



多路召回(几千物品)
-
itemCF
思路:用户喜欢item j,因为item 与 item j相似,所以用户可能喜欢item
note:sim不是根据item的特征计算的,而是用户的集群
-
Swing 【*】
-
小圈子的用户可能影响sim的值,导致两个不相关的物品被误判为高度相关,影响推荐。swing针对这个问题提出解决办法。
-
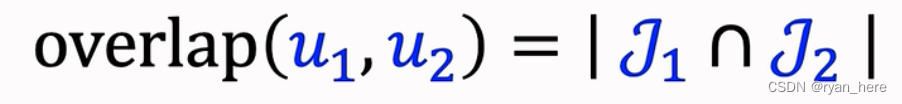
-
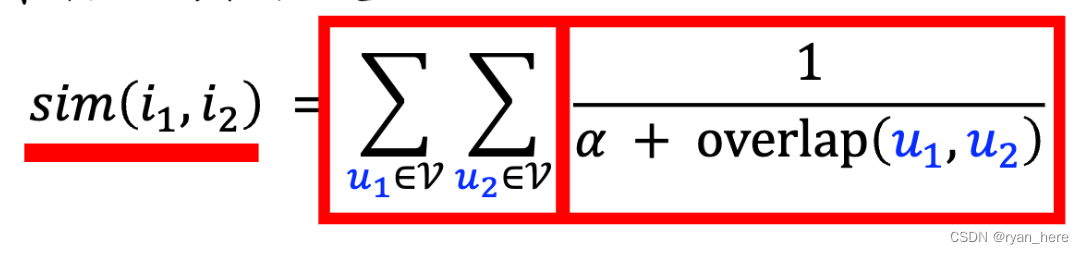
-
重合度越高,sim越小,以此防止小圈子用户的干扰
-
userCF 【*】
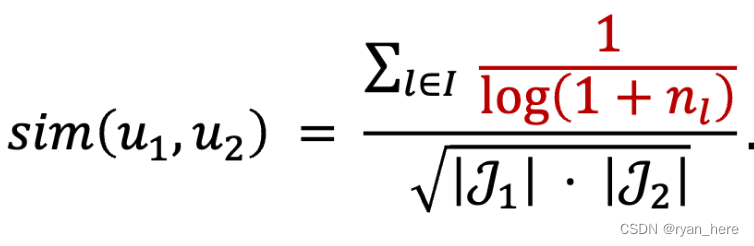
I 表示两个用户喜欢物品的交集,J表示各自喜欢的物品数量
物品越热门,更容易出现交集,需要降低热门物品的权重,当n越大时,sim越低
-
向量召回- 双塔模型【*】(特征必须后期融合)
one-hot编码:稀疏,不适合特征类别大的情况
embedding编码:稠密,向量维度(行) x 类别数量(列) (trainable)
(用户ID、用户离散特征、用户连续特征)-> (concatenate)神经网络 -> 用户特征
(物品ID、物品离散特征、物品连续特征)->(concatenate) 神经网络 -> 物品特征
Pointwise: 正负样本独立,正负样本数量1:2 或者1:3
Pairwise:正负样本成对,鼓励大于

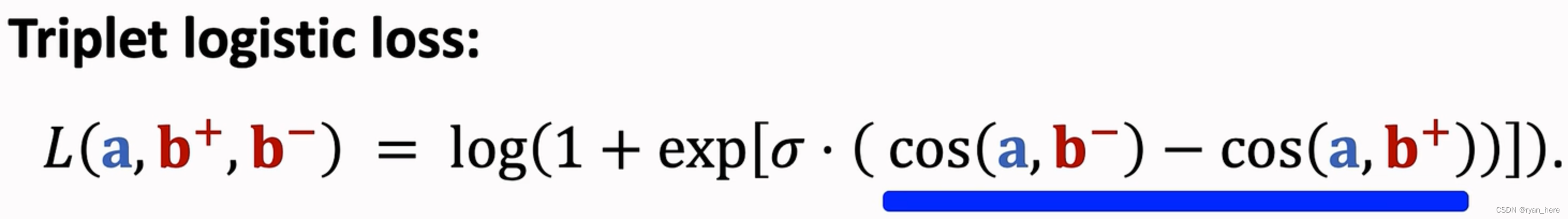
Listwise: 一个正样本与多个负样本,softmax + cross entropy损失函数(类似多分类)
Jui-Ting Huang et al. Embedding-based Retrieval in Facebook Search. In KDD, 2020.
双塔模型+自监督学习
deep Retrieve
字节召回模型- deep retrieval笔记-优快云博客
GeoHash召回
地理位置召回,没有个性化
GeoHash:对经纬度对编码(地图上一个长方形区域)
GeoHash -> 时间顺序排布的优质笔记列表(笔记ID )
同城召回
作者召回
关注的作者
索引:用户 -> 关注的作者
有交互的作者召回
点赞、收藏、转发过的作者
索引:用户->有交互的作者
相似作者召回
索引:作者 -> 相似作者
召回: 用户 感兴趣的作者 相似作者 最新的笔记
缓存召回
复用前n次推荐精排的结果
精排前50,但是没有曝光的,缓存起来,下次进行召回
缓存大小固定,需要退场机制
曝光过滤
如果用户看过某物品,则不再把该物品曝光给该用户
记录用户的曝光历史
暴力对比时间复杂度太高,使用bloom filter算法:保障用户不可能看见已曝光过的(判断为未曝光,则肯定未曝光;判断已曝光,可能有误判)
实时流处理:Kafka 消息队列+ Flink 实时计算哈希值
只支持添加物品,不支持删除物品,因为会影响到其他向量
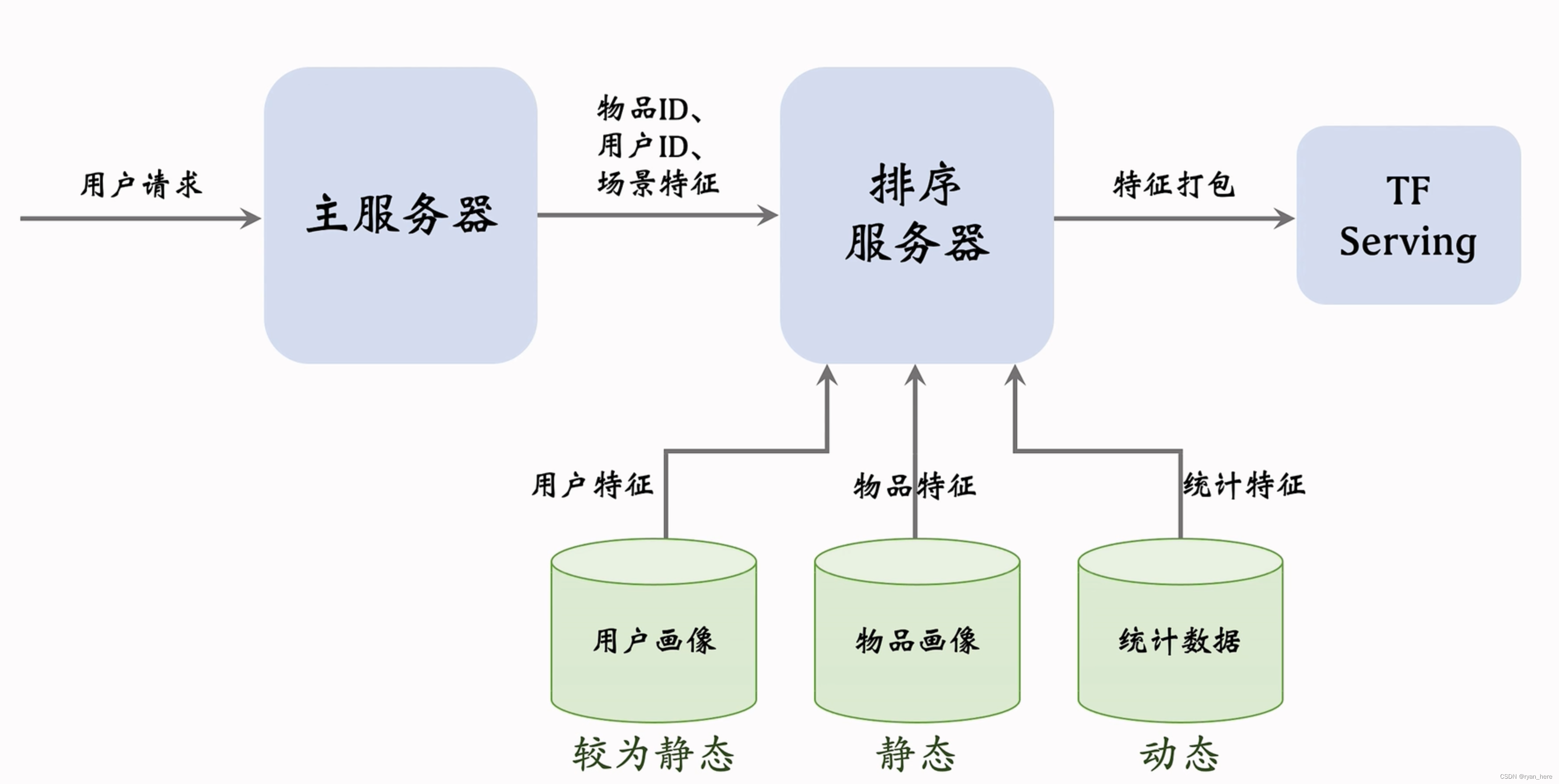
粗排、精排
系统记录:
- 曝光次数
- 点击次数
- 点赞次数
- 收藏次数
- 转发次数
用户画像
- 用户ID
- 人口统计学属性:性别、年龄
- 账号信息:新老、活跃度...
