







我初学正则式时看到一大堆杂乱无章的乱码就头大,但是其实你了解了其中的意义你会觉得正则式很神奇很好用。那么现在我以另外一种比较啰嗦的方式来讲解正则式:
基本知识
正则最大的用途用来从杂乱的信息中抽取自己需要的信息或者进行字符串的验证。而正则式最大的好处是它能够使用某些约定好的正则字符串(这个我们一般称为正则表达式)来匹配有特殊意义的实际字符串。
正则字符:$,(),*,+,.,[,?,\,^, {,|
正则表达式由原生的字符(字符串中本来的字符)和正则表达式字符共同组成。它最大的特点是用规则字符来代替了实际的字符或者数字。一般的格式是一个规则字符加上数量表达式(例如\d{4,7})来匹配。有时候前面还加上位置符号^或者$
看看这个正则表达式[\w-]+@[a-z]{2,6}.com|cn|net
分为五部分:1[\w-]+ 2@ 3[a-z]{2,6} 4. 5com|cn|net
[]在正则式中有特殊含义,方括号是单个匹配 字符集/排除字符集/命名字符集。[]中的字符是定义匹配的字符范围.\w是正则式(它表示从a-z以及A-Z还有_符号这些东西里面的任意挑出一个。请注意这里只有一个。);+表示限定符,表示随机挑选的次数至少大于1。
[\w-]括号里面多了一个-。那么表示的是这个括号匹配的是(a-z加上A-Z加上_加上- 这个范围里面其中任意一个字符),
@和.就是匹配原生字符串中和@和. 除非是特定的正则表达式,一般来说不加任何修饰的字符表示的就是原生字符串中的字符。
[a-z]{2,6}表示的是一个字符串。相当于是从a-z中任意挑选一个字符,挑选2次-6次。
com|cn|net表示的com,cn,net这三个字符串中的任意挑选其中一个都是合法的。
那么,uyt-@ytr.com我随便编出来的这个字符串是否符合上面的正则式呢?显然是符合的。uuu_er@sina.net这个字符串也是符合的。正则式的魅力在于只要设定好你需要的规则这个正则式可以匹配成百上千条记录。
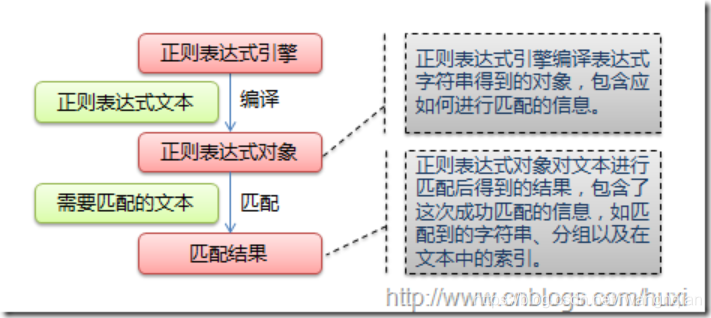
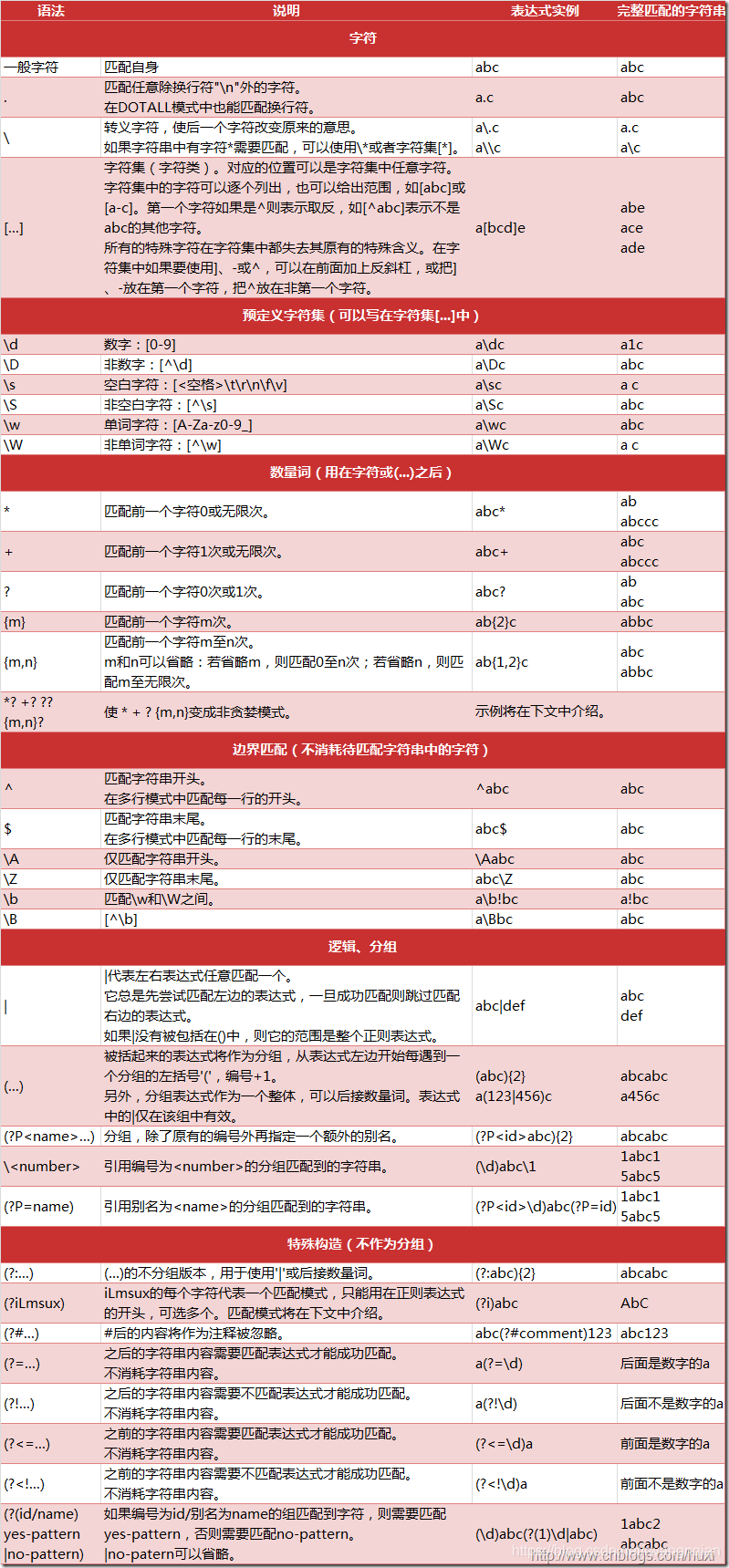
那么正则式的重点在于区别于原生字符串和正则表达式符号,下图列出了Python支持的正则表达式元字符和语法:
捕获组和非捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。
例如: /(a)(b)(c)/中的捕获组编号为
- 组
0:abc - 组
1:a - 组
2:b - 组
3:c
其中,组0是正则表达式整体匹配结果,组1,2,3才是子表达式匹配结果
- 子表达式捕获组编号从
