






 本文介绍了新型深度语境化词表征Elmo,它能对词的复杂特征和多义词进行建模。阐述了其原理,包括基于LSTM构建,以及双向LSTM模型的前向、后向和整体模型。还提及训练参数,预训练完成后可用于NLP任务,对部分任务有效果提升。
本文介绍了新型深度语境化词表征Elmo,它能对词的复杂特征和多义词进行建模。阐述了其原理,包括基于LSTM构建,以及双向LSTM模型的前向、后向和整体模型。还提及训练参数,预训练完成后可用于NLP任务,对部分任务有效果提升。
Elmo
1 Elmo简介
ELMo是一种新型深度语境化词表征,可对词进行复杂特征(如句法和语义)和词在语言语境中的变化进行建模(即对多义词进行建模)。词向量是深度双向语言模型(biLM)内部状态的函数,在一个大型文本语料库中预训练而成。
2 Elmo原理
模型架构图如下:
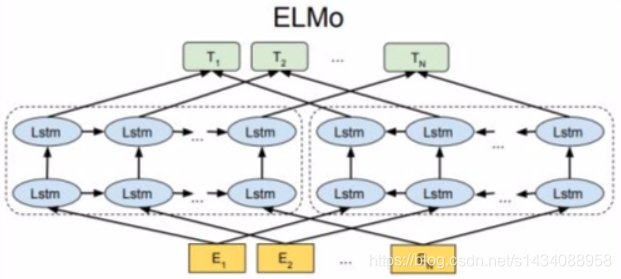
2.1 LSTM
Elmo的基本由LSTM构成 首先理解下何为LSTM
LSTM网络引入一个新的内部状态(internal state)
c
t
c_t
ct 专门进行
线性的循环信息传递,同时(非线性)输出信息给隐藏层的外部状态
h
t
h_t
ht。
c
t
=
f
t
⨀
c
t
−
1
+
i
t
⨀
c
t
′
c_t = f_t \bigodot c_t-1 + i_t \bigodot c'_t
ct=ft⨀ct−1+it⨀ct′
h
t
=
o
t
⨀
t
a
n
h
(
c
t
)
h_t = o_t \bigodot tanh(c_t)
ht=ot⨀tanh(ct)
其中
f
t
,
i
t
f_t,i_t
ft,it 和
o
t
o_t
ot 为三个门(gate)来控制信息传递的路径;⊙为向量元素乘积;
c
t
−
1
c_{t−1}
ct−1 为上一时刻的记忆单元;
c
t
′
c'_t
ct′ 是通过非线性函数得到候选状态
在数字电路中,门(Gate)为一个二值变量{0, 1},0代表关闭状态,不许
任何信息通过;1代表开放状态,允许所有信息通过。
LSTM网络中的“门”是一种“软”门,取值在(0, 1)之间,表示以一定的比例运行信息通过。
LSTM网络中三个门的作用为
• 遗忘门 f t f_t ft 控制上一个时刻的内部状态 c t − 1 c_{t−1} ct−1 需要遗忘多少信息。
• 输入门 i t i_t it 控制当前时刻的候选状态 c t ′ c'_t ct′ 有多少信息需要保存。
• 输出门 o t o_t ot控制当前时刻的内部状态 c t c_t ct有多少信息需要输出给外部状态 h t h_t ht。
当 f t = 0 , i t = 1 f_t = 0, i_t = 1 ft=0,it=1时,记忆单元将历史信息清空,并将候选状态向量 c t ′ c'_t ct′ 写入。
但此时记忆单元 c t c_t ct 依然和上一时刻的历史信息相关。
当 f t = 1 , i t = 0 f_t = 1, i_t = 0 ft=1,it=0时,记忆单元将复制上一时刻的内容,不写入新的信息。
三个门的计算方式为:
i
t
=
σ
(
W
i
x
t
+
U
i
h
t
−
1
+
b
i
)
i_t = \sigma(W_ix_t + U_ih_{t-1} +b_i)
it=σ(Wixt+Uiht−1+bi)
f
t
=
σ
(
W
f
x
t