- 感兴趣的类目、关键词、品牌
物品画像
- 物品ID
- 发布时间
- GeoHash
- 标题、类目、关键词、品牌
- 字数、图片数、视频清晰度、标签数
- 内容信息量、图像美学度
用户统计特征

笔记统计特征

场景特征
- GeoHash、城市
- 当前时刻
- 是否周末/节假日
- 手机品牌、手机型号、操作系统(安卓和苹果用户的点击差异性很大)
注意特征覆盖率
排序模型预估点击率、点赞率、收藏率、转发率的分数,最后进行分数融合,做排序和截断
适用于粗排的模型(几千量级)
三塔模型(粗排模型-小红书做了细节改进)
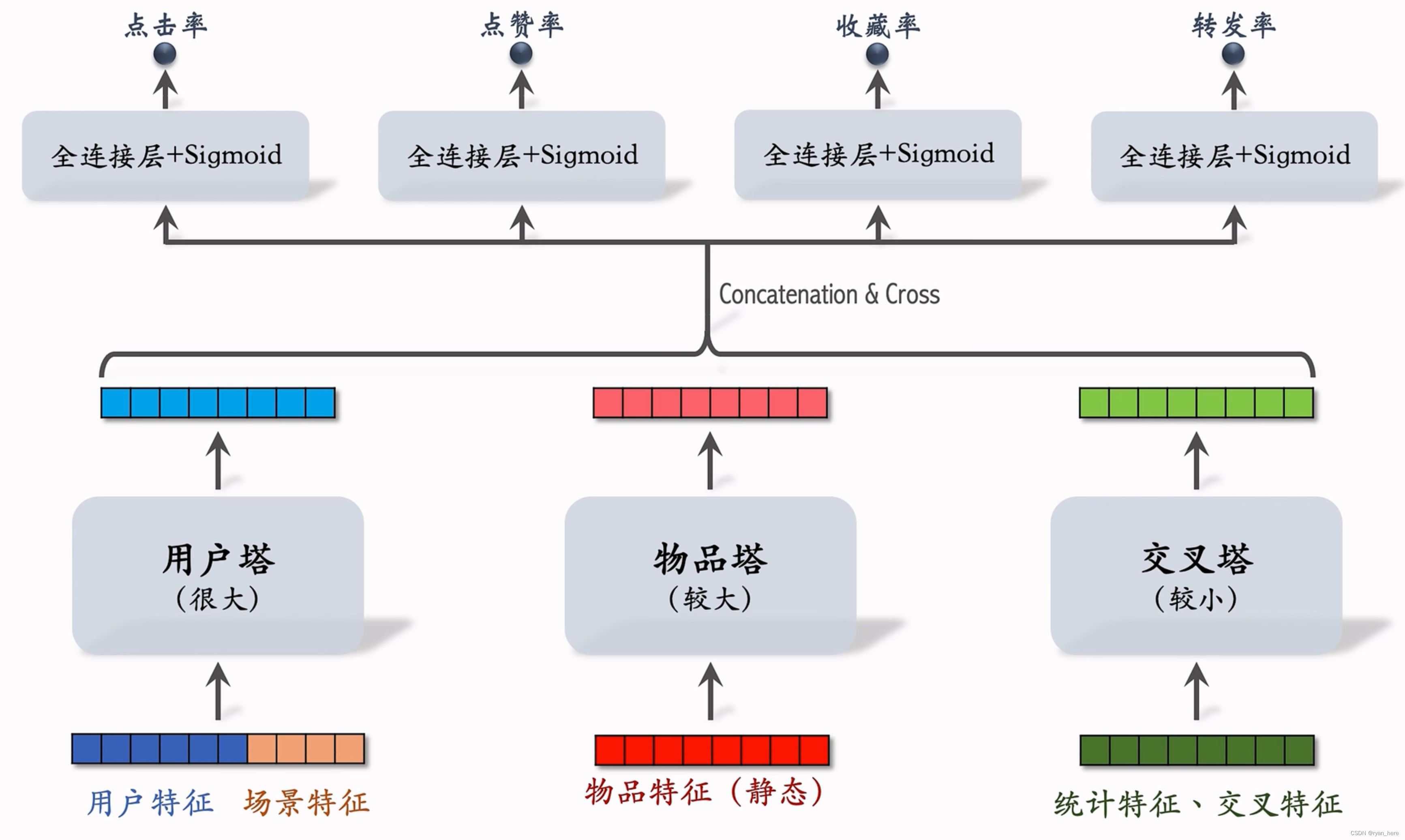
用户塔:每次只有一个用户,只做一次推理
物品塔:物品信息稳定,缓存物品塔,减少推理次数,未命中缓存时才需要做推理
交叉塔:信息动态变化,n个物品必须做n次推理 (通常只有一层)
上层网络必须做n次推理,给n个物品打分
多目标模型(精排模型)
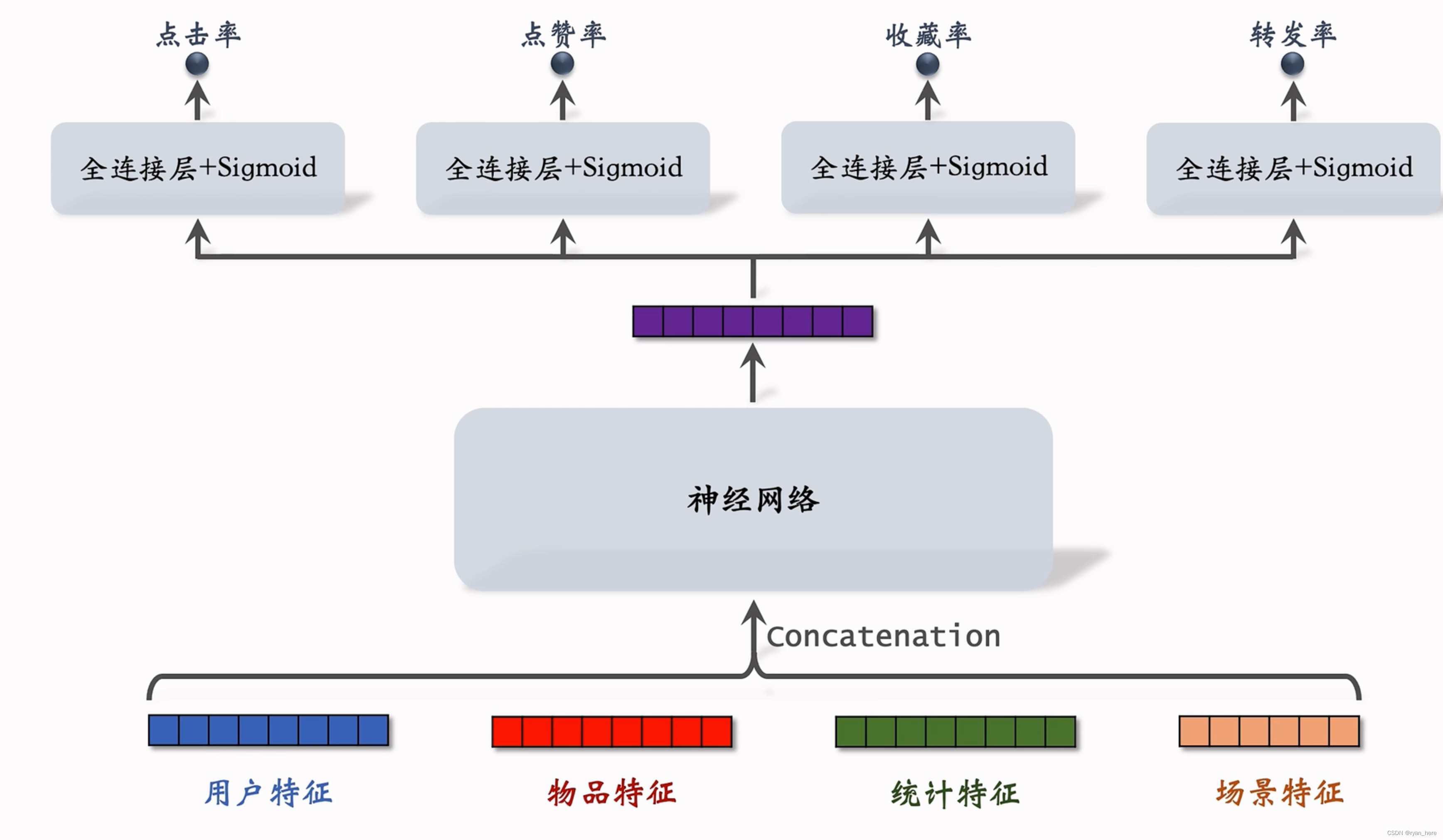
前期融合,先对所有特征做融合
[y1,y2,y3,y4] 二元分类,eg: target:[0,1,0,0]
- 困难:正负样本类别不平衡
- 解决:负样本down- sampling,保留一小部分负样本
