



VOT相关背景不再赘述。
与之前方法的对比图:
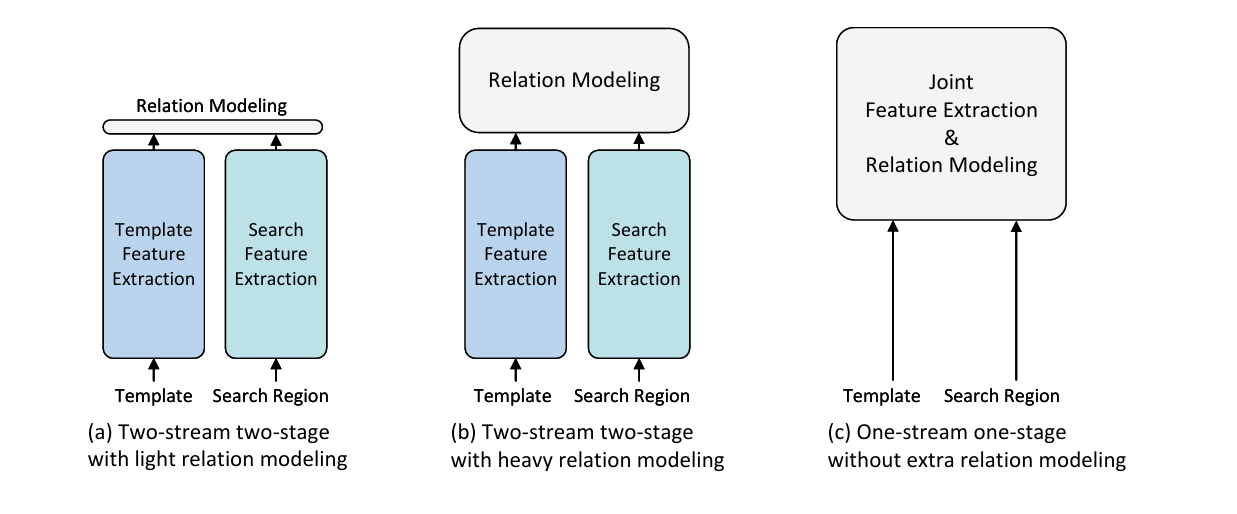
先前方法先分别提取模板区域和搜索区域特征(CNN,transformer)再做关系建模。
本文提出同时进行特征提取和关系建模,确保特征的有效利用。
提出了单流(One-Stream)结构,OSTrack可以说是目前目标跟踪方法中90%以上的基线方法。
结构图: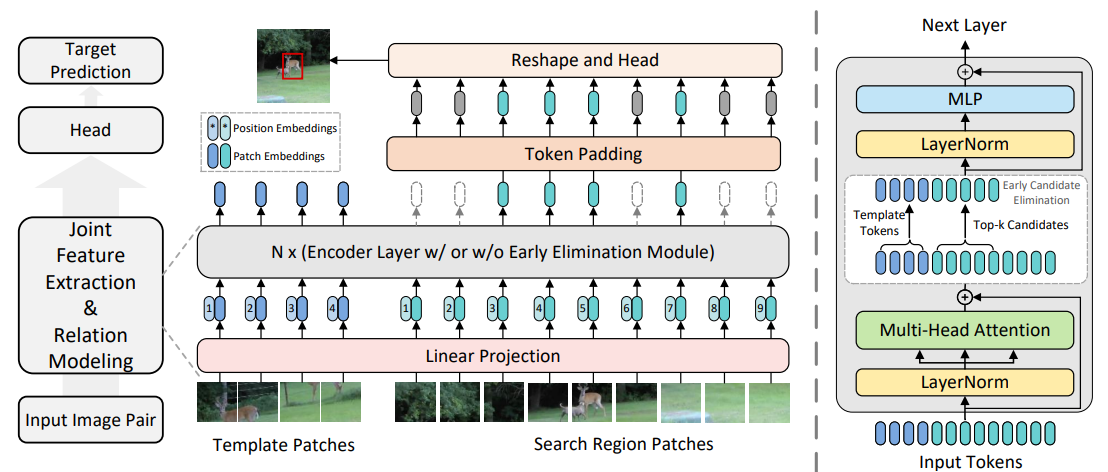
从下往上看,输入包括模板区域和搜索区域的patch,过线性层打成Token后,加位置编码。
之后过若干个右图的Vision Transformer块(使用了MAE-ViT的预训练模型,故保证此处结构与ViT一致)。
最后将搜索区域的Token还原成矩形并过预测头得到结果。
candidate elimination (CE) module:在ViT中的某几层加入,通过比对模板Token和搜索区域Token的相似度来消除(置0)一部分相似度低的搜索区域Token。

w/表示加入CE module,在提升速度的同时提高了数据集上的性能(作者解释为通过消除不相似Token,消除了一些潜在干扰物的影响)。
代码部分:
模型:
lib/model/ostrack/ostrack.py
def build_ostrack(cfg, training=True):
current_dir = os.path.dirname(os.path.abspath(__file__)) # This is your Project Root
pretrained_path = os.path.join(current_dir, '../../../pretrained_models')
if cfg.MODEL.PRETRAIN_FILE and ('OSTrack' not in cfg.MODEL.PRETRAIN_FILE) and training:
pretrained = os.path.join(pretrained_path, cfg.MODEL.PRETRAIN_FILE)
else:
pretrained = ''
if cfg.MODEL.BACKBONE.TYPE == 'vit_base_patch16_224':
