively diverse domains. We observe that the performance of the resulting GMPs differs significantly with respect to the design choices of fine-tuning strategies.(主要研究的就是对具身模型的微调)
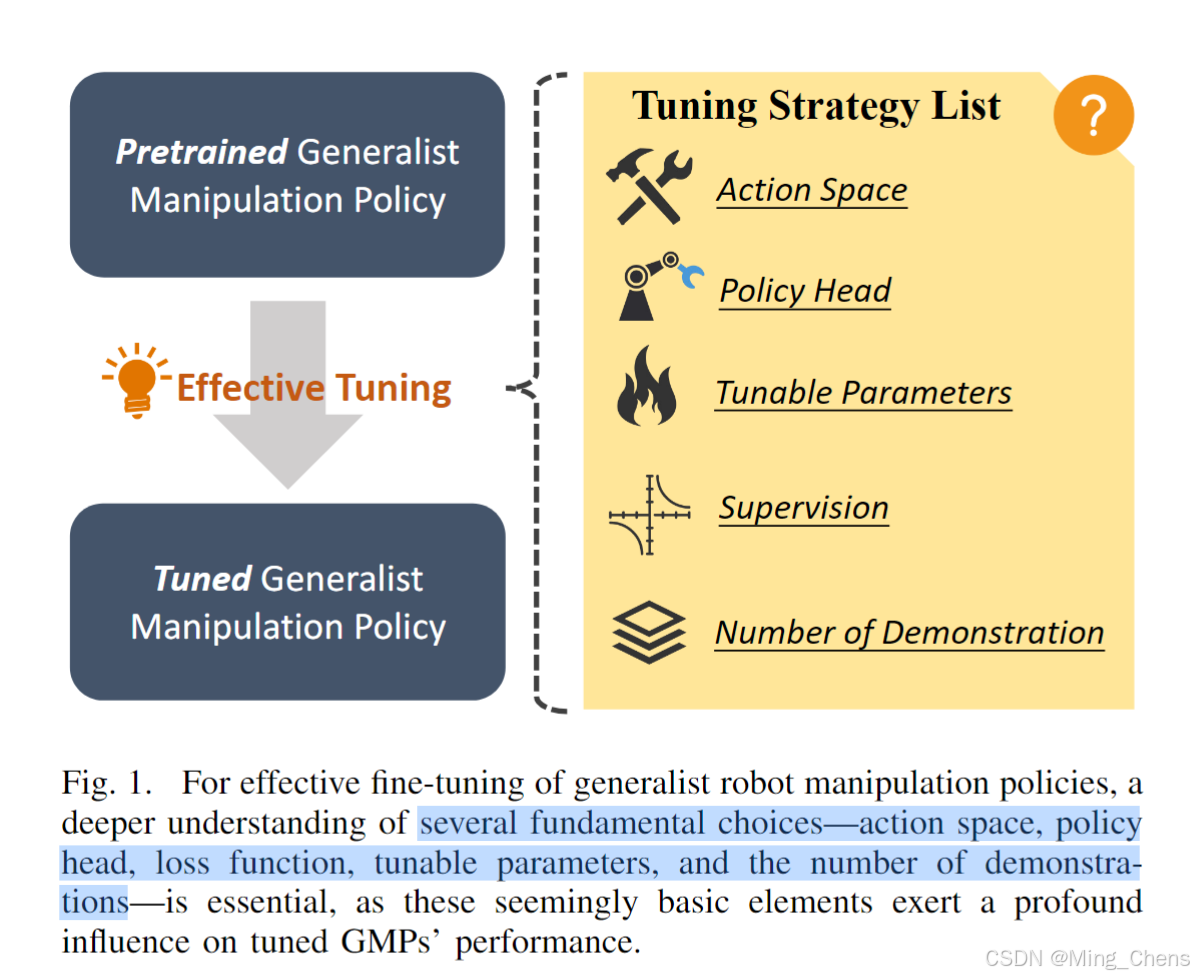
解决方法:In this work, we first conduct an indepth empirical study to investigate the effect of key factors in GMPs fi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