- 模型会高估点击率/点赞率..., 需要做预估值校准
预估值校准:正样本、负样本数量为,
,使用负样本为 a *
校准公式:
融合预估分数:
- 简单加权和
- 点击率 * 其他项的加权和
- 海外某短视频APP的融分公式
- 国内某短视频APP的融分公式
... r代表对候选物品的排序,排序越靠前,分数越高
- 国内购物软件
Multi-gate Mixture of Experts (MMoE)
专家神经网络的数量通常是4/8... (超参数)
有多少个目标(点赞率/收藏率...) 就有多少组权重
极化:softmax输出值一个接近1,其余接近0,接近0的时候对应的专家神经网络失效
解决极化问题:对softmax的输出使用dropout,使得每个专家可能会被随机抛弃,使得
【有的业务有提升,有的业务没有提升】
特征交叉的方法
Factorized Machine (FM) 【目前不常用】
线性模型(逻辑回归...) 的替代品,就是在线性模型后加上交叉项

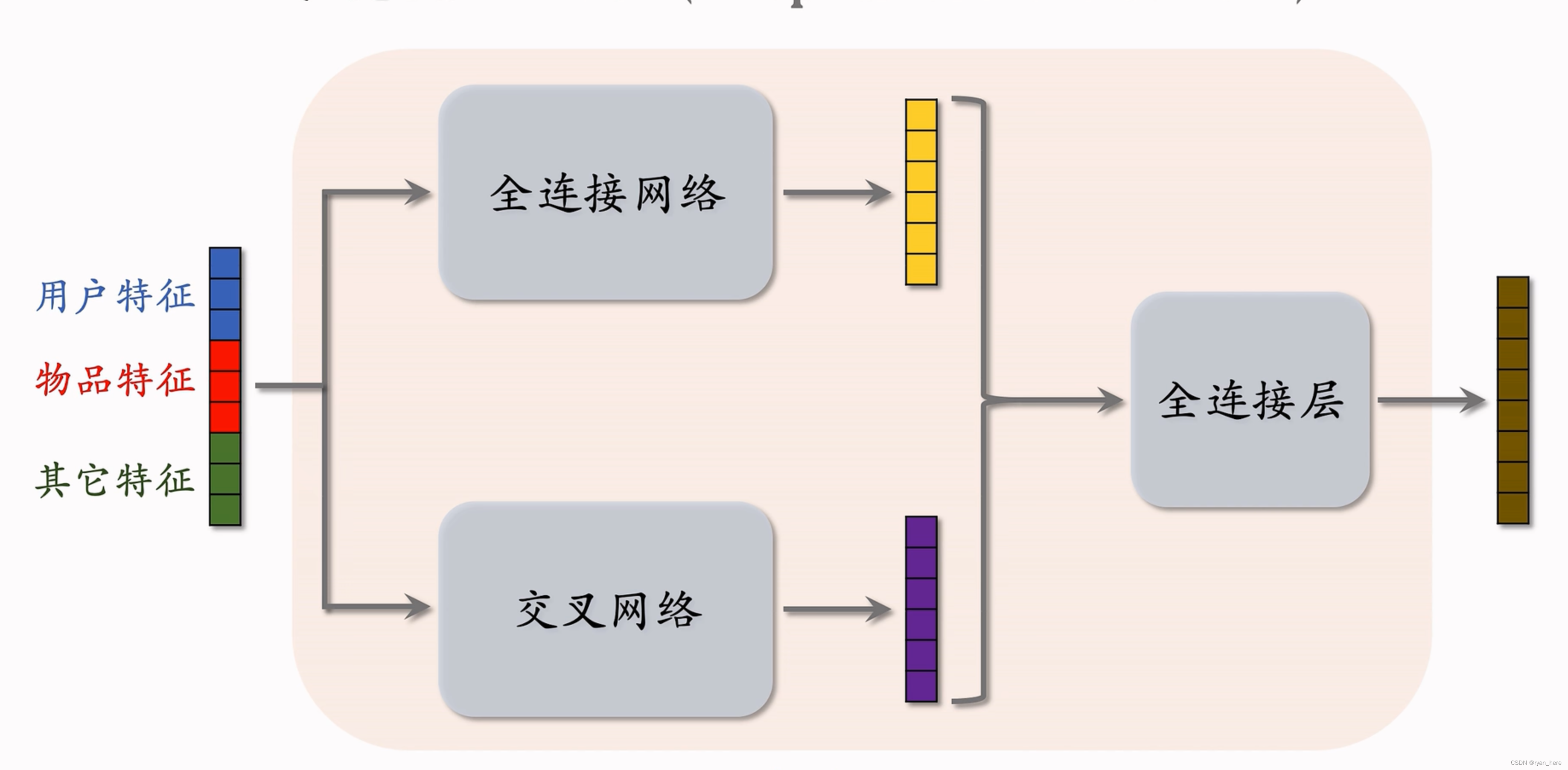
深度交叉网络(DCN)【*】召回和排序都能使用
效果优于全链接
交叉层(类似于resnet中的跳跃连接)
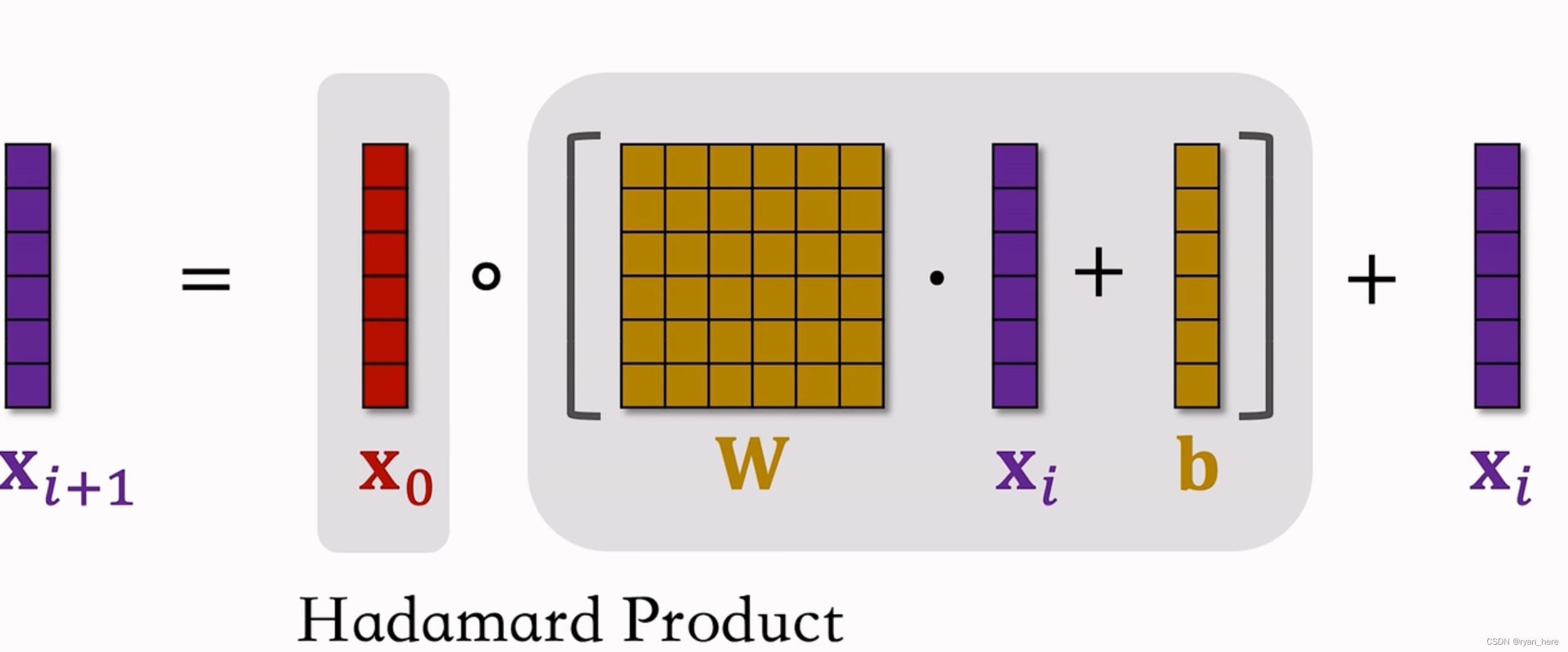
交叉网络 (cross network)
