 FrugalDB:高效QoS支持的DBaaS
FrugalDB:高效QoS支持的DBaaS




面向高效支持具有服务质量保证的数据库即服务
亮点
- 提出了一种成本效益高的方案,以支持具有服务质量保证的数据库即服务。
- 设计了一种双引擎数据库框架来处理混合工作负载。
- 建立了适当的工作负载模型来描述租户工作负载。
-
提出了一种优化问题以解决工作负载迁移问题。
我们实现了这一机制,并通过大量实验评估了其效率。
1. 引言
互联网推动并普及了数据库即服务(DBaaS)(Agrawal et al. (2009); Hacig¨um¨us et al. (2002); Jacobs and Aulbach. (2007); Lehner and Sattler. (2010); Salesforce. (2014)),其中服务提供商在其基础设施上托管数据库应用,并将其作为服务提供给不同的最终用户(也称为租户)。由于数据库应用的所有权和运维被外包给数据库即服务提供商,租户通过网页浏览器或客户端程序访问其数据。
数据库即服务(DBaaS)的服务提供商通常将多个租户整合到相同的软硬件数据库堆栈中,以降低运营成本。当租户需要服务质量保证( QoS guarantees)时,服务提供商通常会根据其性能服务等级目标( SLOs)为租户预留足够的资源,以确保无论实际工作负载情况如何,所有租户的工作负载都能得到妥善处理。然而,通过资源预留方式,服务提供商只能实现较低的资源利用率。一方面,租户倾向于高估其性能服务等级目标,以确保所订阅的资源能够完全覆盖其业务的实际需求,而其实际工作负载往往达不到其性能服务等级目标;另一方面,多租户通常整体上表现出租户交流电(AC)较低的问题。
有效性(OTA)(雷因瓦尔德(2010);黄等人(2013)),因此实际资源需求通常低于租户所订阅的资源量。为了提高资源利用率,服务提供商通常会通过资源预留将比服务器可服务能力更多的租户整合到一台服务器上。但要保证为每个租户分配足够的资源仍具有挑战性。以内存缓冲区资源为例,当轻量工作负载消耗大量内存时,重度工作负载可能就没有足够的内存可用。
现有的数据库管理系统(DBMS)如MySQL或PostgreSQL具有大量的配置选项,用于调整资源和性能,而调整数据库配置需要经验丰富的数据库管理员(DBAs),他们需要密切观察并分析数据库工作负载,然后为数据库实例确定合适的配置。一旦设置得当,数据库配置通常不会更改,除非工作负载发生变化且数据库需要新的调优。数据库配置是一种全局设置,基于整体工作负载进行调优,几乎无法针对每个租户的特定表按租户分配特定数量的资源。因此,这些基于配置的解决方案无法适用于高度动态的多租户工作负载。
面向提升多租户环境下的资源利用率,本文提出了一种成本效益高的方案FrugalDB,旨在为具有动态工作负载且需保障服务质量(QoS)的大量小型租户提供服务。此处的小型租户指的是数据库规模相对较轻,数据量为数十兆字节或数百兆字节的租户。对于具有千兆字节级数据库、严格的服务质量要求以及稳定工作负载的租户,更合适的做法是将其封装在独立且配置适当的虚拟机(VM)中,这不在本文的研究范围内。本研究的一个典型应用是中小企业的客户关系管理(CRM),这些企业的数据库通常为数十兆字节级别,且工作负载高度不稳定(Salesforce. (2014))。
在此类应用中,通过共享表DBaaS工作负载整合方式,难以满足具有相似数据库模式的租户的性能服务等级目标(Weissman 和 Bobrowski. (2009))。