1开始,顺序从左到右(例如编号1是左侧第一个()包裹的子表达式的结果) - 可以在正则表达式中对前面捕获的内容进行引用(反向引用)
- 也可以在程序中,对捕获组捕获的内容进行引用(比如
replace中)
str="2017-07-29"
pal=re.compile(r'(\d{4})-(\d{2})-(\d{2})')
bb=re.search(pal,str)
print(bb.groups())
上述可以看到()包括的内容默认匹配时都在捕获组中
但是有时候,因为特殊原因用到了(),但又没有引用它的必要,这时候就可以用非捕获组声明,防止它作为捕获组,降低内存浪费
?:可以声明一个子表达式为非捕获组
a_str='abcd0123ABCD'
a_pal=re.compile(r'(?:[a-z]+)(\d+)([A-Z]+)')
cc=re.search(a_pal,a_str)
print(cc.groups())可以看到,(?:[a-z]+)将这个子表达式声明成了非捕获组,因此捕获组的编号直接跳过了它,从下一个(\d+)开始
在捕获字符串设置条件的时候使用了[a-z]+,但是我们不需要用到这个子组,所以使用非捕获组跳过它。
re模块中的特殊符号 元符号用法和例子
.
默认模式下,匹配换行符以外的任何字符。若 re.DOTALL标志被指定,则它匹配换行符在内的任何字符。
例:>>> re.search('.',"I love China")
<_sre.SRE_Match object; span=(0, 1), match='I'>
^
从字符串的开始匹配, 在 re.MULTILINE模式下每个换行符后面立即开始匹配。
例:>>> re.search(r'^ab',"abcdefg")
<_sre.SRE_Match object; span=(0, 2), match='ab'>
$
与上面的相对,匹配字符串的结尾或只是之前换行符结尾的字符串,并在 re.MULTILINE 模式下也匹配在换行符之前。
例:>>> re.search(r'fg$',"abcdefg")
<_sre.SRE_Match object; span=(5, 7), match='fg'>
*
匹配前面的子表达式零次或多次(贪婪模式1),等价于{0}。
例:>>> re.search(r'a*','aaaaaab')
<_sre.SRE_Match object; span=(0, 6), match='aaaaaa'>
+
匹配前面的子表达式一次或多次(贪婪模式),等价于{1}。
例:>>> re.search(r'a+','aaaaaab')
<_sre.SRE_Match object; span=(0, 6), match='aaaaaa'>
?