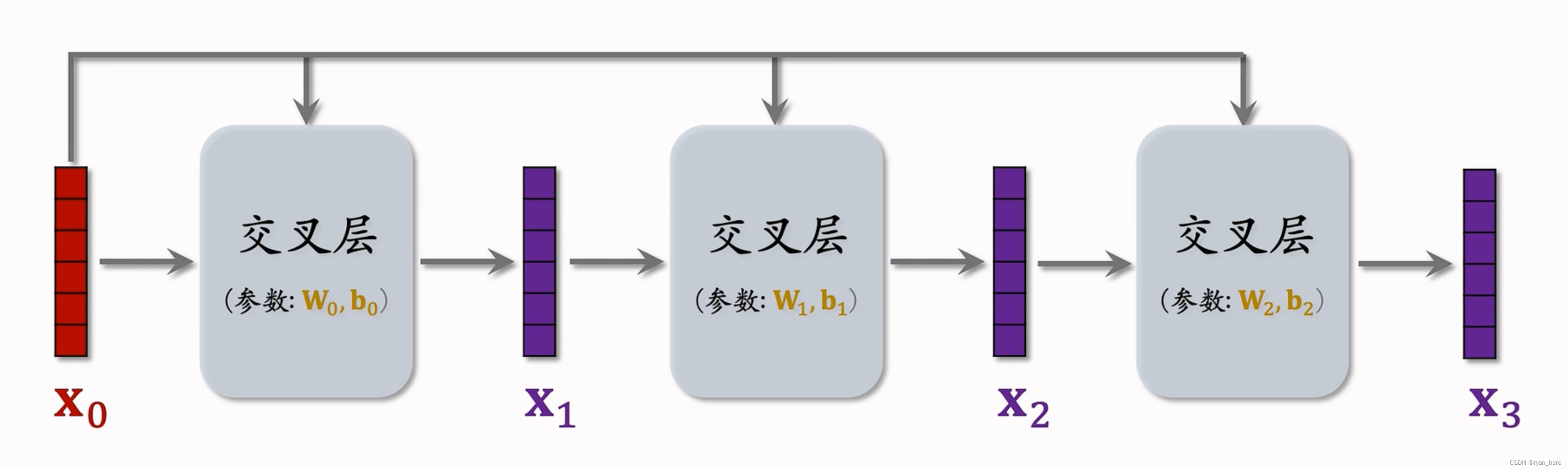
深度交叉网络(deep & cross network)【*】
LHUC网络(只能用于精排)
快手精排模型,起源于语音识别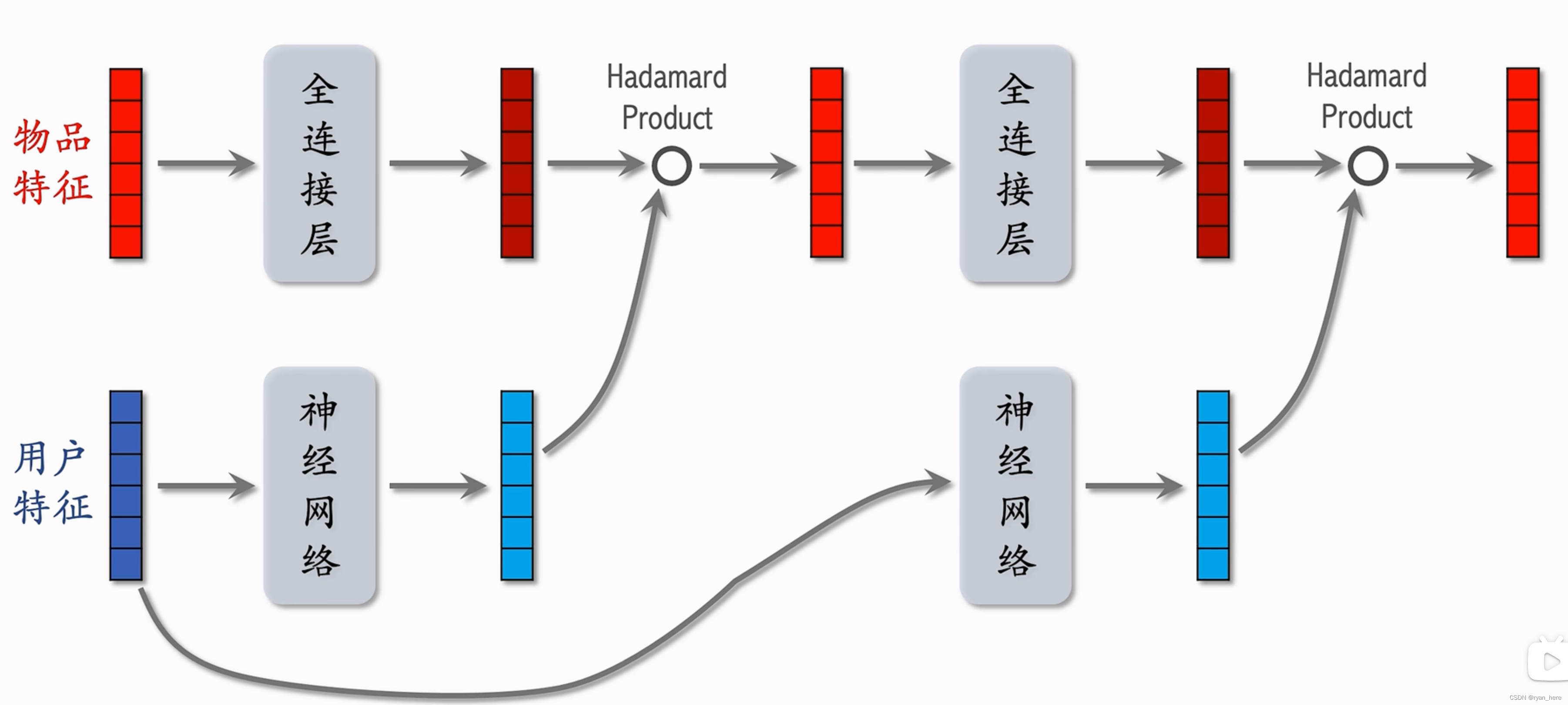
用户特征的多个全连接层,最后一个激活函数式 sigmoid * 2 (每个元素都在0-2之间)
SENet
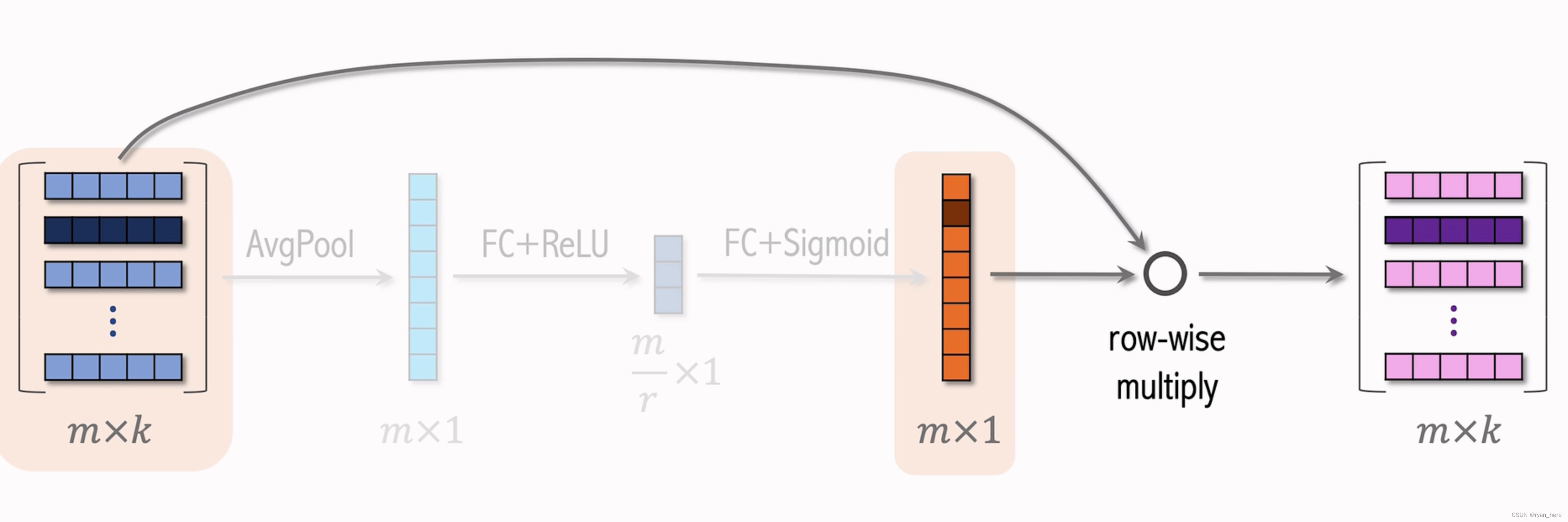
学出每个离散特征的权重,embedding的维度可以不同
field-wise:一个embedding中各维度的权重都是相同的
FiBiNet(精排)
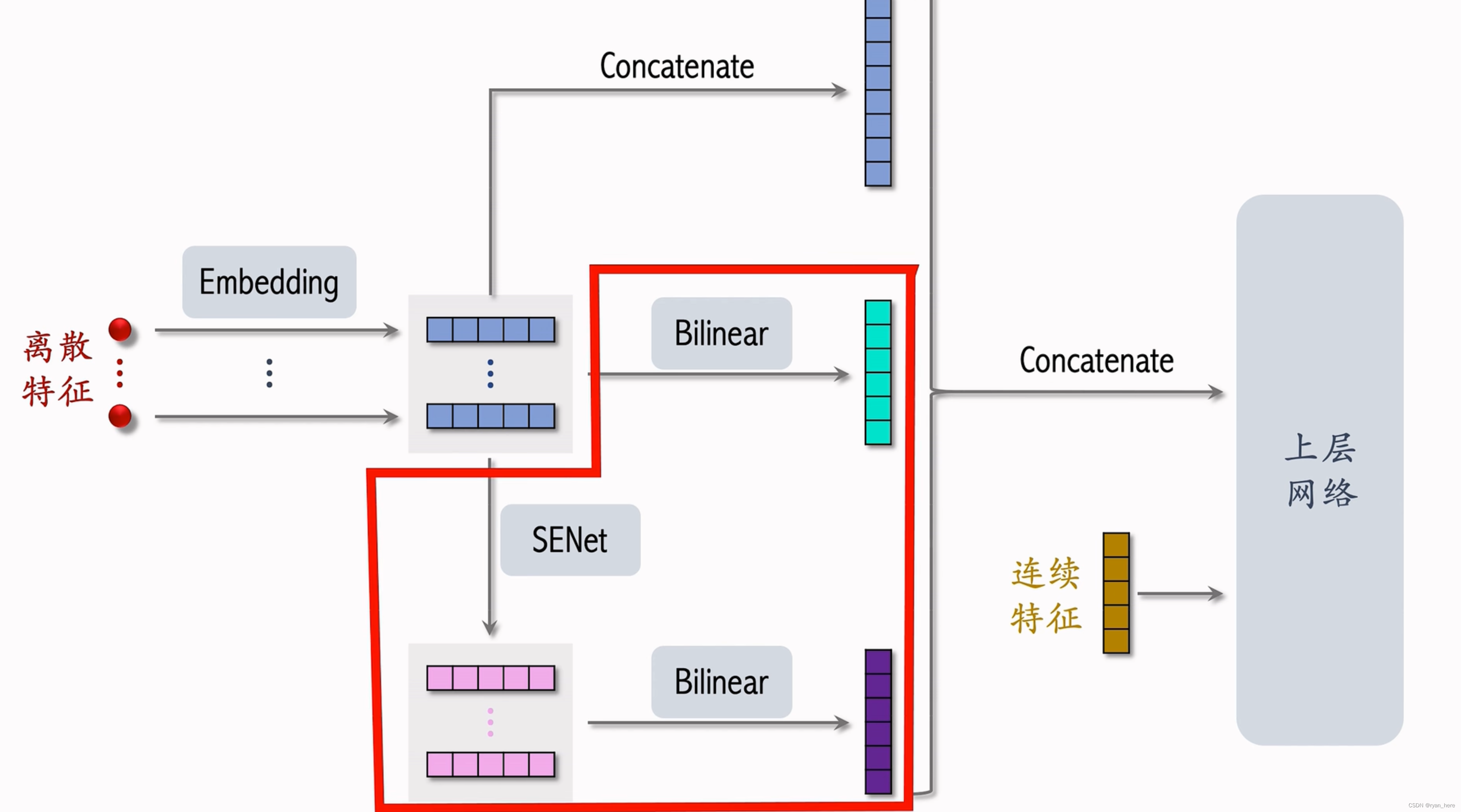
小红书作出改进,eg:小红书没有对SENet的结果做Bilinear cross
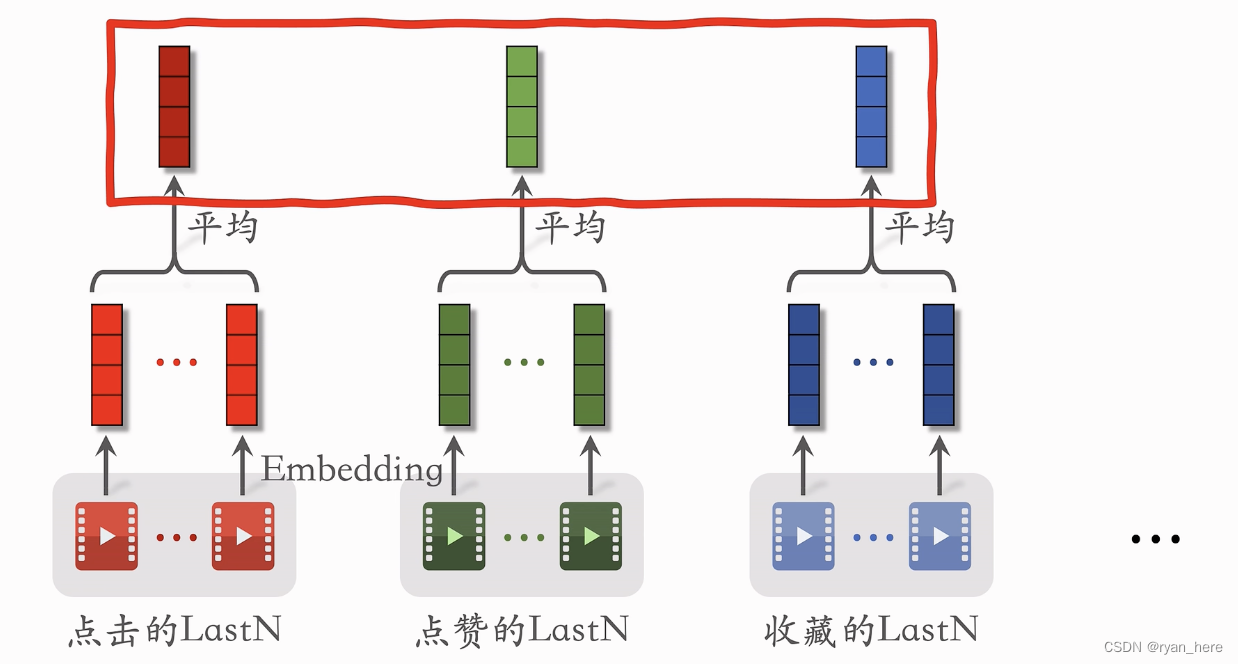
用户行为序列建模 last-n
简单平均模型
召回双塔模型、粗排三塔模型、精排模型
LastN:用户最近的n次交互(点击、点赞等)的物品ID
LastN物品做embedding后进行平均 作为一种用户行为特征
DIN模型
不适用于双塔和三塔,适用于精排