请注意,Curino 等人(2011)提出了一种用于其多租户数据库平台的缓冲池测量程序(Curino 等人(2011)),以估算数据库工作负载的工作集大小,从而能够使用最少的服务器合理整合多个数据库工作负载。他们的方法不适用于我们的目标场景,难点在于精确量化租户的资源需求要求租户工作负载保持稳定,而工作负载实际上会随时间动态变化。我们之前的工作(罗等人(2017))提出了一种通过工作负载迁移实现的混合工作负载处理方案,该方案采用两个独立的数据库引擎:一个内存引擎用于处理繁重工作负载,一个基于磁盘的引擎用于处理轻量工作负载,从而确保繁重工作负载的处理不会受到轻量工作负载的影响。其中,繁重工作负载主要指接近租户严格的服务等级目标的工作负载,而轻量工作负载则主要指远低于租户严格的服务等级目标的工作负载。基于该混合工作负载处理方案,本文提出了一个确定性模型和一个非确定性模型来描述租户的工作负载,并进一步提供了关于DBaaS工作负载整合方案的更详细信息以及更多实验结果,以展示该方案的有效性和效率。
我们工作的主要贡献包括:1)提出FrugalDB方法,结合工作负载迁移机制来处理具有性能服务等级目标的混合工作负载;2)将工作负载迁移问题建模为一个优化问题,并给出求解方法;3)实现了一个原型系统,并通过大量实验评估其性能。本文其余部分组织如下:我们首先在第2节介绍所提出的方案,在第3节中正式定义工作负载迁移问题并提出相应算法。第4节详细说明工作负载迁移的具体细节,第5节提供实验结果,第6节回顾相关工作。最后,我们在第7节对全文进行总结。
2. 框架
由于现代CPU具备越来越强大的计算能力,而磁盘设备的机械特性导致基于磁盘的存储子系统成为在线事务处理(OLTP)应用的瓶颈。因此,计算资源通常被严重低估使用,而内存和磁盘带宽则成为OLTP数据库系统的稀缺资源。满足OLTP应用性能服务等级目标的关键在于其工作数据集是否能够完全驻留在内存中。如果应用程序的工作集无法完全驻留在内存中,数据库将不得不频繁访问磁盘页面,从而导致整体性能下降,吞吐量降低,查询延迟增加,因此数据库只能满足相对较低的低性能服务等级目标。相反,如果配置的内存足够充裕,能够容纳应用程序的整个工作集,则数据库可以高效地处理大多数数据库操作,而无需访问底层磁盘,从而能够满足更高的性能服务等级目标。
鉴于此,我们提出了FrugalDB方案。我们的基本思路是将基于磁盘的数据库引擎和内存数据库引擎无缝集成,动态分离繁重工作负载与轻量工作负载,并为繁重工作负载提供充足的关键内存资源,其中基于磁盘的数据库引擎负责服务于大量具有轻量工作负载的租户,而内存数据库引擎主要负责服务于数量相对适中的具有繁重工作负载的租户。在此,我们将工作负载激增定义为提交给系统的总体工作负载超过基于磁盘的数据库引擎处理能力的情况。当即将发生工作负载激增时,FrugalDB会将繁重工作负载迁移到内存数据库引擎;当工作负载减少时,内存数据库引擎上的工作负载将被迁移回基于磁盘的数据库引擎。

通常情况下,基于磁盘的数据库引擎处理租户的工作负载。当发生工作负载激增时,基于磁盘的数据库引擎无法应对这些工作负载,从而导致服务等级目标违规。此时, FrugalDB 会启动内存数据库引擎,接管高负载强度的租户。这是通过将具有严格 SLO 的工作负载从基于磁盘的数据库引擎迁移到内存数据库引擎来实现的。当工作负载减少时,运行在内存数据库引擎上的工作负载可能会被重新迁移回基于磁盘的数据库引擎。通过这种方式,FrugalDB 能够顺利度过工作负载激增的周期,并减轻甚至避免服务等级目标违规的发生。在此过程中,迁移决策由 Workload Migration Engine(WME) 根据当前和历史工作负载以及一个预测模型做出,该模型用于预测即将到来的工作负载激增周期。历史工作负载可以来自现有的数据库工作负载整合系统,也可以由 FrugalDB 系统自身积累。对于现有的工作负载整合系统, FrugalDB 服务器可以逐步接管其工作负载,直到服务器承载的工作负载达到饱和并开始出现 SLO 违规,此时应启动新的 FrugalDB 服务器来接管剩余的工作负载,直至所有工作负载均被接管。每个 FrugalDB 服务器根据本文提出的工作负载整合策略独立运行。当然,这种逐步接管工作负载的整合过程可能不是最佳方案。