匹配前面的子表达式零次或一次,等价于{0,1}。
例:ab?将匹配'a'或'ab'。
*?,+?,??
默认情况下,*,+,?是贪婪模式,后面再加个?可以启用非贪婪模式。
例:>>> re.search(r'a*?','aaaaaab')
<_sre.SRE_Match object; span=(0, 0), match=''>
{m}
精确的指定RE应该被匹配m次,少于m次将导致RE不会被匹配上。
例:>>> print(re.search(r'a{5}','aaaab'))
None
{m,n}
m和n都为非负数,且m<n,其表示前面的RE匹配[m,n],默认也为贪婪模式,后面加上?后可启用非贪婪模式。省略m指定零为下限,省略n指定无穷大为上限。2
例:>>> re.search(r'a{1,4}','aaaaaaab')
<_sre.SRE_Match object; span=(0, 4), match='aaaa'>
\
特殊符号消除术,消除特殊字符含义(允许匹配像'*', '?',等特殊字符), 或者发出特殊序列信号。
例:>>> re.search(r'\.','www.aoxiangzhonghua.com')
<_sre.SRE_Match object; span=(3, 4), match='.'>
[]
用来表示一个字符集合。在这个集合中:
例如:>>> re.search(r'[\[]',"[]")
<_sre.SRE_Match object; span=(0, 1), match='['>
字符可以被单独罗列,例如:[amk] 会匹配 'a', 'm', 或 'k'.
字符范围可以表明通过给予两个字符和分离他们的 '-'。例如 [a-z] 将匹配任何小写字母的 ASCII 字母,[0-5] [0-9] 将匹配所有两位数数字从 00 到 59,和 [0-9A-Fa-f] 将都匹配任何十六进制数字。如果-被转义(例如,[a\-z]),或者将它放置为第一个或最后一个字符(例如,[a-]),它将匹配字符'-'。
在集合内,特殊字符失去特殊意义。例如,[(+*)] 将匹配任何字符 '(','+','* ',或 '')''。
如\w or \S等字符类别也是可以被接受的,并且不会失去特殊意义,尽管匹配的这些字符取决于re.ASCII or re.LOCALE 模式是否被设置。
如果这个集合的第一个字符是'^', 那么所有不在集合内的将会被匹配上。例如, [^5]将会配对除 '5'以外的任何字符,并且和[^^]将会匹配除'^'以外的任何字符。如果^不在集合的第一个位置那么它将没有特殊意义。
想要在一个集合内匹配']',需要在它的前面使用一个反斜杠转义,或者在集合开头处将它替换。
|
类似于C语言中的或操作,A|B表示匹配正则表达式A或者B。
例:>>> re.search(r'ab|cd','acdf')
<_sre.SRE_Match object; span=(1, 3), match='cd'>
(...)
子组,将匹配圆括号内的正则表达式,并指明子组的开始和结束。子组的内容可以在后面通过\number再次引用(稍后提及)。
例:>>> re.search(r'(efg)','abcdefghj')
<_sre.SRE_Match object; span=(4, 7), match='efg'>
特殊语法:
(?aiLmsux)
例:>>> re.search(r'(?i)CHINA','我爱China')
<_sre.SRE_Match object; span=(2, 7), match='China'>
?后可跟'a', 'i', 'L', 'm', 's', 'u', 'x'中的一个或多个
用来设置正则表达式的标志,每个字符对应一种匹配标志:a (仅匹配ASCII), i (不管大小写), L (区域设置), m (多行模式), s (不匹配所有), and x (详细表达式)。
(?:...)
非捕获组,即该子组匹配的字符串无法从后面获得。
例:>>> re.search(r'(?:China)\1','ChinaChina')
Traceback (most recent call last)。。。报错
(?P<name>...)
为匹配的正则表达式取别名(即除了原有的编号外再指定一个额外的别名),<>为取的别名,每个组名称在正则表达式中只能被定义一次。
(?P=name)
引用别名为name的子组。
例:>>> print(re.search(r'(?P<love>China)(?P=love)','aaaChinaChinabbb'))
<_sre.SRE_Match object; span=(3, 13), match='ChinaChina'>
(?#...)