backbone = vit_base_patch16_224(pretrained, drop_path_rate=cfg.TRAIN.DROP_PATH_RATE)
hidden_dim = backbone.embed_dim
patch_start_index = 1
elif cfg.MODEL.BACKBONE.TYPE == 'vit_base_patch16_224_ce':
backbone = vit_base_patch16_224_ce(pretrained, drop_path_rate=cfg.TRAIN.DROP_PATH_RATE,
ce_loc=cfg.MODEL.BACKBONE.CE_LOC,
ce_keep_ratio=cfg.MODEL.BACKBONE.CE_KEEP_RATIO,
)
hidden_dim = backbone.embed_dim
patch_start_index = 1
elif cfg.MODEL.BACKBONE.TYPE == 'vit_large_patch16_224_ce':
backbone = vit_large_patch16_224_ce(pretrained, drop_path_rate=cfg.TRAIN.DROP_PATH_RATE,
ce_loc=cfg.MODEL.BACKBONE.CE_LOC,
ce_keep_ratio=cfg.MODEL.BACKBONE.CE_KEEP_RATIO,
)
hidden_dim = backbone.embed_dim
patch_start_index = 1
else:
raise NotImplementedError
backbone.finetune_track(cfg=cfg, patch_start_index=patch_start_index)
box_head = build_box_head(cfg, hidden_dim)
model = OSTrack(
backbone,
box_head,
aux_loss=False,
head_type=cfg.MODEL.HEAD.TYPE,
)
if 'OSTrack' in cfg.MODEL.PRETRAIN_FILE and training:
checkpoint = torch.load(cfg.MODEL.PRETRAIN_FILE, map_location="cpu")