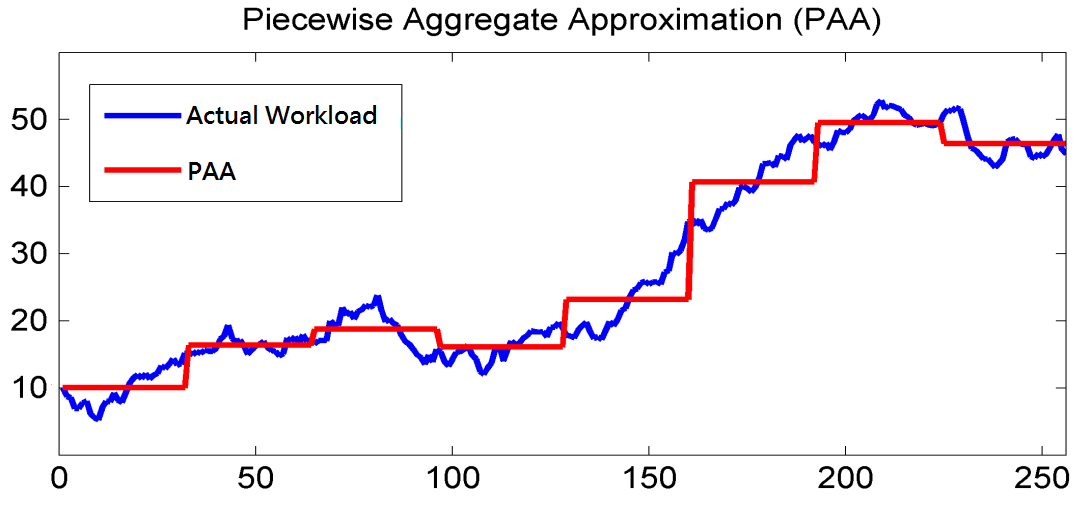
图2 展示了 FrugalDB 的以下主要功能模块: 1. 访问控制器(AC):该模块根据由工作负载迁移引擎(WME)生成的优化后的工作负载分配,将租户的请求路由到正确的数据库引擎,并将请求结果返回给租户。此外,它还保留所有租户请求的日志记录。2. 日志分析器(LA):该模块分析租户的请求日志,提取租户的工作负载特征,并为每个租户生成工作负载描述。3. 工作负载监视器( WM):该模块通过不同写请求百分比和并发租户数配置对基于磁盘的数据库引擎的处理能力进行基准测试,然后利用基准测试结果预测下一时间区间内是否会发生工作负载激增,并启动必要的工作负载迁移。4. 工作负载迁移引擎(WME):该模块基于工作负载信息和工作负载预测模型执行工作负载迁移计划。它包含三个子模块:MBE(MBE)、数据迁移器(DM)和数据重载器(DR)。当需要启动工作负载迁移过程时,MBE会评估所有活跃租户的工作负载迁移效益,并结合租户的工作负载描述、当前工作负载指标以及租户服务等级目标。然后,数据迁移器 将所选租户的数据从基于磁盘的数据库迁移到内存数据库中。当工作负载激增结束时,数据重载器 将数据重新加载回基于磁盘的数据库,以释放内存数据库引擎占用的内存资源。
由于数据迁移需要时间,每个待迁移的租户在迁移期间会在系统中保留两份数据副本。因此,我们必须在工作负载迁移期间正确处理数据请求,特别是当请求涉及插入、更新和删除操作等数据变更时,以确保数据一致性不受破坏。当FrugalDB将租户的数据迁移到内存数据库时, FrugalDB会收集迁移期间所有已更改的行,并在内存数据库中重放这些收集的行上记录的所有操作。当FrugalDB将租户的工作负载迁移回基于磁盘的数据库时,对租户数据的更改操作将在基于磁盘的数据库上执行。
3. 迁移调度
当 FrugalDB 预测到工作负载激增即将发生时,它会提前启动工作负载迁移过程,将短期突发性繁重工作负载从基于磁盘的数据库迁移到内存数据库中,从而高性能内存数据库能够及时处理这些工作负载,同时可以减轻基于磁盘的数据库的工作负载压力,以避免服务等级目标违规。为了优化工作负载迁移过程,我们建立了适当的工作负载模型,并将两个数据库引擎之间调度工作负载迁移的问题建模为一个优化问题,以确定应以最优迁移成本迁移哪些活跃租户的工作负载。
3.1. 工作负载建模
根据活跃度的不同,数据库即服务(DBaaS)租户的工作负载可分为三种状态:非活跃、轻度和重度。具体而言,非活跃租户没有数据服务请求;处于繁重工作负载状态的租户会产生大量的数据请求;而处于轻度工作负载状态的租户则产生中等数量的数据请求。由于我们将时间空间划分为一系列等长时间间隔,在同一时间间隔内,不同租户可能表现出不同的活跃度,且一个租户的活跃度也可能在不同时间间隔之间发生变化。也就是说,一个租户的工作负载可能在一个时间间隔内处于重度状态,在下一个时间间隔转为轻度状态,反之亦然。在存在大量小型租户且通常活跃度较低的场景中,大多数租户的工作负载在多数时间间隔内处于非活跃或轻度状态,同时仅有少量租户产生繁重工作负载,这可能导致其性能达到甚至超过性能服务等级目标。