注释,将忽略括号内的内容。
例:>>> re.search(r'(?#啦啦啦)China','I love China')
<_sre.SRE_Match object; span=(7, 12), match='China'>
\number
匹配相对应子组编号的内容,组号从1开始。该特殊序列只能用于匹配前99个组中的一个。如果number的第一个数字为0或number为3个八进制数字,则不会将其解释为组匹配,而是八进制值,这时表示对应ASCII值的字符。
例:>>> re.search(r'(I (love))\2','I lovelove China')
<_sre.SRE_Match object; span=(0, 10), match='I lovelove'>
\A
仅仅匹配字符串开头。
例:>>> re.search(r'\AI','I love China')
<_sre.SRE_Match object; span=(0, 1), match='I'>
\b
匹配一个单词的边界。这里的单词的定义是由Unicode字母数字或下划线组成的序列,因此单词的边界由空格、非字母数字或非下划线Unicode字符表示。我们可以这么简单理解,一个\b即替代一个空格、非字母数字或非下划线Unicode字符表示的边界。默认情况下,使用Unicode字母和数字,但可以通过使用re.ASCII标志来更改。在字符范围内,\b表示退格字符,以便与Python的字符串字面值兼容。
例:>>> re.search(r'\blove\b','I love China')
<_sre.SRE_Match object; span=(2, 6), match='love'>
\b不仅表示的是一个空格,
从这些分割的字符串中我们可以知道单词边界就是单词和符号之间的边界
这里的单词可以是中文字符,英文字符,数字;
符号可以是中文符号,英文符号,空格,制表符,换行
了解了\b的用法 我们再来说说\B \B是非单词边界
也就说\B=[^\b] //符号^是非的意思
运行下列程序就可以得到结果,\b表示的是一个突变,由字符到符号的突变。
str3='171.38.85.122;,;jjakjfa;; 我的撒酒疯扣篮房;'
pr=re.compile(r'\b([\u4e00-\u9fa5]+)\b')
pr1=re.compile(r'\b(\w+)\b')
pr2=re.compile(r'\b(\d+)\b')
print(re.findall(pr,str3))
print(re.findall(pr1,str3))
print(re.findall(pr2,str3))
\B
与\b作用相反,匹配非单词边界。
例:>>> re.search(r'\Blove\B','IloveChina')
<_sre.SRE_Match object; span=(1, 5), match='love'>
\d
对于Unicode模式:
匹配任何Unicode十进制数字。这包括[0-9]以及许多其他数字字符。如果使用re.ASCII标志,则只匹配[0-9](但该标志影响整个正则表达式,因此在这种情况下使用明确的[0-9]可能是更好的选择)。
对于ASCII模式:
匹配任何十进制数字;这相当于[0-9]。
例:>>> re.search(r'\d\d','I 52 China')
<_sre.SRE_Match object; span=(2, 4), match='52'>
\D
匹配任何不是Unicode十进制数字的字符。这与\d相反。如果使用re.ASCII标志,则这变成等效于[^0-9](但该标志影响整个正则表达式,所以在这种情况下使用明确的[^0-9]可能是更好的选择)。
例:>>> re.search(r'\D','5 love China')
<_sre.SRE_Match object; span=(1, 2), match=' '>
\s
对于Unicode模式:
匹配Unicode空白字符(包括[ \t\n\r\f\v]以及许多其它字符,例如在许多语言中由排版规则强制不换行的空白)。如果使用re.ASCII标志,则只匹配[ \t\n\r\f\v](该标志会影响整个正则表达式,所以在这种情况下,使用明确的[ \t\n\r\f\v]可能是更好的选择)。
对于ASCII模式:
匹配ASCII字符集中空白的字符;相当于[ \t\n\r\f\v]。
例:>>> re.search(r'\s','I love China')
<_sre.SRE_Match object; span=(1, 2), match=' '>
\S
作用与\s相反,匹配不是Unicode空白字符,如果设置re.ASCII标志,则相当于[^ \t\n\r\f\v]。
例:>>> re.search(r'\S','I love China')
<_sre.SRE_Match object; span=(0, 1), match='I'>
\w
对于Unicode模式:
匹配Unicode字符,这包括大多数可以是任何语言的单词的一部分的字符,以及数字和下划线,注意,不能匹配逗号,句号,问号等符号。
对于ASCII模式:
匹配ASCII字符集,这相当于[a-zA-Z0-9_]。
例:>>> re.search(r'\w','I love China')
<_sre.SRE_Match object; span=(0, 1), match='I'>
\W
与\w作用相反,匹配非Unicode字符,如果设置了re.ASCII标志,则不匹配ASCII字符。
例:>>> re.search(r'\W','I love China')
<_sre.SRE_Match object; span=(1, 2), match=' '>
\Z
只匹配字符串结尾。
例:>>> re.search(r3'China\Z','I love China')
<_sre.SRE_Match object; span=(7, 12), match='China'>
转义字符 正则表达式还支持大部分 Python 字符串的转义符号:\a,\b,\f,\n,\r,\t,\u,\U,\v,\x,\\
总结一下:
.、\s和\S
首先说下.
- 定义是除
\n以外的任何字符 - 但是,在一些
Chrome、Firefox等内核中,代表\n和\r以外的字符 - 如果要匹配
.本身,请用\.
再说说\s与\S
\s是匹配所有的空白字符,包括空白、换行、tab缩进等所有空白\S是指除了空白以外的任何字符(和.区别下,.里面还多了一部分空白)
那如何匹配所有字符呢?