用加权平均代替平均,权重根据lastn物品与候选物品的相似度计算(内积...)
本质是注意力机制
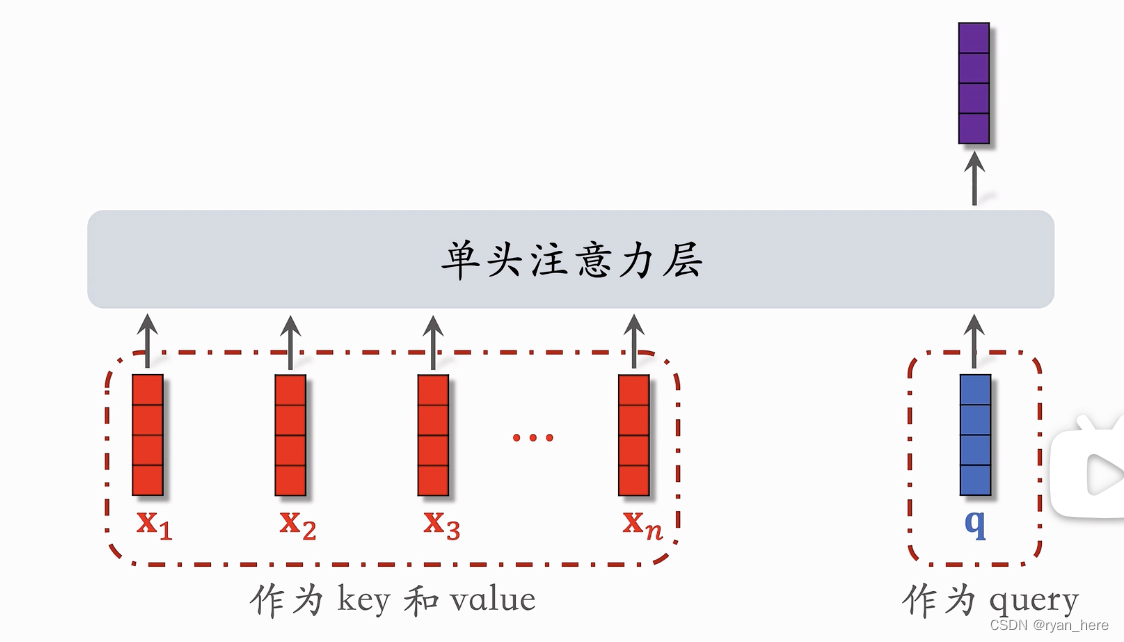
缺点:
- 计算量大,正比于lastn的n值,n的大小在100-200左右
- 关注短期兴趣,遗忘长期兴趣
SIM模型
- 减少计算量:如果lastN物品与候选物品差异很大,则权重接近于0
- Hard Search:类目查找 (速度快,运行容易)
- Soft Search:embedding最近邻查找 (效果更好,但编程实现复杂)
- 注意力机制:已经把LastN变成了TopK
trick:使用时间信息,交互时刻, 对
做离散化再做embedding,变成向量d

DIM短期序列不需要时间信息,但SIM使用长序列更加依赖时间信息
结论:
- 保留用户的长期兴趣
- 使用注意力机制优于简单平均
- 时间信息提升效果
推荐系统的多样性
- 作用:在排序后,只根据reward分数进行排序不够,还需要保证推荐的多样性
- 相似度度量
- 物品属性标签:类目、品牌、关键词
- 物品向量表征:双塔模型的物品塔特征不适用于多样性问题(双塔模型对长尾物品学习差),最好是基于图文内容的物品表征(CLIP)
MMR - Maximal Marginal Relevance
候选物品的分数:,
...