这里,我们对租户工作负载有一个基本假设:一个租户遵循某种可重复且可预测的模式来生成其工作负载。该假设是合理的,因为租户倾向于周期性地执行类似的业务逻辑,从而遵循一定的统计模式生成符合其业务逻辑的工作负载。现有研究(Curino 等人(2011);Schaffner 和 Januschowski(2013);Elmore 等人(2013))通过使用真实工作负载进行实验验证了这一假设,并揭示出租户工作负载表现出明显的模式。我们可以通过分析历史数据中的工作负载来发现这些模式。为此,我们首先将历史数据的时间跨度划分为若干个 period,它们表示工作负载的时间周期(例如一天/一周/一月),可通过挖掘历史数据推断得出。然后,我们将每个 period进一步划分为一系列等长的时间槽,称为 intervals,并将其作为建模工作负载的最细时间粒度。最后,我们估计每个周期内各时间间隔的工作负载分布。
基于这一假设,我们考虑采用两种模型来描述适用于我们目标场景的租户工作负载:确定性模型和非确定性模型。我们认为,在较粗的时间粒度上为我们的目标场景构建工作负载模型比在更细的粒度上更为合适。例如,没有必要在秒级时间粒度上构建模型来描述租户工作负载,因为在如此精细的时间粒度下,租户的活动可能会表现出巨大的波动性。
设周期的长度为 Tw,它可以对应一天、一周或一个月。工作负载的周期性是指工作负载在每一天、每一周或每一个月表现出相似的模式或分布。我们将一个周期划分为 k个等长时间间隔,每个间隔的时长为 tw,记作{ti|i=1,2,…,k},其中k=dTw/twe。我们的模型通过分析过去周期中收集到的租户工作负载,来预测当前周期各个时间间隔内的租户工作负载。由于一个租户的工作负载由不同时间点提交的查询组成,我们使用一个时间间隔内的平均工作负载来表示该时间间隔的工作负载。也就是说,我们采用按时间间隔聚合查询的方式来近似租户的工作负载。我们将此方法称为分段聚合近似。具体而言,我们首先将一个时间间隔内的查询量累加,然后除以该时间间隔的区间时长进行平均。图 3展示了在一个周期内工作负载表示的一个示例。
3.1.1. 确定性工作负载模型
在确定性模型中,我们假设租户在相似的周期性时间大致产生相似的工作负载压力给数据库即服务系统,也就是说,我们可以预期一个租户的工作负载会以周期 Tw 为单位重复且确定性地生成,并且可以根据其历史工作负载精确预测该租户在某个时间间隔内的工作负载。形式上,假设一个周期包含 k 个时间间隔,且某租户的历史工作负载由 n 个周期组成,则该租户在第 r 个周期的第 j 个后续时间间隔中的工作负载 trj(r> n, 1 ≤ j ≤ k) wrj 可以预期为具有相似工作负载压力的先前对应时间间隔的平均值,即 wrj= ∑n h=1 whj n ,如图4 所示,其中每个周期由四个时间间隔组成。
3.1.2. 非确定性工作负载模型
在非确定性模型中,租户的工作负载以非确定性方式生成。具体而言,租户在某个时间间隔内产生的工作负载压力被视为一个随机事件。对于每个租户,我们通过考虑多个周期的历史工作负载数据来估计其工作负载分布。为简化起见,我们将每个时间间隔的工作负载量离散化为 l子范围或级别,表示为 S1,…, Sl。然后我们计算不同周期中相同时间间隔内生成的工作负载子范围的统计分布。
形式上,设 wij 为第 j个周期的第 i个时间间隔(1 ≤ i ≤ k, 1 ≤ j ≤ n) 中的工作负载,租户在第i个时间间隔的工作负载落入子区间 Sm(1 ≤ m ≤ l)的 概率由 Pr(i, m)= Fr(Sm ) n估计, 其中 Fr(Sm) = ∑ n j =1 H(wi j ),且当 wi j 落在 Sm中时, H(wi j )= 1,否则 为0。对于每个租户,我们估计 Pr(i, m)对应的 1 ≤ i ≤ k和1 ≤ m ≤ l。图5展示了非确定性工作负载模型的一个示例。此处,每个周期包含五个时间间隔,每个时间间隔内的工作负载被离散化为三个子区间,分别从概念上表示为 Low、 Middle和 High。第五个时间间隔的工作负载分布在 Low、 Middle和 High三个层级分别为10%、30%和60%。