missing_keys, unexpected_keys = model.load_state_dict(checkpoint["net"], strict=False)
print('Load pretrained model from: ' + cfg.MODEL.PRETRAIN_FILE)
return model
上述代码建立了ostrack的模型,重点关注: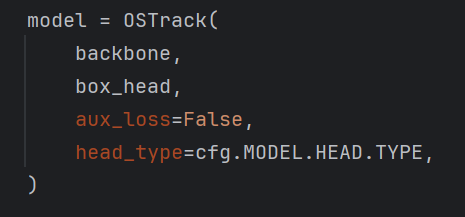
这就是ostrack模型的构成部分,包括骨干网络和预测头,十分简洁。
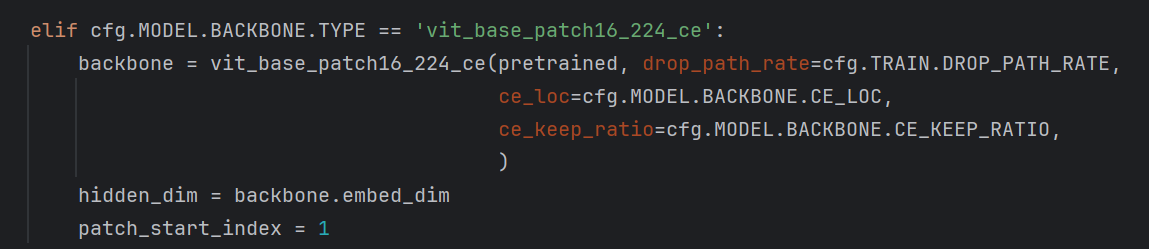
backbone的实例化,即带ce模块的vit。

预测头实例化,具体实现参考目标检测中的CenterNet,预测单个目标时,这种带偏移量的anchor-free头效果很好,非常good的想法。
def forward(self, template: torch.Tensor,
search: torch.Tensor,
ce_template_mask=None,
ce_keep_rate=None,
return_last_attn=False,
):
x, aux_dict = self.backbone(z=template, x=search,
ce_template_mask=ce_template_mask,
ce_keep_rate=ce_keep_rate,
return_last_attn=return_last_attn, )
# Forward head
feat_last = x
if isinstance(x, list):
feat_last = x[-1]
out = self.forward_head(feat_last, None)
out.update(aux_dict)
out['backbone_feat'] = x
return out模型的前向传播部分,输入模板和搜索区域Token,输出为过预测头后的特征图。
lib/model/ostrack/vit_ce.py
def forward_features(self, z, x, mask_z=None, mask_x=None,
ce_template_mask=None, ce_keep_rate=None,
return_last_attn=False
):
