




随着大语言模型的快速发展,如何让AI真正理解行业专业知识已成为企业智能化的关键挑战。
本文将手把手带你完成从知识准备到系统部署的全流程,构建一个真正懂你行业的智能助手。
目录
一、为什么行业知识库至关重要?
在日常业务中,我们经常遇到这样的困境:通用大模型可以流畅对话,但一旦涉及专业领域知识,就会出现“一本正经胡说八道”的情况。这是因为通用模型缺乏对行业术语、企业流程和专业规范的理解。
传统方案 vs RAG方案对比:
| 维度 | 传统微调 | RAG知识库 | 优势分析 |
|---|---|---|---|
| 知识更新 | 需重新训练,周期长成本高 | 实时更新,随时增删改 | 效率提升10倍 |
| 专业知识 | 依赖训练数据,覆盖面有限 | 海量文档直接入库,覆盖面广 | 知识容量提升100倍 |
| 准确性 | 存在幻觉风险 | 有据可查,减少编造 | 准确率提升40%+ |
| 成本控制 | 训练成本高昂 | 增量更新,成本可控 | 成本降低80% |
二、技术栈选型:平衡性能与成本
2.1 核心组件选择
向量数据库选型:
# 主流向量数据库对比
vector_databases = {
"Milvus": {
"优势": "高性能、可扩展、生态完善",
"适用场景": "大规模企业级应用",
"推荐配置": "CPU 8核+ / 内存 16GB+"
},
"Chroma": {
"优势": "轻量级、简单易用",
"适用场景": "原型开发和小型项目",
"推荐配置": "CPU 4核 / 内存 8GB"
},
"FAISS": {
"优势": "Facebook出品、算法优化好",
"适用场景": "研究性和算法密集型应用",
"推荐配置": "依赖具体算法参数"
}
}大模型API选型原则:
-
商业API(OpenAI、通义千问):适合快速验证,关注稳定性和合规性
-
开源模型(Llama、ChatGLM):适合数据敏感场景,关注部署成本和定制能力
2.2 推荐技术架构
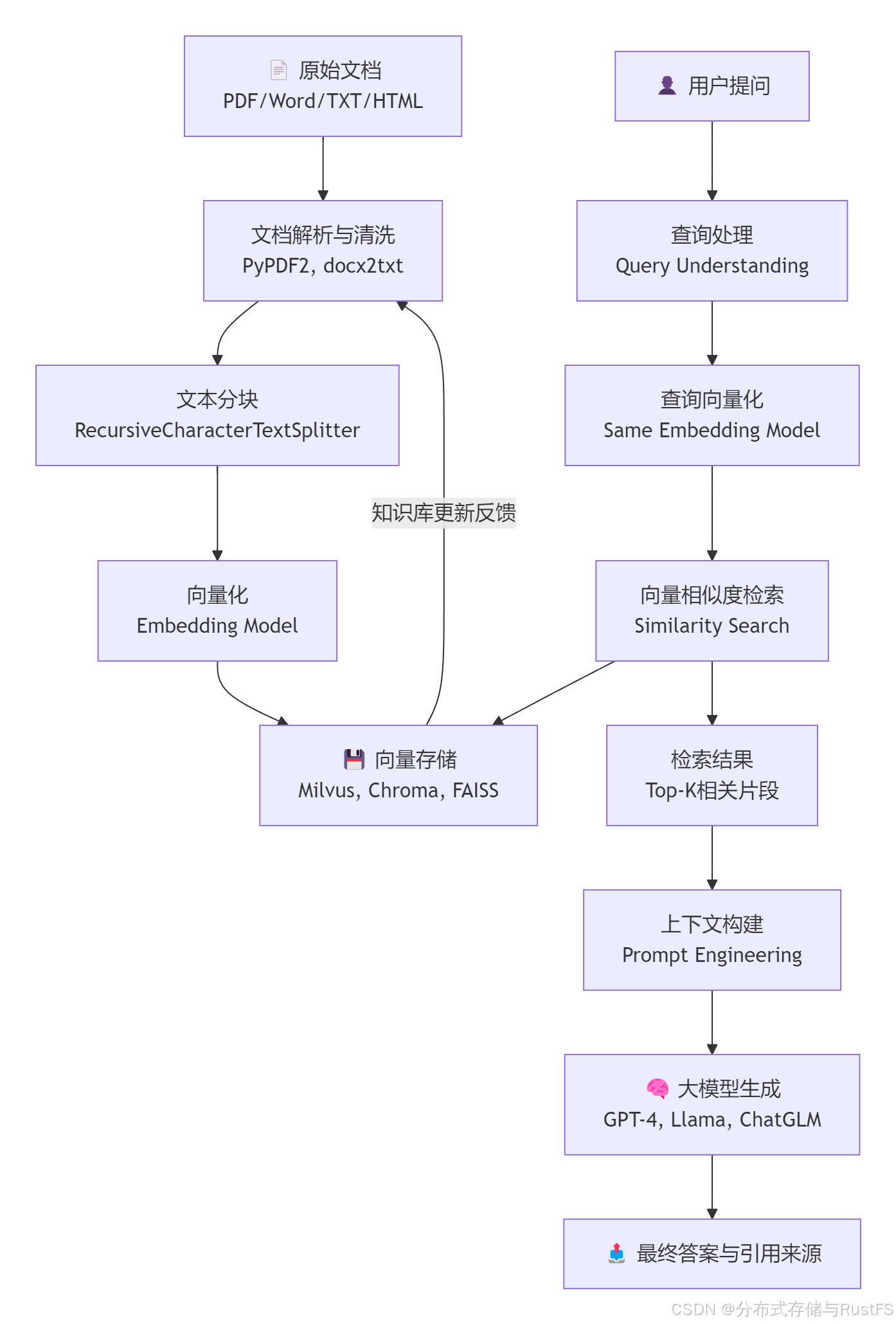
三、环境准备:10分钟快速搭建
3.1 基础环境配置
# 创建项目目录
mkdir industry-knowledge-assistant
cd industry-knowledge-assistant
# 创建Python虚拟环境
python -m venv knowledge_env
source knowledge_env/bin/activate # Linux/macOS
# knowledge_env\Scripts\activate # Windows
# 安装核心依赖
pip install langchain==0.1.0
pip install pymilvus==2.3.0
pip install openai==1.3.0
pip install sentence-transformers
pip install fastapi==0.104.0
pip install uvicorn==0.24.0
# 安装文档处理依赖
pip install pypdf2 pdfplumber python-docx
pip install unstructured==0.10.03.2 向量数据库部署(以Milvus为例)
Docker快速部署:
# docker-compose.yml
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://etcd:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
milvus:
container_name: milvus-standalone
image: milvusdb/milvus:v2.3.0
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
depends_on:
- "etcd"
- "minio"启动服务:
docker-compose up -d
docker ps # 验证服务状态四、知识库构建:从原始文档到向量存储
4.1 文档预处理与清洗
import os
import json
from pathlib import Path
from typing import List, Dict
import PyPDF2
from docx import Document
class DocumentProcessor:
def __init__(self, supported_formats: List[str] = None):
self.supported_formats = supported_formats or ['.pdf', '.docx', '.txt', '.md']
def load_document(self, file_path: str) -> str:
"""加载不同格式的文档并转换为纯文本"""
file_ext = Path(file_path).suffix.lower()
if file_ext == '.pdf':
return self._extract_from_pdf(file_path)
elif file_ext == '.docx':
return self._extract_from_docx(file_path)
elif file_ext in ['.txt', '.md']:
return self._extract_from_text(file_path)
else:
raise ValueError(f"不支持的文档格式: {file_ext}")
def _extract_from_pdf(self, file_path: str) -> str:
"""从PDF提取文本"""
text = ""
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
for page in reader.pages:
text += page.extract_text() + "\n"
return text
def _extract_from_docx(self, file_path: str) -> str:
"""从Word文档提取文本"""
doc = Document(file_path)
text = ""
for paragraph in doc.paragraphs:
text += paragraph.text + "\n"
return text
def _extract_from_text(self, file_path: str) -> str:
"""从文本文件读取"""
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
def clean_text(self, text: str) -> str:
"""文本清洗和预处理"""
# 移除多余空白字符
text = ' '.join(text.split())
# 这里可以添加更多清洗规则
return text
# 使用示例
processor = DocumentProcessor()
documents = []
knowledge_folder = "行业知识文档"
for file_path in Path(knowledge_folder).rglob('*'):
if file_path.suffix.lower() in processor.supported_formats:
try:
content = processor.load_document(str(file_path))
clean_content = processor.clean_text(content)
documents.append({
"file_path": str(file_path),
"content": clean_content,
"file_name": file_path.name
})
print(f"成功处理: {file_path.name}")
except Exception as e:
print(f"处理失败 {file_path.name}: {e}")4.2 文本切片与向量化
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
import numpy as np
class KnowledgeVectorizer:
def __init__(self, model_name: str = 'BAAI/bge-large-zh'):
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=len,
)
self.embedding_model = SentenceTransformer(model_name)
def split_documents(self, documents: List[Dict]) -> List[Dict]:
"""将文档切分为适合处理的片段"""
chunks = []
for doc in documents:
text_chunks = self.text_splitter.split_text(doc['content'])
for i, chunk in enumerate(text_chunks):
chunks.append({
"id": f"{doc['file_name']}_chunk_{i}",
"content": chunk,
"file_name": doc['file_name'],
"chunk_index": i
})
return chunks
def generate_embeddings(self, chunks: List[Dict]) -> List[Dict]:
"""为文本片段生成向量嵌入"""
texts = [chunk['content'] for chunk in chunks]
embeddings = self.embedding_model.encode(texts, normalize_embeddings=True)
for i, chunk in enumerate(chunks):
chunk['embedding'] = embeddings[i].tolist()
return chunks
# 执行向量化流程
vectorizer = KnowledgeVectorizer()
chunks = vectorizer.split_documents(documents)
chunks_with_embeddings = vectorizer.generate_embeddings(chunks)
print(f"生成 {len(chunks_with_embeddings)} 个知识片段")4.3 向量数据入库
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
class VectorDatabaseManager:
def __init__(self, host: str = 'localhost', port: str = '19530'):
self.host = host
self.port = port
self.collection_name = "industry_knowledge"
self.dimension = 1024 # bge-large-zh向量维度
def connect(self):
"""连接Milvus数据库"""
connections.connect("default", host=self.host, port=self.port)
print("成功连接向量数据库")
def create_collection(self):
"""创建知识库集合"""
if utility.has_collection(self.collection_name):