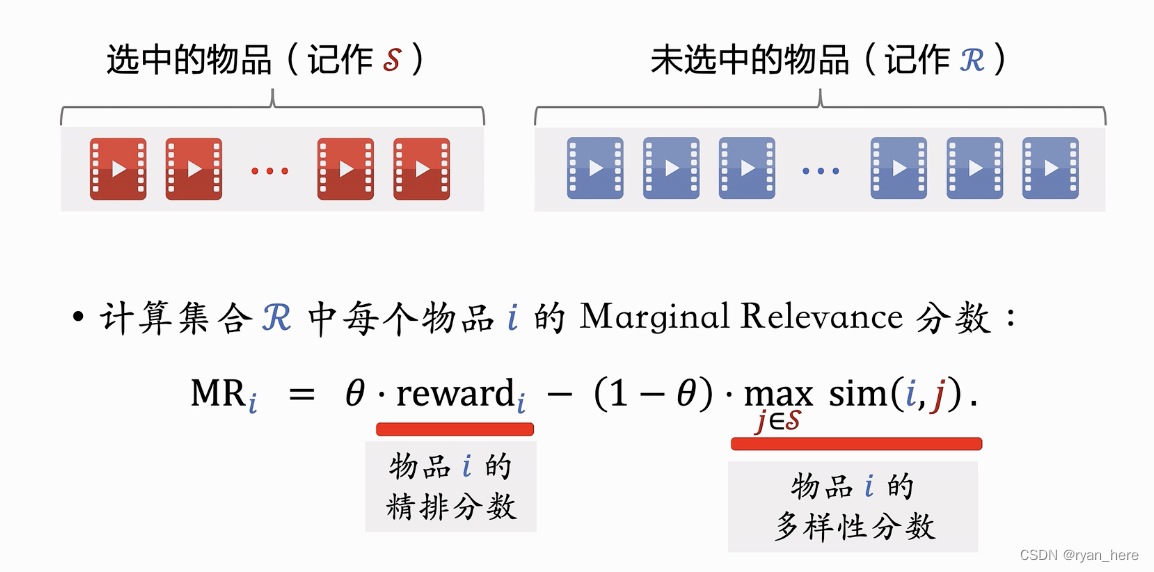
每次选择MR分数最高的未选中物品,移入选中的物品
滑动窗口MMR:将最近加入的n个物品作为滑动窗口w,代替整个选中的物品,防止在后期sim总是等于1使得MMR失效
MMR + 重排规则:
- 规则的重要性 > MMR
- 仅需要把集合R替换为符合规则的R'
DPP 【*】(最好的多样性算法)
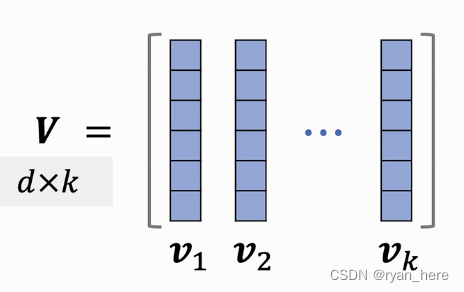
使用超平行体的体积衡量物品的多样性,将K个物品表征为单位向量,
,...
(k的大小不能超过d)
如果超平行体的体积最大,说明,
,...
两两正交,多样性好
![]()
行列式和体积之间是相同的,因此可以用行列式衡量物品多样性
贪心算法求解:

是给本来的行列式加上未选物品的一行一列, 如果物品与矩阵内物品相似,行列式会等于0
Hulu算法:Cholesky分解
重排
规则
- 最多连续出现k篇每种笔记(视频/图文)
- 每K篇笔记最多出现1篇某种笔记(运营推广的笔记精排分数会乘以boost(> 1))
- 前t篇笔记最多出现k篇某种笔记 (top t 对用户体验最重要,k 带电商卡片的笔记)
特征交叉
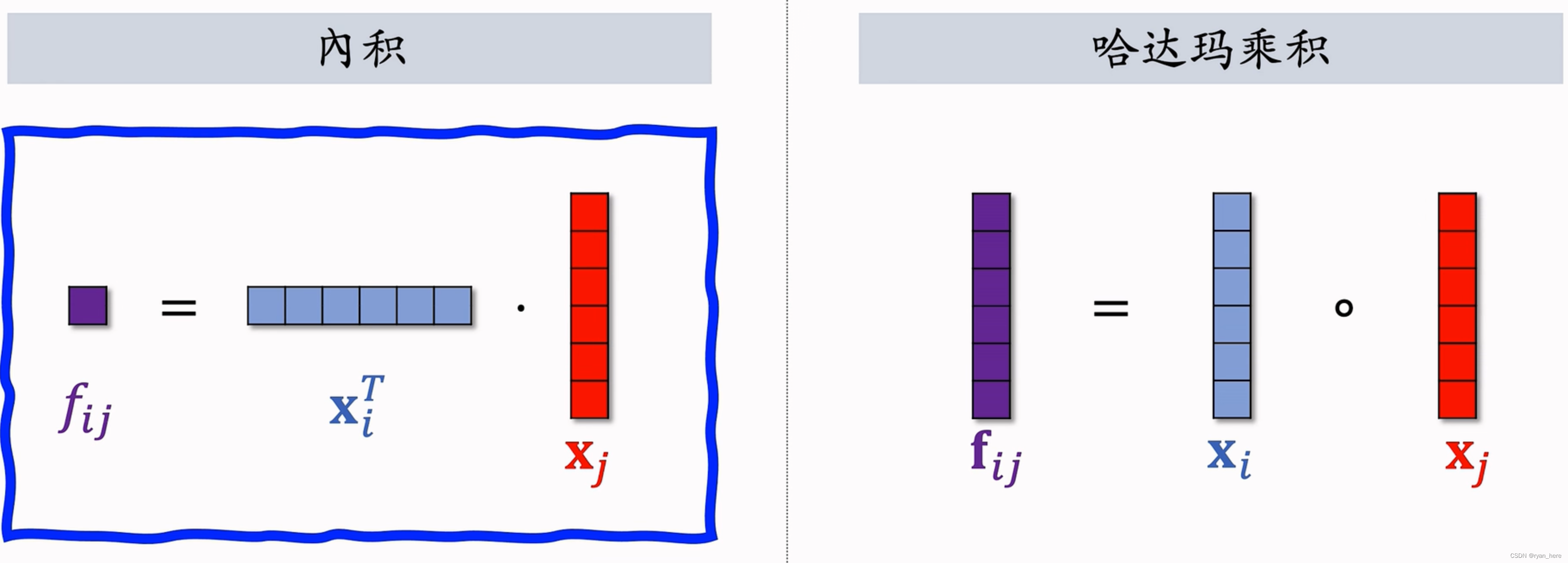
结果:m * m 个实数 结果:m * m个向量
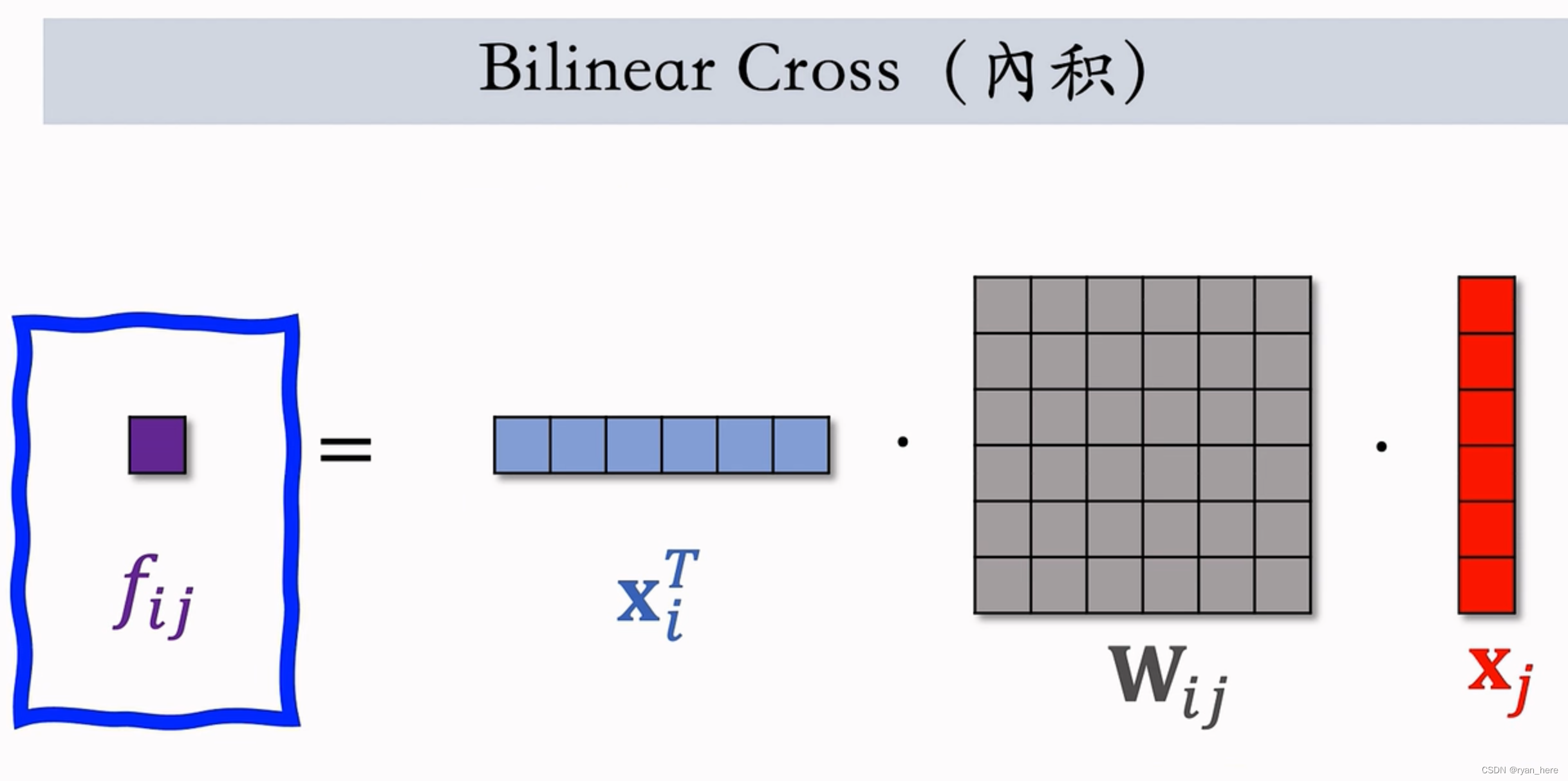
结果: m * m 个实数, m fields 对应 参数矩阵(参数太大,需要人工指定特征做交叉)
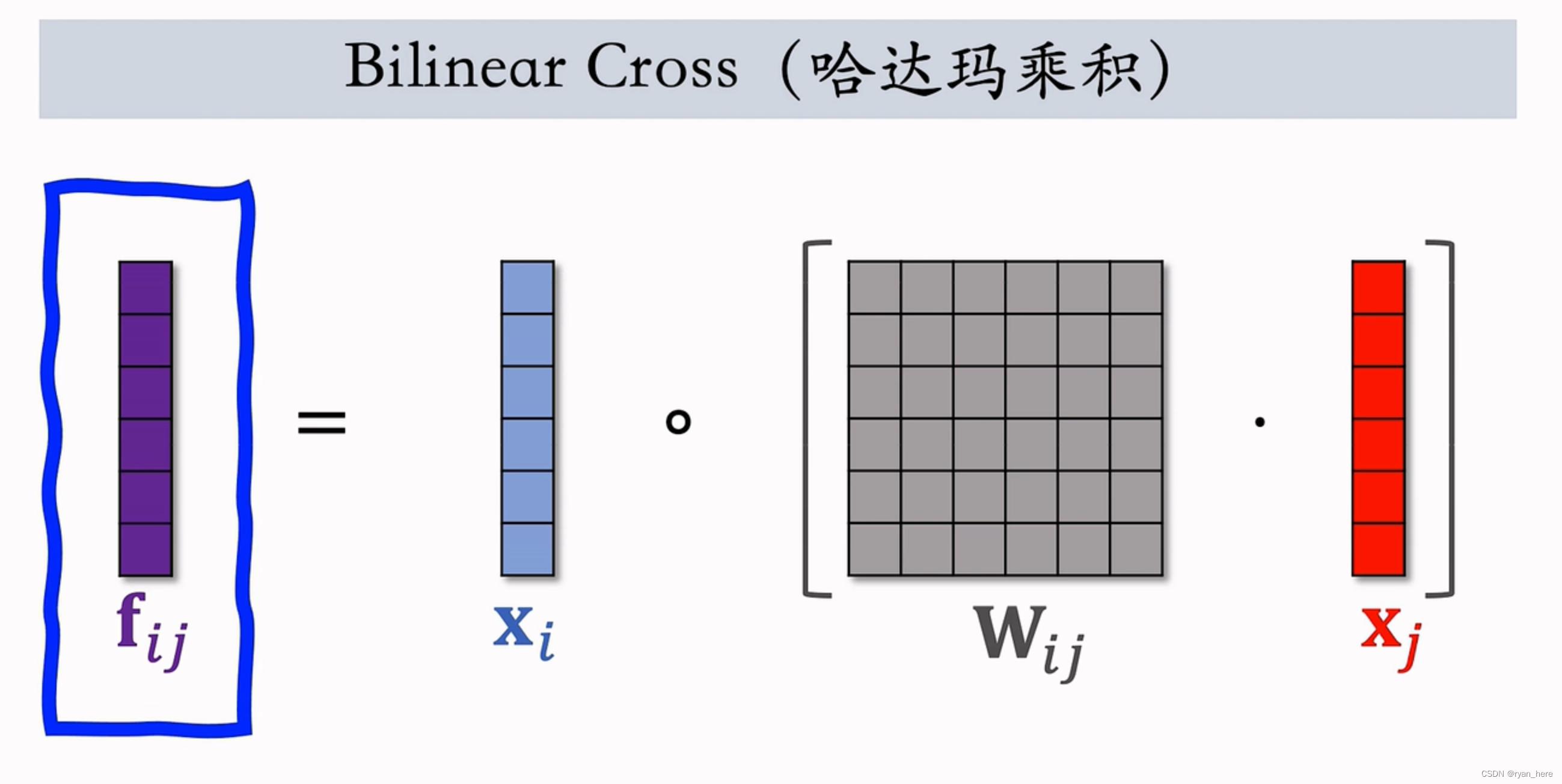
m fields -> 个向量(参数太大,需要人工指定特征做交叉)
冷启动
特殊地对待新笔记:新笔记缺少用户交互,导致推荐难度大,效果差
- 用户侧指标:新笔记消费指标、大盘消费指标
- 作者侧指标:发布渗透率、人均发布量
- 内容侧指标:高热笔记占比
1. 缺少用户交互,没有学好笔记ID embedding,导致双塔模型效果不好
2. 缺少用户交互,不适用itemCF
改良双塔模型
多个召回池:1h新笔记、24h新笔记...