+
U
f
h
t
−
1
+
b
f
)
f_t = \sigma(W_fx_t + U_fh_{t-1} +b_f)
ft=σ(Wfxt+Ufht−1+bf)
o
t
=
σ
(
W
o
x
t
+
U
o
h
t
−
1
+
b
o
)
o_t = \sigma(W_ox_t + U_oh_{t-1} +b_o)
ot=σ(Woxt+Uoht−1+bo)
其中
σ
(
x
)
\sigma(x)
σ(x)为Logistic函数,其输出区间为(0, 1),
x
t
x_t
xt 为当前时刻的输入,
h
t
−
1
h_{t−1}
ht−1 为
上一时刻的外部状态。
下图给出了 LSTM 网络的循环单元结构,其计算过程为:
(1)首先利用上一时刻的外部状态
h
t
−
1
h_{t−1}
ht−1 和当前时刻的输入
x
t
x_t
xt,计算出三个门,以及候选状态
c
t
′
c'_t
ct′;
(2)结合遗忘门 f t f_t ft 和输入门 i t i_t it 来更新记忆单元 c t c_t ct;
(3)结合输出门
o
t
o_t
ot,将内部状态的信息传递给外部状态
h
t
h_t
ht。

循环神经网络中的隐状态h存储了历史信息,可以看作是一种记忆(Memory)。
在简单循环网络中,隐状态每个时刻都会被重写,因此可以看作是一种短期记忆(Short-Term Memory)。
在神经网络中,长期记忆(Long-Term Memory)可以看作是网络参数
,隐含了从训练数据中学到的经验,并更新周期要远远慢于短期记忆。
而在LSTM网络中,记忆单元c可以在某个时刻捕捉到某个关键信息,
并有能力将此关键信息保存一定的时间间隔。
记忆单元c中保存信息的生命周期要长于短期记忆h,但又远远短于长期记忆,
因此称为长的短期记忆(Long Short-Term Memory)。
2.2 Elmo的双向LSTM模型
2.2.1 前向模型
给定一串长度为N的词条
(
t
1
,
t
2
,
…
,
t
N
)
(t_1,t_2,…,t_N)
(t1,t2,…,tN),前向语言模型通过对给定历史
(
t
1
,
…
t
k
−
1
)
(t_1,…t_{k−1})
(t1,…tk−1)预测
t
k
t_k
tk进行建模
p
(
t
1
,
t
2
,
…
,
t
N
)
=
∏
k
=
1
N
p
(
t
k
∣
t
1
,
t
2
,
…
,
t
k
−
1
)
p\left(t_{1}, t_{2}, \ldots, t_{N}\right)=\prod_{k=1}^{N} p\left(t_{k} | t_{1}, t_{2}, \ldots, t_{k-1}\right)
p(t1,t2,…,tN)=k=1∏Np(tk∣t1,t2,…,tk−1)
第一步:将单词转换成了n*1的列向量,进行word embedding,得到 LSTM的输入
x
t
x_t
xt。
第二步:将上一时刻的输出/隐状态 h k − 1 h_{k−1} hk−1及第一步中的 x t x_t xt送入lstm,
并得到输出及隐状态 h k h_k hk。其中,隐状态 h k h_k hk是一个m*1的列向量。
第三步:将lstm的输出 h k h_k hk,与上下文矩阵 W W W相乘,即 W h k Wh_k Whk得到一个列向量,再将该列向量经过softmax归一化。其中,假定数据集有V个单词, W W W是 ∣ V ∣ ∗ m |V|*m ∣V∣∗m的矩阵, h k h_k hk是 m ∗ 1 m*1 m∗1的列向量,于是最终结果是 ∣ V ∣ ∗ 1 |V|*1 ∣V∣∗1的归一化后向量,即从输入单词得到的针对每个单词的概率。