B, H, W = x.shape[0], x.shape[2], x.shape[3]
x = self.patch_embed(x)
z = self.patch_embed(z)
# attention mask handling
# B, H, W
if mask_z is not None and mask_x is not None:
mask_z = F.interpolate(mask_z[None].float(), scale_factor=1. / self.patch_size).to(torch.bool)[0]
mask_z = mask_z.flatten(1).unsqueeze(-1)
mask_x = F.interpolate(mask_x[None].float(), scale_factor=1. / self.patch_size).to(torch.bool)[0]
mask_x = mask_x.flatten(1).unsqueeze(-1)
mask_x = combine_tokens(mask_z, mask_x, mode=self.cat_mode)
mask_x = mask_x.squeeze(-1)
if self.add_cls_token:
cls_tokens = self.cls_token.expand(B, -1, -1)
cls_tokens = cls_tokens + self.cls_pos_embed
z += self.pos_embed_z
x += self.pos_embed_x
if self.add_sep_seg:
x += self.search_segment_pos_embed
z += self.template_segment_pos_embed
x = combine_tokens(z, x, mode=self.cat_mode)
if self.add_cls_token:
x = torch.cat([cls_tokens, x], dim=1)
x = self.pos_drop(x)
lens_z = self.pos_embed_z.shape[1]
lens_x = self.pos_embed_x.shape[1]
global_index_t = torch.linspace(0, lens_z - 1, lens_z).to(x.device)