1. 所有新笔记使用default embedding
2. 相似笔记的embedding 向量取平均
基于类目的召回
索引:
- 类目 -> 笔记(时间顺序倒排)
- 用户画像 -> 类目 -> 笔记
基于关键词的召回
聚类召回【*】
用户喜欢一篇笔记,会喜欢内容相似的笔记
K-means
索引:cluster中心向量 -> 笔记ID列表(按时间倒排)
![]()
内容相似度模型:
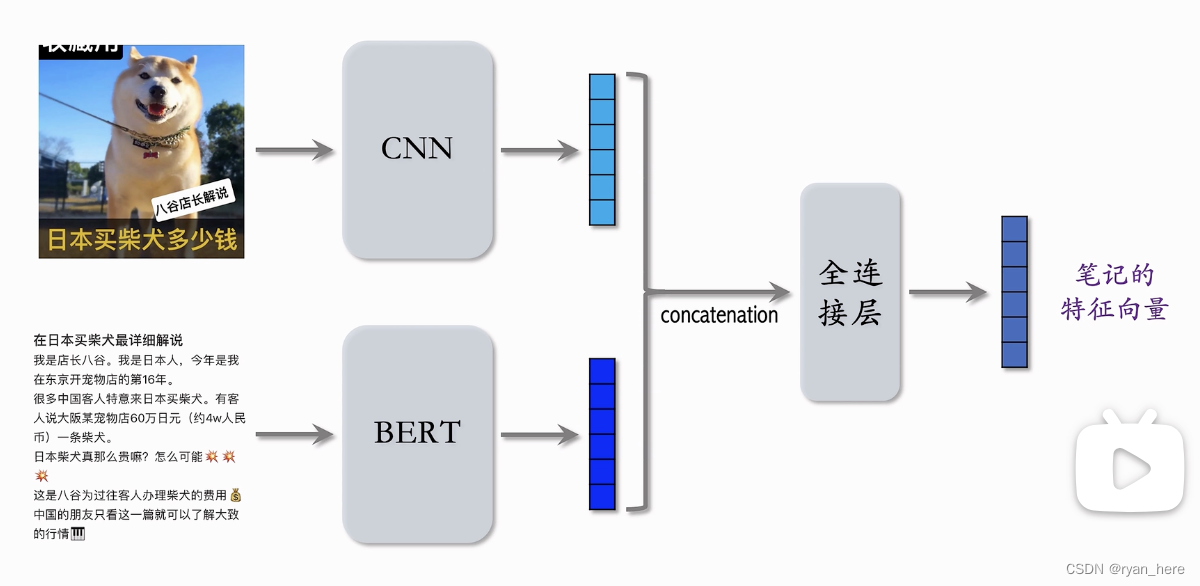
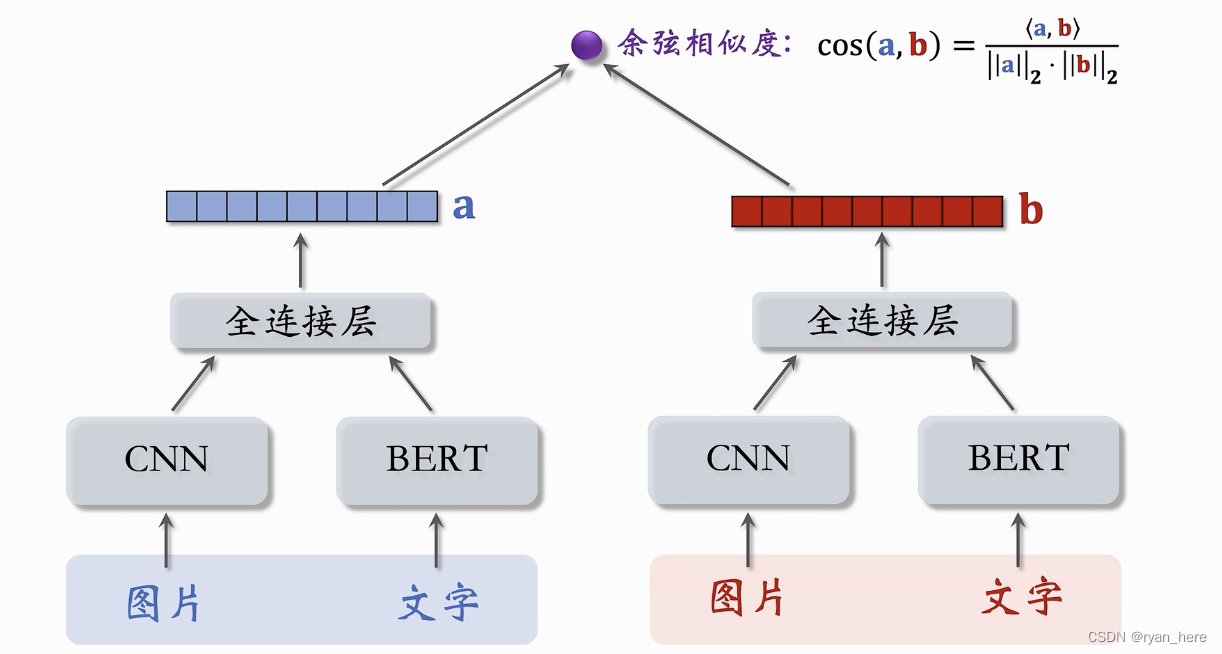
bert、CNN是预训练好的模型,也可以做fine tune
正样本:
- 高曝光的笔记
- 相同的二级类目
- itemCF的物品相似度进行筛选
负样本:保证笔记质量高
Look-Alike人群扩散【*】
用于互联网广告
种子用户:满足条件的用户
Look-Alike用户:潜在满足条件的用户
- UserCF方法
- ID embedding用法
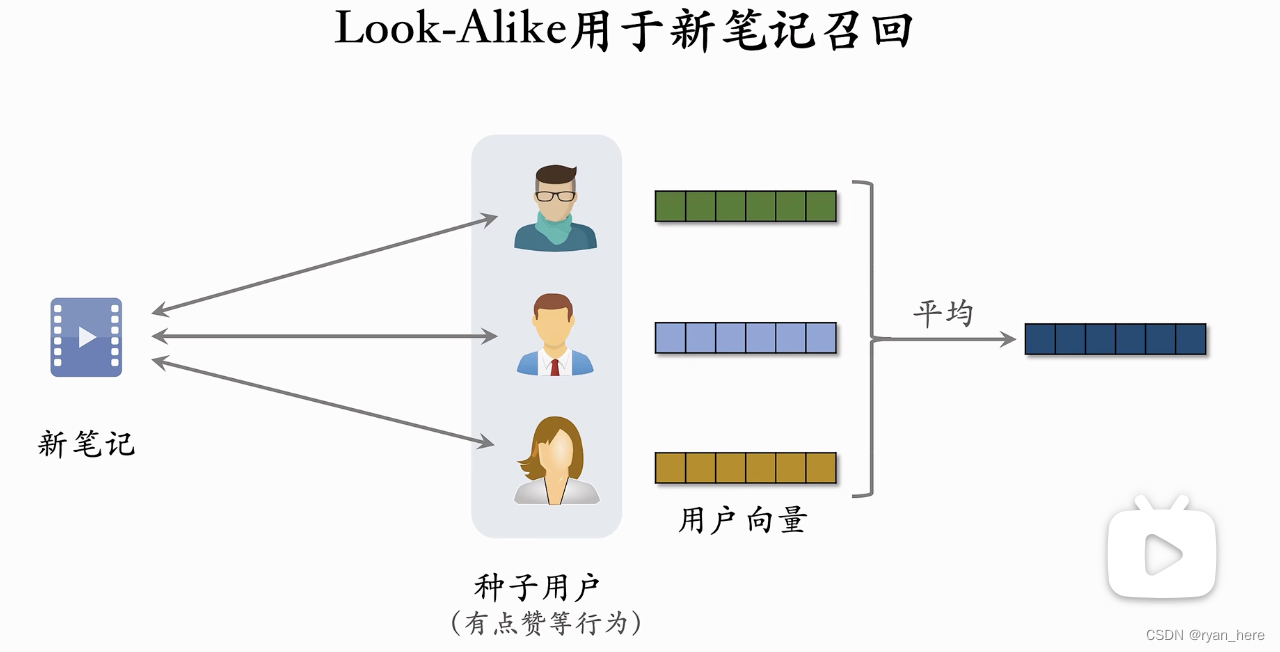
近线更新:不是实时更新,做到分钟级
流量调控
抓手:1.单独召回通道 2. 对新笔记进行提权

- 推荐结果强插新笔记(落后)
- 对新笔记的排序分数做提权(抖音、小红书前期)【*】(缺点:超参数设置,过度/不充分)
- 通过提权,对新笔记做保量
- 差异化保量
如何提权:粗排、重排,使新笔记比老笔记更有优势
如何保量(对小厂较困难)
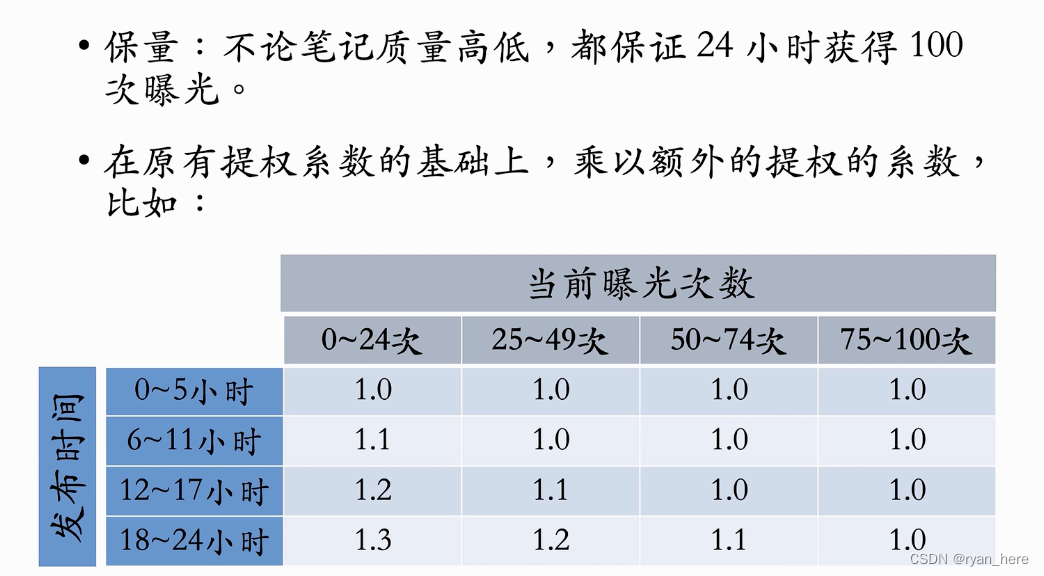
动态提权保量

差异化保量:普通笔记保100次曝光,内容优质的笔记保100-500次曝光
内容质量预测模型、作者质量、
冷启动的AB测试
工业级技巧
存储技巧
- 使用离线存储,建立索引
- 向量方式: 物品端存入向量数据库,用户端在线计算
全量更新VS增量更新
- 全量更新【*】
- 日频批量更新
- 增量更新【*】
- 小时/分钟级别更新
- 实时收集线上数据,流式处理,生成 TFRecord文件
- 更新embedding层但不更新MLP(frozen)的参数
