



 本文探讨了模型优化中的误差来源,包括偏差(Bias)和方差(Variance),并解释了过拟合和欠拟合的概念。针对偏差问题,建议增加模型复杂度,如添加特征;为降低方差,可以引入更多数据或正则化。梯度下降法作为参数优化的方法,通过迭代最小化损失函数来更新模型参数。文中提到了学习率的重要性以及Adagrad和随机梯度下降等优化策略。此外,还讨论了梯度下降的局限性,如陷入局部最优和平滑区域。
本文探讨了模型优化中的误差来源,包括偏差(Bias)和方差(Variance),并解释了过拟合和欠拟合的概念。针对偏差问题,建议增加模型复杂度,如添加特征;为降低方差,可以引入更多数据或正则化。梯度下降法作为参数优化的方法,通过迭代最小化损失函数来更新模型参数。文中提到了学习率的重要性以及Adagrad和随机梯度下降等优化策略。此外,还讨论了梯度下降的局限性,如陷入局部最优和平滑区域。
回归误差
Errors与Bias
- 假设f^\hat ff^是最佳的model(function),我们从training data中所找出的f∗f^{*}f∗实际上是f^\hat ff^的估测值(estimator)。f∗f^{*}f∗与f^\hat ff^间的差距可以类比与靶心和落靶位置之间的距离。这个差距来源于Bias(瞄准的位置和f^\hat ff^间的差距)和Variance(落点和瞄准的位置)。
(from李宏毅老师课程中的slides)
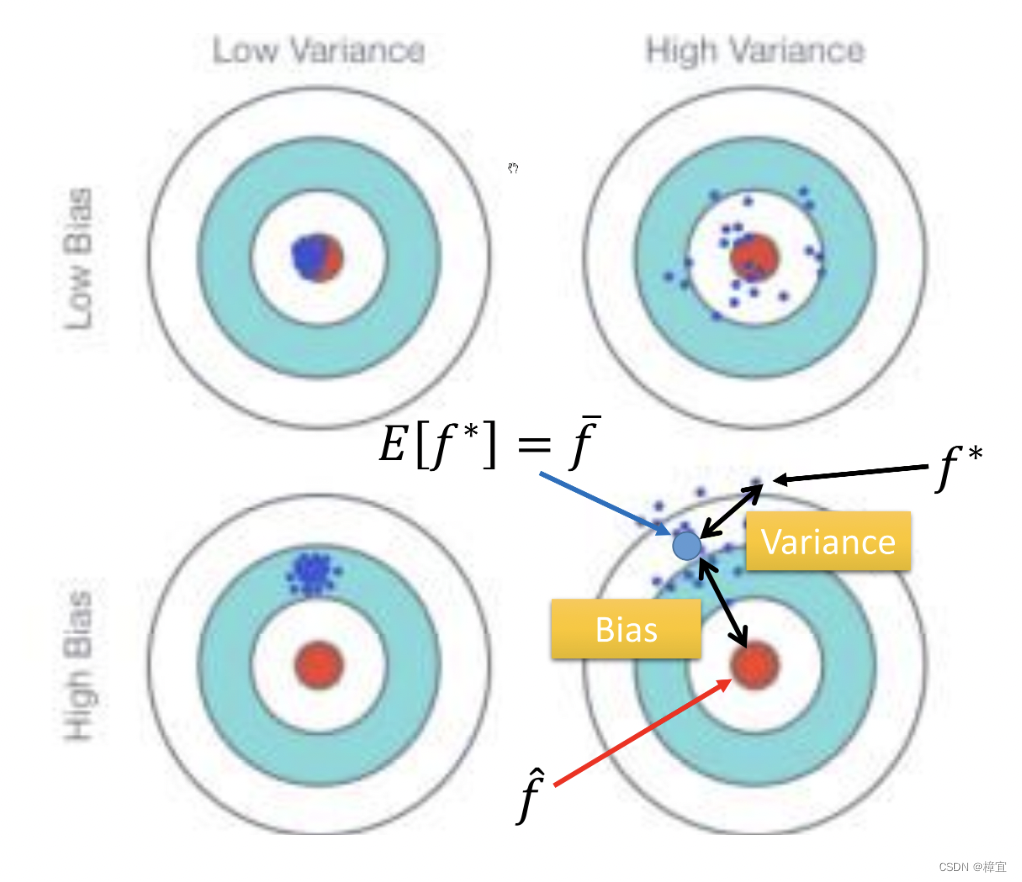
- 复杂的模型:small bias and large variance overfitting
- 简单的模型:large bias and small variance under fitting
- 想要improve model的时候要诊断是 bias还是variance大。对于bias来说,redesign your model,比如添加更多的features或者改变次幂项做更复杂的模型。对于large variance,更多的data(一般不具有实际性,但是或许可以根据经验或者知识自己造数据)或者正则化(Regularization)
- 在bias和variance之间做出trade-off。
Training set选择出的error最小的model,在Testing set上的效果不一定是最好的。
Gradient Descent
梯度下降法的核心是寻找参数使得L(Loss function)到最小值。
θ∗=argminθL(θ)\theta ^*=\arg \min \limits_{\theta} L(\theta)θ∗=argθminL(θ) 其中θ\thetaθ是一族参数(parameters)。
对θ\thetaθ进行迭代计算。如下:
∇L(θ)=[∂L(θ1)∂L(θ1∂L(θ2)∂L(θ2]\nabla L(\theta)=\begin{bmatrix} \frac{\partial L(\theta_1)}{\partial L(\theta_1} \\ \frac{\partial L(\theta_2)}{\partial L(\theta_2} \end{bmatrix}∇L(θ)=[∂L(θ1∂L(θ1)∂L(θ2∂L(θ2)]