(.|\n)或者是[\s\S](推荐用法)- 请不要试图使用
[.\n]或[\.\n],这种写法只表示小数点或\n字符中的一个
捕捉分组
1.捕获分组
先了解在正则中捕获分组的概念,其实就是一个括号内的内容
如 "(\d)\d" 而"(\d)" 这就是一个捕获分组,
可以对捕获分组进行 后向引用 (如果后而有相同的内容则可以直接引用前面定义的捕获组,以简化表达式)
如(\d)\d\1 这里的"\1"就是对"(\d)"的后向引用
那捕获分组有什么用呢看个例子就知道了
如 "zery zery" 正则 \b(\w+)\b\s\1\b 所以这里的"\1"所捕获到的字符也是 与(\w+)一样的"zery",
为了让组名更有意义,组名是可以自定义名字的
"\b(?P<name>\w+)\b\s\k<name>\b"
用"?P<name>"就可以自定义组名了而要后向引用组时要记得写成 "\k<name>";
自定义组名后,捕获组中匹配到的值就会保存在定义的组名里
下面列出捕获分组常有的用法
"(exp)" 匹配exp,并捕获文本到自动命名的组里
"(?P<name>exp)" 匹配exp,并捕获文本到名称为name的组里
"(?:exp)" 匹配exp,不捕获匹配的文本,也不给此分组分配组号
不捕获就是在分组的前边加上?:,可以在不需要捕获分组的表达式中使用,加快表达式执行速度。
总结:
1.捕获分组的用处很大,可以把一段代码分成几组并对每组字符进行类似format的处理。
2.当你需要找到某个字符串,而它前面是个字母M的时候。使用(?:)跟(?<=)或直接M这三种方式有什么区别?首先前面两种都是不捕捉只是判定前面字符是否是M;当你需要寻找字符串前面是M的时候(?:M)跟(?<=M)都可以用,但是当你需要寻找字符串前面不是N的时候,只能使用(?<!N);
零宽断言
需要首先理解前瞻,后顾,负前瞻,负后顾四个概念。
"(?=exp)" 匹配exp前面的位置
如 "How are you doing" 正则"(?<txt>.+(?=ing))" 这里取ing前所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为"How are you do";
"(?<=exp)" 匹配exp后面的位置
如 "How are you doing" 正则"(?<txt>(?<=How).+)" 这里取"How"之后所有的字符,并定义了一个捕获分组名字为 "txt" 而"txt"这个组里的值为" are you doing";
"(?!exp)" 匹配后面跟的不是exp的位置
如 "123abc" 正则 "\d{3}(?!\d)"匹配3位数字后非数字的结果
"(?<!exp)" 匹配前面不是exp的位置
如 "abc123 " 正则 "(?<![0-9])123" 匹配"123"前面是非数字的结果也可写成"(?!<\d)123"
就拿匹配<title>xxx</title>标签来说,我们想要的是xxx,它没有规律,但是它前边肯定会有<title>,后边肯定会有</title>,这就足够了。
想指定xxx前肯定会出现<title>,就用正后发断言,表达式:(?<=<title>).*
想指定xxx后边肯定会出现</title>,就用正先行断言,表达式:.*(?=</title>)
两个加在一起,就是(?<=<title>).*(?=</title>)
!表示正好相反的意思,就是把=换成了!,看表格解释,X代表字符
(?=X )
零宽度正先行断言。仅当子表达式 X 在 此位置的右侧匹配时才继续匹配。例如,\w+(?=\d) 与后跟数字的单词匹配,而不与该数字匹配。此构造不会回溯。
(?!X)
零宽度负先行断言。仅当子表达式 X 不在 此位置的右侧匹配时才继续匹配。例如,例如,\w+(?!\d) 与后不跟数字的单词匹配,而不与该数字匹配 。
(?<=X)
零宽度正后发断言。仅当子表达式 X 在 此位置的左侧匹配时才继续匹配。例如,(?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。
(?<!X)
零宽度负后发断言。仅当子表达式 X 不在此位置的左侧匹配时才继续匹配。例如,(?<!19)99 与不跟在 19 后面的 99 的实例匹配
(?=...)
前向肯定断言,如果...匹配后面的内容则匹配,但不消耗字符串的任何字符,很绕对不对,看个例子。
例:
a=re.search(r'love (?=China)','I love China')
print(a)
#<_sre.SRE_Match object; span=(2, 7), match='love '>
print (a.group())
#love
说明:找出love加上空格这个词组(条件限定是这个词组后面必须跟着china)
(?!...)
与上一个作用相反,如果...不匹配时后面的内容时才算匹配,也举个例子。
例:>>> re.search(r'love (?!America)','I love China')
<_sre.SRE_Match object; span=(2, 7), match='love '>
(?<=...)