global_index_t = global_index_t.repeat(B, 1)
global_index_s = torch.linspace(0, lens_x - 1, lens_x).to(x.device)
global_index_s = global_index_s.repeat(B, 1)
removed_indexes_s = []
for i, blk in enumerate(self.blocks):
x, global_index_t, global_index_s, removed_index_s, attn = \
blk(x, global_index_t, global_index_s, mask_x, ce_template_mask, ce_keep_rate)
if self.ce_loc is not None and i in self.ce_loc:
removed_indexes_s.append(removed_index_s)
x = self.norm(x)
lens_x_new = global_index_s.shape[1]
lens_z_new = global_index_t.shape[1]
z = x[:, :lens_z_new]
x = x[:, lens_z_new:]
if removed_indexes_s and removed_indexes_s[0] is not None:
removed_indexes_cat = torch.cat(removed_indexes_s, dim=1)
pruned_lens_x = lens_x - lens_x_new
pad_x = torch.zeros([B, pruned_lens_x, x.shape[2]], device=x.device)
x = torch.cat([x, pad_x], dim=1)
index_all = torch.cat([global_index_s, removed_indexes_cat], dim=1)
# recover original token order
C = x.shape[-1]
# x = x.gather(1, index_all.unsqueeze(-1).expand(B, -1, C).argsort(1))
x = torch.zeros_like(x).scatter_(dim=1, index=index_all.unsqueeze(-1).expand(B, -1, C).to(torch.int64), src=x)