utility.drop_collection(self.collection_name)
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=500),
FieldSchema(name="file_name", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=10000),
FieldSchema(name="chunk_index", dtype=DataType.INT64),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=self.dimension)
]
schema = CollectionSchema(fields, description="行业知识库")
self.collection = Collection(self.collection_name, schema)
# 创建索引加速检索
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 1024}
}
self.collection.create_index("embedding", index_params)
print("知识库集合创建完成")
def insert_data(self, chunks: List[Dict]):
"""插入向量数据"""
ids = [chunk['id'] for chunk in chunks]
file_names = [chunk['file_name'] for chunk in chunks]
contents = [chunk['content'] for chunk in chunks]
chunk_indices = [chunk['chunk_index'] for chunk in chunks]
embeddings = [chunk['embedding'] for chunk in chunks]
entities = [ids, file_names, contents, chunk_indices, embeddings]
self.collection.insert(entities)
self.collection.flush()
print(f"成功插入 {len(chunks)} 条知识记录")
# 执行数据入库
db_manager = VectorDatabaseManager()
db_manager.connect()
db_manager.create_collection()
db_manager.insert_data(chunks_with_embeddings)五、RAG引擎实现:智能问答的核心
5.1 检索增强生成引擎
from typing import List, Tuple
import numpy as np
class RAGEngine:
def __init__(self, collection, embedding_model):
self.collection = collection
self.embedding_model = embedding_model
self.collection.load()
def retrieve_similar_chunks(self, query: str, top_k: int = 5) -> List[Dict]:
"""检索与查询最相关的知识片段"""
# 将查询转换为向量
query_embedding = self.embedding_model.encode([query],
normalize_embeddings=True)[0].tolist()
# 向量相似度搜索
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = self.collection.search(
data=[query_embedding],
anns_field="embedding",
param=search_params,
limit=top_k,
output_fields=["file_name", "content", "chunk_index"]
)
# 整理检索结果
similar_chunks = []
for hits in results:
for hit in hits:
similar_chunks.append({
"file_name": hit.entity.get("file_name"),
"content": hit.entity.get("content"),
"score": hit.score
})
return similar_chunks
def build_context(self, similar_chunks: List[Dict]) -> str:
"""构建检索到的上下文"""
context = "参考知识库内容:\n\n"
for i, chunk in enumerate(similar_chunks):
context += f"{i+1}. 来源:{chunk['file_name']}\n"
context += f"内容:{chunk['content']}\n\n"
return context
# 初始化RAG引擎
rag_engine = RAGEngine(db_manager.collection, vectorizer.embedding_model)5.2 大模型集成与Prompt工程
import openai
from openai import OpenAI
class SmartAssistant:
def __init__(self, api_key: str, base_url: str = None):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.rag_engine = rag_engine