后向肯定断言,只有当...匹配之前的内容时才算匹配,举个例子就懂。
例:>>> re.search(r'(?<=I) love','I love China')
<_sre.SRE_Match object; span=(1, 6), match=' love'>
(?<!...)
与上一个作用相反,如果...不匹配之前的内容才算匹配,举个例子。
例:>>> re.search(r'(?<!Y) love','I love China')
<_sre.SRE_Match object; span=(1, 6), match=' love'>
(?(id/name)
yes-pattern|no-pattern)
如果具有给定 id 或 name 的组存在,将尝试匹配 yes-pattern,否则匹配 no-pattern。no-pattern是可选的,可以省略。又是神马意思,别急,举几个例子就懂。
例:>>> re.search(r'(I )(?(1)love|hate)','I love China') #说明,这里开始‘I ‘匹配,所以再启用yes-pattern进行匹配,这里即'love' ,这里的1是id,指代第一组子组,当然前面如果设置name,这里也可以用name来指代。
<_sre.SRE_Match object; span=(0, 6), match='I love'>
>>> re.search(r'(Y )?(?(1)hate|love)','I love China') #说明,这里开始’Y ‘不匹配,所以再启用no-pattern进行匹配,即'love'。这里第一个问号是为了当第一个括号中的内容不匹配时,跳过开头进行匹配,因为前面不匹配的内容会消耗字符串中等量的字符。
<_sre.SRE_Match object; span=(2, 6), match='love'>
反斜杠加普通字符 特殊含义
正则表达式函数
Python 的 re 包有一些方法用来执行字符串查询:
re.match()
re.search()
re.findall()
每个方法都接受一个模式定义以及用来查询和匹配的字符串。
后面的内容中我们回逐个介绍这些方法的使用方法和区别。
re.match - 匹配开头
match(string[, pos[, endpos]])
先来看看 match() 方法,
这个方法会从符串的开头匹配模式
(也就是说字符串从第一个字符开始就需要能够匹配到模式,
字符串中间的某些字符能够匹配模式是不行的),
如果匹配到会返回 Match 对象,否则返回 None。
当需要提取的内容只有一个,或是只需要获取第一次成功匹配的内容时,可以使用Match()方法。
group() 返回被 RE 匹配的字符串
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
当使用Match()方法时,只要在某一位置匹配成功,就不再继续尝试匹配,并返回一个Match类型的对象。
使用 re.search - 匹配任意位置
search() 方法和 match() 方法很类似,
区别在于 search() 方法不仅仅只从开头匹配字符串,
它会在任意位置匹配字符串,因此修改上面例子使用 search() 方法可以匹配 'cat' 模式。
search() :会在匹配到第一个匹配项时退出.
re.findall - 匹配所有内容
当调用 findall() 进行匹配时会返回字符串中所有匹配的匹配对象
使用 fetchall() 方法时同样可以使用分组,最后会返回分组的列表。
相反,fetchall() 方法会返回一个元组列表,元组中的每个元素对应正则表达式中相应的分组
re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。我们通过下面的例子感受一下。
pattern = re.compile(r'\d+')
print re.split(pattern,'one1two2three3four4')
### 输出 ###
# ['one', 'two', 'three', 'four', '']
print (re.split('\s',an))
print (re.split('(口)',an))
re.finditer(pattern, string[, maxsplit])
finditer函数和findall函数的区别是,findall返回所有匹配的字符串,并存为一个列表,而finditer则并不直接返回这些字符串,而是返回一个迭代器。关于迭代器,解释起来有点复杂,还是看看例子把:简单的说吧,就是finditer返回了一个可调用的对象,使用 for i in finditer()的形式,可以一个一个的得到匹配返回的 Match对象。这在对每次返回的对象进行比较复杂的操作时比较有用。
>>> s=’111 222 333 444’
>>> for i in re.finditer(r’\d+’ , s ):
print i.group(),i.span() #打印每次得到的字符串和起始结束位置
#输出结果
111 (0, 3)
222 (4, 7)
333 (8, 11)
444 (12, 15)
re.sub(pattern, repl, string[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
import re
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print re.sub(pattern,r'\2 \1', s)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print re.sub(pattern,func, s)