迭代式:
θ1=θ0−η∇L(θ0) \theta^1
= \theta^0 -\eta \nabla L(\theta^0)θ1=θ0−η∇L(θ0)
η\etaη被称为学习率(Learning rate)
调整学习率至关重要
- 一些相关算法的出现的出现
简单的思想,例如随着次数的增加,通过一些因子来减少学习率,学习率依照不同情形情况设置,没有通用的值 - Adagrad 算法 (每个参数的学习率都除以之前微分的均方根)
wt+1←wt−η∑i=0t(gi)2gtw^{t+1}\leftarrow w^{t}-\frac{\eta}{\sum_{i=0}^{t}(g^{i})^2}g^twt+1←wt−∑i=0t(gi)2ηgt
单参数函数(想一下二次函数求极值的例子)中,梯度越大,就跟最低点的距离越远。但是在多参数下,这个结论不一定成立。与最低点间的距离(即梯度下降移动的步伐)不止和一次微分成正比,还和二次微分成反比。于是应:|一次微分|二次微分\frac{|一次微分|}{二次微分}二次微分|一次微分|使用∑i=0t(gi)2\sum_{i=0}^{t}(g^{i})^2∑i=0t(gi)2来近似二次微分(省时省力)。 - 随机梯度下降法(Stochastic Gradient Descent)
喂一组数据就更新一次梯度,不需要像梯度下降法每次更新梯度使用所有的数据。
-特征缩放(make different features have the same scaling)
使多个参数在更新梯度时学习率尽量一致。
xir′←xir−miσi{x_{i}^{r}}'\leftarrow \frac{x_i^r-m_{i}}{\sigma_{i}}xir′←σixir−mi 使每一组特征的平均值为0,方差为1(标准化)。
梯度下降的数学理论
每次更新参数,不一定使得损失函数更小。
泰勒展开的前提即h(x)在x=x0x=x_0x=x0点的某个领域内有无限阶导数(即无限可微分,infinite differentiable),在x0x_0x0的邻域内有
h(x)=∑k=0∞h(x0k)k!(x−x0)k=h(x0)+h′(x0)(x−x0)+h′′(x0)2!(x−x0)2\begin{aligned}
h(x) &= \sum_{k=0}^{\infty}\frac{h(x_{0}^k)}{k!}(x-x_0)^k\\
&=h(x_{0})+h'(x_{0})(x-x_{0})+\frac{h''(x_{0})}{2!}(x-x_{0})^2
\end{aligned}h(x)=k=0∑∞k!h(x0k)(x−x0)k=h(x0)+h′(x0)(x−x0)+2!h′′(x0)(x−x0)2
当xxx接近x0x_{0}x0时,有$h(x)≈h(x0)+h′(x0)(x−x0)h(x) \approx h(x_{0})+h'(x_{0})(x-x_{0})h(x)≈h(x0)+h′(x0)(x−x0)
梯度下降的限制
- 容易陷入局部极值
- 微分是0,但不是极值
- 还有可能微分值趋近于0或者小于某一个数(例如10−610^{-6}10−6)比较平缓,但并不是极值点

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









