






问题描述:
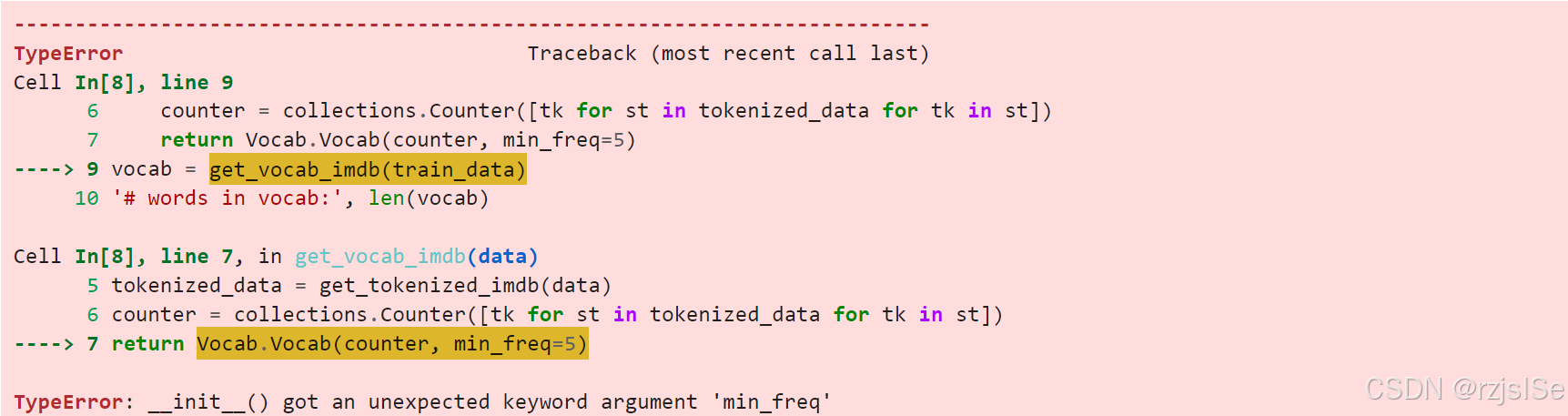
在运行第十章的如下部分代码时,
def get_vocab_imdb(data):
tokenized_data = get_tokenized_imdb(data)
counter = collections.Counter([tk for st in tokenized_data for tk in st])
return Vocab.Vocab(counter, min_freq=5)
vocab = get_vocab_imdb(train_data)
'# words in vocab:', len(vocab)出现报错:
问题解决:
该问题产生于 torchtext 由于版本不同而导致接口不一致,我使用的版本为 0.14.1(使用 pip show torchtext 可查看当前的版本):

修改 get_vocab_imdb 函数,在其中添加筛选频率逻辑即可(手动实现),使用如下的代码即可正常运行:
def get_vocab_imdb(data, min_freq=5):
tokenized_data = get_tokenized_imdb(data)
counter = collections.Counter([tk for st in tokenized_data for tk in st])
# 手动过滤低频词
filtered_counter = {token: freq for token, freq in counter.items() if freq >= min_freq}
return Vocab.Vocab(filtered_counter)
# 示例
vocab = get_vocab_imdb(train_data, min_freq=5)
print('# words in vocab:', len(vocab))输出:
# words in vocab: 46150
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