### output ###
# say i, world hello!
# I Say, Hello World!
若匹配成功,match()/search()返回的是Match对象,finditer()返回的也是Match对象的迭代器,获取匹配结果需要调用Match对象的group()、groups或group(index)方法。
其他的正则函数:
re.finditer(pattern, string, flags=0)
返回与patten匹配的match object组成的迭代器。对string是从左到右扫描的,所以匹配的内容是按照该顺序来的。
贪婪和非贪婪模式
对于正则表达式,有三种匹配的模式:
贪婪(贪心) 如"*"字符 贪婪量词会首先匹配整个字符串,尝试匹配时,它会选定尽可能多的内容,如果 失败则回退一个字符,然后再次尝试回退的过程就叫做回溯,它会每次回退一个字符,直到找到匹配的内容或者没有字符可以回退。相比下面两种贪婪量词对资源的消耗是最大的,
懒惰(勉强) 如 "?" 懒惰量词使用另一种方式匹配,它从目标的起始位置开始尝试匹配,每次检查一个字符,并寻找它要匹配的内容,如此循环直到字符结尾处。
"*?" 重复任意次,但尽可能少重复
如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb"
"+?" 重复1次或更多次,但尽可能少重复
与上面一样,只是至少要重复1次
"??" 重复0次或1次,但尽可能少重复
如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"
"{n,m}?" 重复n到m次,但尽可能少重复
如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
"{n,}?" 重复n次以上,但尽可能少重复
如 "aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"
占有
如"+" 占有量词会覆盖事个目标字符串,然后尝试寻找匹配内容 ,但它只尝试一次,不会回溯,就好比先抓一把石头,然后从石头中挑出黄金
*、+和?限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
例如 ca*t 将匹配 ct(0 个字符 a),cat(1 个字符 a),caaat(3 个字符 a),等等。需要注意的是,由于受到 C 语言的 int 类型大小的内部限制,正则表达式引擎会限制字符 'a' 的重复个数不超过 20 亿个;不过,通常我们工作中也用不到那么大的数据。
正则表达式默认的重复规则是贪婪的,当你重复匹配一个 RE 时,匹配引擎会尝试尽可能多的去匹配。直到 RE 不匹配或者到了结尾,匹配引擎就会回退一个字符,然后再继续尝试匹配。
我们通过例子一步步的给大家讲解什么叫“贪婪”:先考虑一下表达式 a[bcd]*b,首先需要匹配字符 'a',然后是零个到多个 [bcd],最后以 'b' 结尾。那现在想象一下,这个 RE 匹配字符串 abcbd 会怎样?
| 步骤 | 匹配 | 说明 |
| 1 | a | 匹配 RE 的第一个字符 'a' |
| 2 | abcbd | 引擎在符合规则的情况下尽可能地匹配 [bcd]*,直到该字符串的结尾 |
| 3 | 失败 | 引擎尝试匹配 RE 最后一个字符 'b',但当前位置已经是字符串的结尾,所以失败告终 |
| 4 | abcb | 回退,所以 [bcd]* 匹配少一个字符 |
| 5 | 失败 | 再一次尝试匹配 RE 最后一个字符 'b',但字符串最后一个字符是 'd',所以失败告终 |
| 6 | abc | 再次回退,所以 [bcd]* 这次只匹配 'bc' |
| 7 | abcb | 再一次尝试匹配字符 'b',这一次字符串当前位置指向的字符正好是 'b',匹配成功 |
最终,RE 匹配的结果是 abcb。
其实 *、+ 和 ? 都可以使用 {m,n} 来代替。{0,} 跟 * 是一样的;{1,} 跟 + 是一样的;{0,1} 跟 ? 是一样的。不过还是鼓励大家记住并使用 *、+ 和 ?,因为这些字符更短并且更容易阅读。
编译标志(匹配模式)
编译标志让你可以修改正则表达式的工作方式。在 re 模块下,编译标志均有两个名字:完整名和简写,例如 IGNORECASE 简写是 I(如果你是 Perl 的粉丝,那么你有福了,因为这些简写跟 Perl 是一样的,例如 re.VERBOSE 的简写是 re.X)。另外,多个标志还可以同时使用(通过“|”),如:re.I | re.M 就是同时设置 I 和 M 标志。
下边列举一些支持的编译标志:
| 标志 | 含义 |
| ASCII, A | 使得转义符号如 \w,\b,\s 和 \d 只能匹配 ASCII 字符 |
| DOTALL, S | 使得 . 匹配任何符号,包括换行符 |
| IGNORECASE, I | 匹配的时候不区分大小写 |
| LOCALE, L | 支持当前的语言(区域)设置 |
| MULTILINE, M | 多行匹配,影响 ^ 和 $ |
| VERBOSE, X (for 'extended') | 启用详细的正则表达式 |
下面我们来详细讲解一下它们的含义:
A
ASCII
使得 \w,\W,\b,\B,\s 和 \S 只匹配 ASCII 字符,而不匹配完整的 Unicode 字符。这个标志仅对 Unicode 模式有意义,并忽略字节模式。
例:>>> re.search(r'\w','我爱China',re.A)
<_sre.SRE_Match object; span=(2, 3), match='C'>
S
DOTALL
使得 . 可以匹配任何字符,包括换行符。如果不使用这个标志,. 将匹配除了换行符的所有字符。
将使'.'特殊字符完全匹配任何字符,包括换行符,没有这个标志,'.'会匹配除换行符之外的任何。也就是说使用了该模式,正则式找到的将会是多行数据。而不使用该模式正则式找到的是单行数据。
例:>>> re.search(r'.','\n',re.S)
<_sre.SRE_Match object; span=(0, 1), match='\n'>
I
IGNORECASE
字符类和文本字符串在匹配的时候不区分大小写。举个例子,正则表达式 [A-Z] 也将会匹配对应的小写字母,像 FishC 可以匹配 FishC,fishc 或 FISHC 等。如果你不设置 LOCALE,则不会考虑语言(区域)设置这方面的大小写问题。
L
LOCALE
使得 \w,\W,\b 和 \B 依赖当前的语言(区域)环境,而不是 Unicode 数据库。
区域设置是 C 语言的一个功能,主要作用是消除不同语言之间的差异。例如你正在处理的是法文文本,你想使用 \w+ 来匹配单词,但是 \w 只是匹配 [A-Za-z] 中的单词,并不会匹配 'é' 或 'ç'。如果你的系统正确的设置了法语区域环境,那么 C 语言的函数就会告诉程序 'é' 或 'ç' 也应该被认为是一个字符。当编译正则表达式的时候设置了 LOCALE 的标志,\w+ 就可以识别法文了,但速度多少会受到影响。该功能已经取消了。
M
MULTILINE
(^ 和 $ 我们还没有提到,别着急,后边我们有细讲...)