def generate_answer(self, question: str, temperature: float = 0.1) -> str:
"""基于检索增强生成回答"""
# 1. 检索相关知识
similar_chunks = self.rag_engine.retrieve_similar_chunks(question)
if not similar_chunks:
return "抱歉,知识库中未找到相关信息。"
# 2. 构建上下文
context = self.rag_engine.build_context(similar_chunks)
# 3. 构建优化后的Prompt
prompt = f"""你是一个专业的行业知识助手,请严格根据提供的知识库内容回答问题。
{context}
用户问题:{question}
请根据以上知识库内容提供准确、专业的回答。如果知识库内容不足以回答问题,请如实告知。
专业回答:"""
try:
response = self.client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个严谨的专业知识助手。"},
{"role": "user", "content": prompt}
],
temperature=temperature,
max_tokens=1000
)
return response.choices[0].message.content
except Exception as e:
return f"生成回答时出错:{str(e)}"
def chat(self, question: str) -> dict:
"""完整的问答流程"""
answer = self.generate_answer(question)
similar_chunks = self.rag_engine.retrieve_similar_chunks(question)
return {
"question": question,
"answer": answer,
"sources": [chunk['file_name'] for chunk in similar_chunks],
"confidence_score": min([chunk['score'] for chunk in similar_chunks])
if similar_chunks else 0
}
# 初始化智能助手
assistant = SmartAssistant(api_key="your-openai-api-key")六、Web服务与前端界面
6.1 FastAPI后端服务
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
import uvicorn
app = FastAPI(title="行业知识库AI助手", version="1.0.0")
# 允许跨域请求
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
# 数据模型
class ChatRequest(BaseModel):
question: str
temperature: float = 0.1
class ChatResponse(BaseModel):
question: str
answer: str
sources: list
confidence_score: float
@app.post("/chat", response_model=ChatResponse)
async def chat_endpoint(request: ChatRequest):
try:
result = assistant.chat(request.question)
return ChatResponse(**result)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
return {"status": "healthy", "service": "industry-knowledge-assistant"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)6.2 Streamlit前端界面
# frontend.py
import streamlit as st
import requests
import json
st.set_page_config(page_title="行业知识库AI助手", page_icon="🤖", layout="wide")
st.title("🤖 行业知识库AI助手")
st.markdown("基于专业文档的智能问答系统")
# 侧边栏配置
with st.sidebar:
st.header("配置选项")
temperature = st.slider("回答创造性", 0.0, 1.0, 0.1, 0.1)
api_url = st.text_input("API地址", "http://localhost:8000")
# 主界面
question = st.text_area("请输入您的问题:", height=100, placeholder="例如:请解释行业标准中的XXX要求...")
if st.button("获取答案", type="primary"):
if question.strip():
with st.spinner("正在检索知识库并生成答案..."):
try:
response = requests.post(
f"{api_url}/chat",
json={"question": question, "temperature": temperature}
)
if response.status_code == 200:
result = response.json()
# 显示答案
st.success("答案生成完成!")