2.2.2 双向模型
对于多层lstm,每层的输出都是1.1节中提到的隐向量 h t h_t ht,在ELMo里,为了区分,前向lstm语言模型的第j层第k时刻的输出向量命名为 h k , j L , M → h_{k,j}^{L,M\rightarrow} hk,jL,M→ 。
对于后向语言模型,跟前向语言模型类似,除了它是给定后文来预测前文。
p
(
t
1
,
t
2
,
…
,
t
N
)
=
∏
k
=
1
N
p
(
t
k
∣
t
k
+
1
,
t
k
+
2
,
…
,
t
N
)
p\left(t_{1}, t_{2}, \ldots, t_{N}\right)=\prod_{k=1}^{N} p\left(t_{k} | t_{k+1}, t_{k+2}, \ldots, t_{N}\right)
p(t1,t2,…,tN)=k=1∏Np(tk∣tk+1,tk+2,…,tN)
类似的,设定后向lstm的第j层的第k时刻的输出向量命名为 h k , j L , M ← h_{k,j}^{L,M\leftarrow} hk,jL,M←。
前向、后向lstm语言模型所要学习的目标函数。elmo使用的双向lstm语言模型,论文中简称biLM。作者将前后向公式结合起来,得到所要优化的目标:最大化对数前向和后向的似然概率。
∑
k
=
1
N
(
log
p
(
t
k
∣
t
1
,
…
,
t
k
−
1
;
Θ
x
,
Θ
⃗
L
S
T
M
,
Θ
s
)
+
log
p
(
t
k
∣
t
k
+
1
,
…
,
t
N
;
Θ
x
,
Θ
←
L
S
T
M
,
Θ
s
)
)
\begin{array}{l}{\sum_{k=1}^{N}\left(\log p\left(t_{k} | t_{1}, \ldots, t_{k-1} ; \Theta_{x}, \vec{\Theta}{L S T M}, \Theta{s}\right)\right.} \\ {\quad+\log p\left(t_{k} | t_{k+1}, \ldots, t_{N} ; \Theta_{x}, \stackrel{\leftarrow}{\Theta}{L S T M}, \Theta{s}\right) )}\end{array}
∑k=1N(logp(tk∣t1,…,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,…,tN;Θx,Θ←LSTM,Θs))
2.2.3 Elmo模型
Elmo就是把输入
x
k
L
,
M
x_{k}^{L,M}
xkL,M,前向输出
h
k
,
j
L
,
M
,
→
h_{k,j}^{L,M,\rightarrow}
hk,jL,M,→ ,后向输出
h
k
,
j
L
,
M
←
h_{k,j}^{L,M\leftarrow}
hk,jL,M← 结合起来
R
k
=
(
x
k
L
,
M
,
h
k
,
j
L
,
M
,
→
,
h
k
,
j
L
,
M
←
∣
j
=
1
,
.
.
.
,
L
)
=
(
h
k
,
j
L
,
M
∣
j
=
0
,
.
.
.