- 既要做全量更新也要做增量更新
2. 正负样本选择
正样本:曝光且有点击,热门物品占据大部分点击(上采样冷门/下采样热门)
负样本:混合几种负样本 50%简单负样本 50%困难负样本
- 简单负样本
- 全体抽样(负样本约等于全体样本):因为正样本中大多是热门物品,如果均匀抽样会导致冷门物品基本进入负样本,使得冷门物品不会被推荐,对冷门物品不利。因此需要提高热门物品在负样本中的比例,采用非均匀抽样【抽样概率 正比于
】越热门则抽样概率更高
- batch内负样本:物品出现在batch内的概率 正比于
- 全体抽样(负样本约等于全体样本):因为正样本中大多是热门物品,如果均匀抽样会导致冷门物品基本进入负样本,使得冷门物品不会被推荐,对冷门物品不利。因此需要提高热门物品在负样本中的比例,采用非均匀抽样【抽样概率 正比于
Xinyang Yi et al. Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations. In RecSys, 2019
- 困难负样本:被排序模型过滤掉的
3. 余弦相似度、交叉熵损失
4. 模型存储
用户数据:key-value表 key时用户ID,value是embedding
5. 近似最近邻查找(避免暴力枚举)
- 欧式距离最小(L2距离)
- 向量内积最大
- 余弦相似度最大【*】
欧几里得距离:
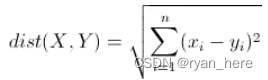
欧氏距离是最常见的距离度量,衡量的是多维空间中各个点之间的绝对距离。
内积:
![]()
![]()
b向量在a向量方向上的投影
余弦相似度:
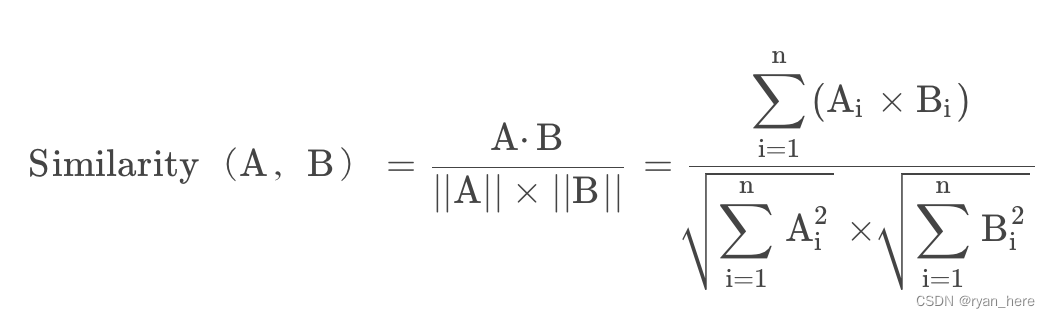
余弦相似度(Cosine Similarity)是n维空间中两个n维向量之间角度的余弦。它等于两个向量的点积(向量积)除以两个向量长度(或大小)的乘积。
余弦相似度越大(越接近1)代表夹角越小,两个向量越接近

















 2704
2704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