通常 ^ 只匹配字符串的开头,而 $ 则匹配字符串的结尾。当这个标志被设置的时候,^ 不仅匹配字符串的开头,还匹配每一行的行首;& 不仅匹配字符串的结尾,还匹配每一行的行尾。
指定时,模式字符'^'匹配字符串的开头和每行的开始处(紧跟在每个换行符后面)以及字符'$'匹配字符串的末尾和每行的末尾(紧接在每个换行符的前面)。默认情况下,'^'仅在字符串的开头匹配,而'$'仅在字符串的末尾和紧接换行符之前(如果有的话)匹配字符串的结尾。
例:>>> re.search(r'^T','I love China\nT love Chian\nU love China',re.M)
<_sre.SRE_Match object; span=(13, 14), match='T'>
X
VERBOSE
这个标志使你的正则表达式可以写得更好看和更有条理,因为使用了这个标志,空格会被忽略(除了出现在字符类中和使用反斜杠转义的空格);这个标志同时允许你在正则表达式字符串中使用注释,# 符号后边的内容是注释,不会递交给匹配引擎(除了出现在字符类中和使用反斜杠转义的 #)。
反向应用
表达式在匹配时,表达式引擎会将小括号 "( )" 包含的表达式所匹配到的字符串记录下来。在获取匹配结果的时候,小括号包含的表达式所匹配到的字符串可以单独获取。这一点,在前面的举例中,已经多次展示了。在实际应用场合中,当用某种边界来查找,而所要获取的内容又不包含边界时,必须使用小括号来指定所要的范围。比如前面的 "<td>(.*?)</td>"。
其实,"小括号包含的表达式所匹配到的字符串" 不仅是在匹配结束后才可以使用,在匹配过程中也可以使用。表达式后边的部分,可以引用前面 "括号内的子匹配已经匹配到的字符串"。引用方法是"/" 加上一个数字。"/1" 引用第 1 对括号内匹配到的字符串,"/2" 引用第 2 对括号内匹配到的字符串……以此类推,如果一对括号内包含另一对括号,则外层的括号先排序号。换句话说,哪一对的左括号"(" 在前,那这一对就先排序号。
举例如下:
举例 1:
表达式 " ('|")(.*?)(/1) " 在匹配 " 'Hello', "World" " 时,匹配结果是:成功;匹配到的内容是:" 'Hello' "。再次匹配下一个时,可以匹配到 " "World" "。注意:(/1)和第一个括号比配的字符必须相同。
举例 2:
表达式 " (/w)/1{4,} " 在匹配 "aa bbbb abcdefg ccccc111121111 999999999" 时,匹配结果是:成功;匹配到的内容是"ccccc"。再次匹配下一个时,将得到 999999999。这个表达式要求"/w" 范围的字符至少重复 5 次,注意与 "/w{5,}" 之间的区别。注意:(/1)和第一个括号比配的字符必须相同。
举例 3:
表达式 "<(/w+)/s*(/w+(=('|").*?/4)?/s*)*>.*?<//1>" 在匹配"<td id='td1' style="bgcolor:white"></td>" 时,匹配结果是成功。
如果"<td>" 与 "</td>" 不配对,则会匹配失败;如果改成其他配对,也可以匹配成功。
特点在于,在正则式捕捉到分组数据的时候,将捕捉的数据当成变量灵活运行。从例3的应用中可以得到很好的说明。
如有错漏,敬请指正!rwangnqian@126.com

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