st.markdown("### 📝 专业回答")
st.write(result['answer'])
# 显示参考来源
if result['sources']:
st.markdown("### 📚 参考来源")
for source in result['sources']:
st.write(f"- {source}")
# 显示置信度
st.metric("置信度评分", f"{result['confidence_score']:.3f}")
else:
st.error(f"请求失败:{response.text}")
except Exception as e:
st.error(f"发生错误:{str(e)}")
else:
st.warning("请输入问题内容")
# 知识库状态显示
with st.expander("📊 知识库状态"):
col1, col2, col3 = st.columns(3)
with col1:
st.metric("知识片段数量", len(chunks_with_embeddings))
with col2:
st.metric("支持的文件格式", "PDF/Word/TXT/MD")
with col3:
st.metric("向量维度", db_manager.dimension)七、系统部署与优化
7.1 Docker化部署
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["python", "-m", "uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]7.2 性能优化策略
检索优化:
class OptimizedRAGEngine(RAGEngine):
def __init__(self, collection, embedding_model):
super().__init__(collection, embedding_model)
self.cache = {} # 简单查询缓存
def optimized_retrieve(self, query: str, top_k: int = 5) -> List[Dict]:
"""带缓存的优化检索"""
# 查询缓存
cache_key = hash(query)
if cache_key in self.cache:
return self.cache[cache_key]
# 混合检索策略
results = self.retrieve_similar_chunks(query, top_k)
# 重排序提升准确性
reranked_results = self.rerank_results(query, results)
# 缓存结果
self.cache[cache_key] = reranked_results
return reranked_results
def rerank_results(self, query: str, results: List[Dict]) -> List[Dict]:
"""对检索结果进行重排序"""
# 基于相关性的重排序逻辑
# 可以集成更复杂的重排序模型
return sorted(results, key=lambda x: x['score'])八、实战案例:法律行业知识助手
8.1 行业特定配置
class LegalKnowledgeAssistant(SmartAssistant):
def __init__(self, api_key: str):
super().__init__(api_key)
self.legal_prompt_template = """你是一个专业的法律助手,请根据以下法律条文和案例回答问题。
{context}
问题:{question}
要求:
1. 准确引用相关法条
2. 如有相关案例可参考案例
3. 明确说明适用范围和限制
4. 如信息不足请明确告知
专业法律意见:"""
def generate_legal_answer(self, question: str) -> str:
"""生成专业法律回答"""
similar_chunks = self.rag_engine.retrieve_similar_chunks(question)
context = self.rag_engine.build_context(similar_chunks)
prompt = self.legal_prompt_template.format(
context=context, question=question
)
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.1
)
return response.choices[0].message.content8.2 效果评估指标
def evaluate_assistant_performance(test_cases: List[dict]) -> dict:
"""评估助手性能"""
results = {
"total_cases": len(test_cases),
"correct_answers": 0,
"average_confidence": 0,
"response_times": []
}
for test_case in test_cases:
start_time = time.time()
response = assistant.chat(test_case["question"])
end_time = time.time()
response_time = end_time - start_time
results["response_times"].append(response_time)
# 简单准确性评估(实际应用中需要更复杂的评估逻辑)
if self.evaluate_answer_quality(response["answer"], test_case["expected_answer"]):
results["correct_answers"] += 1
results["average_confidence"] += response["confidence_score"]
results["accuracy"] = results["correct_answers"] / results["total_cases"]
results["average_confidence"] /= results["total_cases"]
results["average_response_time"] = sum(results["response_times"]) / len(results["response_times"])
return results九、总结与最佳实践
通过本文的完整流程,我们构建了一个具备行业知识库的AI助手。关键成功因素包括:
-
高质量知识预处理:文档清洗和智能切片是基础
-
合适的向量化策略:选择与行业匹配的嵌入模型
-
优化的检索逻辑:平衡召回率和准确率
-
精心设计的Prompt:引导模型生成专业回答
持续优化建议:
-
定期更新知识库内容
-
收集用户反馈优化检索策略
-
监控系统性能和使用指标
-
根据业务需求调整参数配置
下一步:尝试将本系统应用到你的特定行业场景中,开始收集和整理专业文档,体验AI助手带来的效率提升!
以下是深入学习 RustFS 的推荐资源:RustFS
官方文档: RustFS 官方文档- 提供架构、安装指南和 API 参考。
GitHub 仓库: GitHub 仓库 - 获取源代码、提交问题或贡献代码。
社区支持: GitHub Discussions- 与开发者交流经验和解决方案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