,
L
)
R_k = (x_k^{L,M},h_{k,j}^{L,M,\rightarrow},h_{k,j}^{L,M\leftarrow}|j = 1,...,L) \\ = (h_{k,j}^{L,M}|j = 0,...,L)
Rk=(xkL,M,hk,jL,M,→,hk,jL,M←∣j=1,...,L)=(hk,jL,M∣j=0,...,L)
1.最简单的方法就是使用最顶层的lstm输出
2.对于每层向量,加一个权重
s
j
t
a
s
k
s^{task}_j
sjtask,将每层的向量与权重相乘,然后再乘以一个权重
γ
γ
γ。对于每一个
t
o
k
e
n
token
token,一个L层的biLM要计算出共
2
L
+
1
2L+1
2L+1个表征。
E
L
M
o
k
task
=
E
(
R
k
;
Θ
task
)
=
γ
task
∑
j
=
0
L
s
j
task
h
k
,
j
L
M
ELMo_{k}^{\text { task }}=E\left(R_{k} ; \Theta^{\text { task }}\right)=\gamma^{\text { task }} \sum_{j=0}^{L} s_{j}^{\text { task }} \mathbf{h}_{k, j}^{L M}
ELMok task =E(Rk;Θ task )=γ task j=0∑Lsj task hk,jLM
3 训练
论文的作者有预训练好的ELMo模型,映射层(单词到word embedding)使用的Jozefowicz的CNN-BIG-LSTM[5],即输入为512维的列向量。同时LSTM的层数L,最终使用的是2,即L=2。每层的LSTM的单元数是4096。每个LSTM的输出也是512维列向量。每层LSTM(含前、向后向两个)的单元个数是4096个(从1.1节可以知公式4m2 = 4512*2 = 4096)。也就是每层的单个lstm的输入是512维,输出也是512维。
一旦模型预训练完成,便可以用于nlp其他任务。在一些领域,可以对biLM(双向lstm语言模型)进行微调,对任务的表现会有所提高,这种可以认为是一种迁移学习(transfer learning)
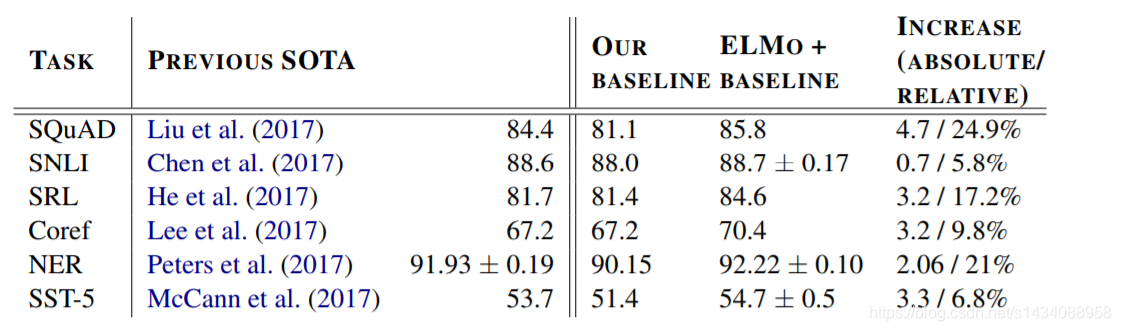
4 模型效果
对于诸多NLP任务 Elmo有少许提升 其中SQuAD 提升4.7%
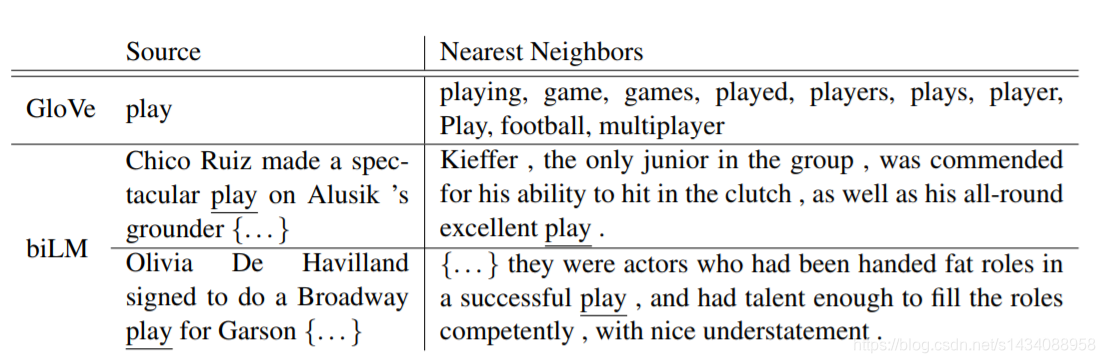
 对于多义词不同语义的学习
对于多义词不同语义的学习
参考 :
[1]: Peters, Matthew E., et al. “Deep contextualized word representations.” arXiv preprint arXiv:1802.05365 (2018)
[2] :https://zhuanlan.zhihu.com/p/51679783

















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









