# -*- coding: utf-8 -*-"""
Created on Sat Jun 26 10:48:33 2021
@author: rwh
"""import requests
from bs4 import BeautifulSoup
import os
DOI =[]
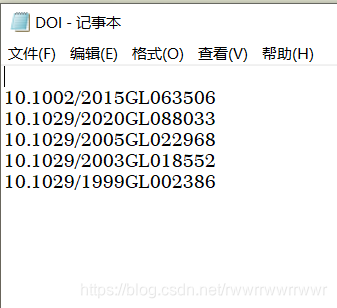
f =open("C:/Users/lenovo/Desktop/DOI.txt","r", encoding="utf-8");for line in f.readlines():
line = line[:-1]
DOI.append(line)
DOI = DOI[1:-1]
path ="G:/rwh/研一/sci_hub文献下载"if os.path.exists(path)==False:
os.mkdir(path)
head ={\
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'\
}for doi in DOI:
url ="https://www.sci-hub.ren/"+ doi
print(url)
r = requests.get(url, headers = head)
r.raise_for_status()
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,"html.parser")
download_url = soup.iframe.attrs["src"]#20210515更新print(doi +" is downloading...\n --The download url is: "+ download_url)
download_r = requests.get(download_url, headers = head)
download_r.raise_for_status()
f =open(path +"/"+doi.replace("/","_")+".pdf","wb")
f.write(download_r.content)
























 9698
9698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