x = recover_tokens(x, lens_z_new, lens_x, mode=self.cat_mode)
# re-concatenate with the template, which may be further used by other modules
x = torch.cat([z, x], dim=1)
aux_dict = {
"attn": attn,
"removed_indexes_s": removed_indexes_s, # used for visualization
}
return x, aux_dict以上为backbone部分(带ce模块的ViT)的前向传播代码。
梳理流程:
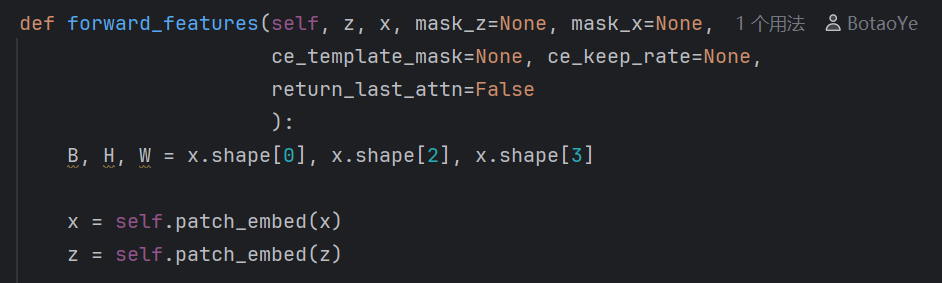
z,x即为输入的搜索图像和模板,其余参数均为ce块所需的,暂不提及,先进行patch嵌入。
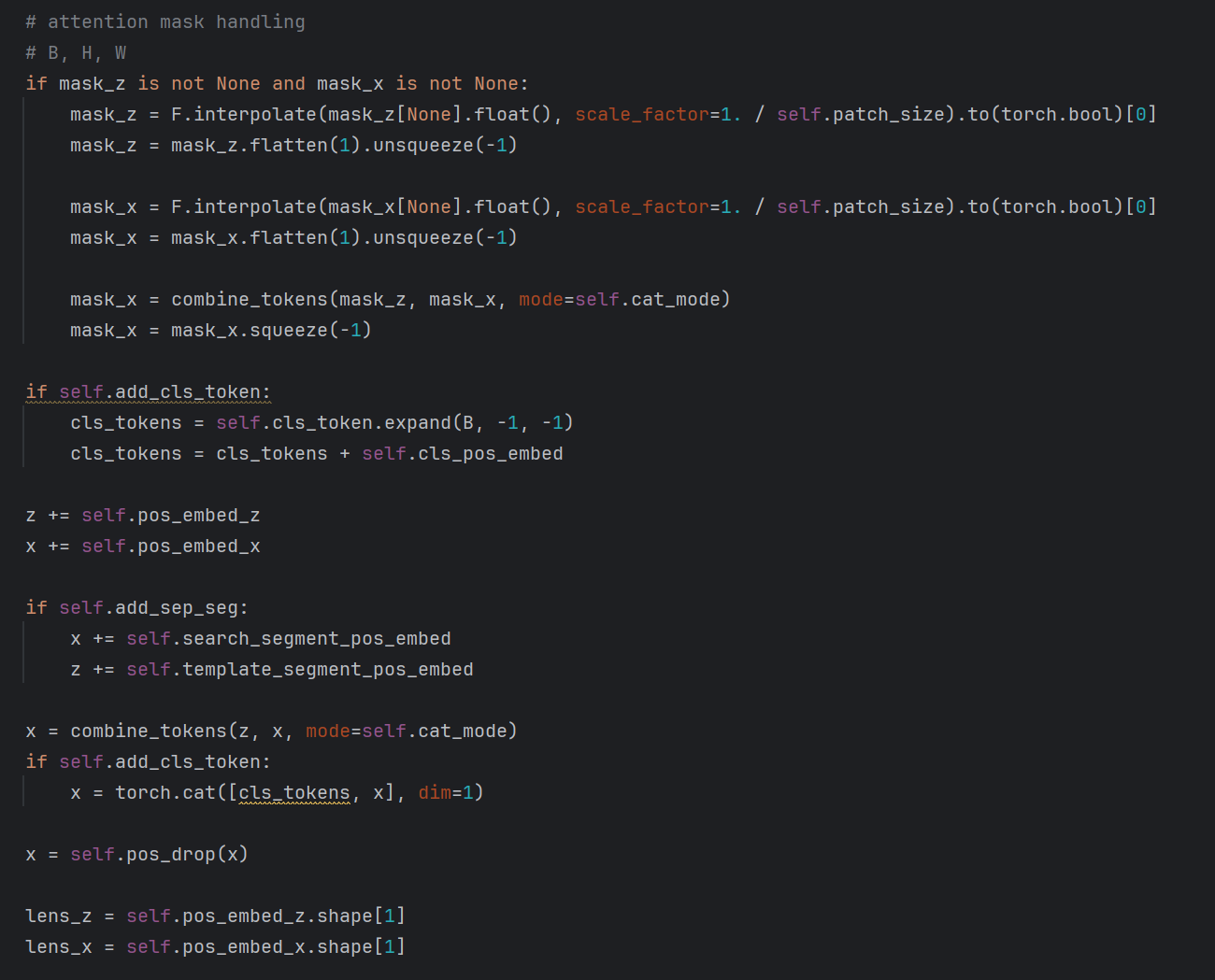
所有关于掩码的操作均用作CE模块,暂不提及。self.add_cls_token在模型设置中为False,该段代码即加入了位置编码,并直接将搜索token和模板token进行拼接。
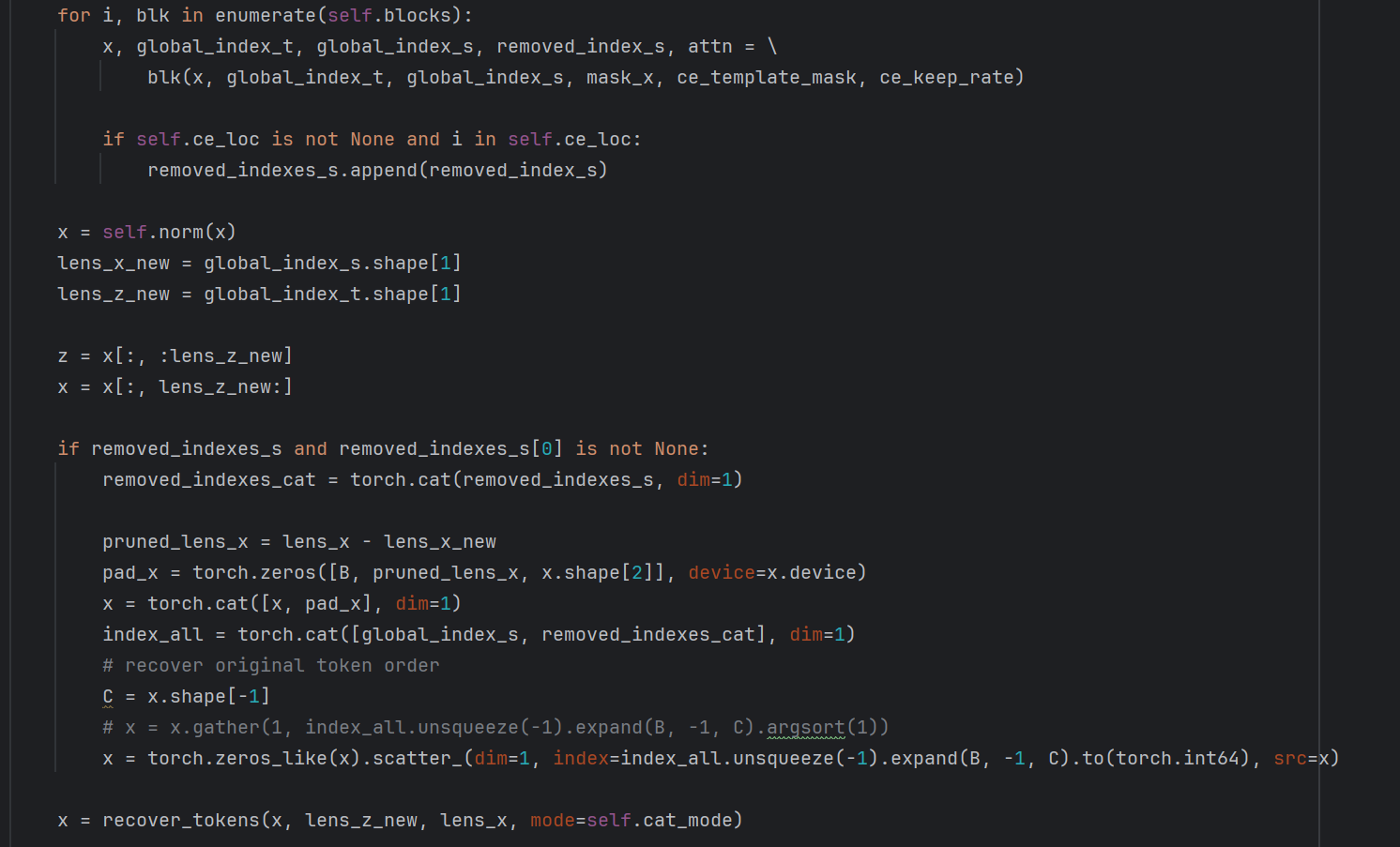
将拼接后的Token逐层过attention块。在每一个块中,计算出来需要消除的搜索区域对应token的索引(removed_index_s),但是,只在特定块进行候选消除(self.ce_loc,原文中为3,6,9层各30%),最后根据消除的token的索引还原token顺序(被消除的块只是置0,需要参与计算但是不贡献计算量)。
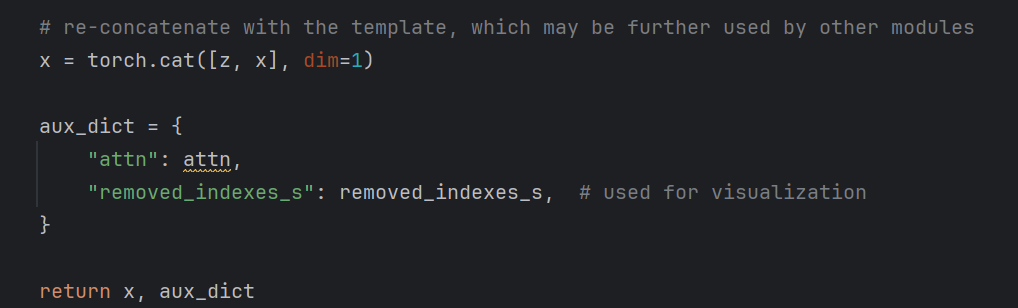
最后拼接token,维度不变。
lib/model/layers/head.py
预测头部分不多介绍,参考CenterNet,三个分支的全卷积头,注意需要先将token还原成矩形。
推理:
待更新。。。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