对于每个租户,我们必须在较长的时间跨度内收集历史工作负载,以便拥有足够的历史数据来为该租户建立准确的概率模型。否则,该概率模型可能无法反映租户实际的工作负载变化。我们认为,可以从数据库即服务提供商处收集到足够多的历史工作负载轨迹,从而构建可靠的概率模型。
3.2. 问题建模与优化
此处,我们正式提出工作负载迁移问题。设 U表示所有租户的集合,每个租户 ui ∈ U被描述为一个三元组{Oi, Si, Wi,t},其中 Oi表示 ui的性能SLO(即 ui将产生的最大工作负载压力), Si表示 ui的数据大小,Wi,t表示 ui在时间 t的工作负载压力。在时间t的所有活跃租户的集合记为 UAt, 我们假设 UAt占所有租户的比例近似为常数。我们将时间 t提交到数据库即服务系统的全部请求中写请求的平均百分比记为 Wt,将在时间 t基于磁盘的数据库和内存数据库的最大请求处理能力分别记为 WDISKt和 WMEMt。我们还将内存数据库引擎中配置用于数据存储的最大内存大小记为MEMLIMIT。
当工作负载激增发生在时间 t 时,我们的目标是将每个活跃租户恰好分配到三个互不相交的租户集合之一: UDISKt、 UMEMt 和 UV IOt,以最小化总的性能服务等级目标违规。这里,UDISKt 是指在时间 t 时其性能服务等级目标将由基于磁盘的数据库引擎满足的租户集合, UMEM t 是指其性能服务等级目标将由内存数据库引擎满足的租户集合,而 UV IO t 是将被拒绝数据服务请求的租户集合。我们的问题被表述为最小化
$$
\sum_{i\in UV IOt} Wi,t, (1)
$$
约束条件:
$$
\sum_{i\in UDISKt} Wi,t \leq W DISKt, (2)
$$
$$
\sum_{i\in UMEMt} Si \leq MEMLIMIT, (3)
$$
$$
\sum_{i\in UMEMt} Wi,t \leq W MEMt. (4)
$$
约束(2) 保证分配给基于磁盘的数据库引擎的所有活跃租户的工作负载不超过其最大请求处理能力,约束(3) 保证分配给内存数据库引擎的所有租户的总数据量不超过其内存大小,约束(4) 保证分配给内存数据库引擎的所有租户的工作负载不超过其最大请求处理能力。
我们针对上述优化问题的解决方案是一种启发式方法。为简化问题,我们假设内存数据库引擎能够有效处理其内存所能容纳的所有工作负载。这是合理的,因为内存数据库引擎的性能瓶颈在于其内存容量,而非其查询处理能力。因此,约束(4)可以忽略,因为它必然成立。注意,在时间 t 的总工作负载是固定的,我们将其表示如下:
$$
WT OTt= \sum_{i \in U DISK t} Wi,t+ \sum_{i \in U MEM t} Wi,t+ \sum_{i \in UV IO t} Wi,t. (5)
$$
因此,我们的目标转化为在满足约束(2)和约束(3)的前提下,最大化公式 (5)中第一部分和第二部分的总和。接下来,我们尝试在满足约束(3)的前提下最大化公式(5)的第二部分。如我们稍后将看到的,该问题可被建模为一个背包问题。现在,我们假设公式(5)的第二部分已被最大化,此时最大化第一部分等价于最小化第三部分。让我们考虑那些不属于 UMEM t的租户。
我们需要决定将哪些租户分配给 UDISKt,同时满足约束(2),以最小化目标函数公式(1)。为此,我们先将不属于 UMEMt的所有租户分配给 UDISKt,然后基于贪心策略,优先选择工作负载最高的租户,再逐步选择工作负载较低的租户,将其分配给 UV IOt,直到满足约束(2)为止。接下来,我们的剩余工作是在满足约束(3)的前提下最大化公式(5)的第二部分,这是一个经典的0/1背包问题。
我们定义函数 F(n, m) 为在考虑 UAt 中前 n 个租户且满足以下条件时,公式(5)中第二项的最大值:
$$
\sum_{i\in UMEMt} Si \leq m. (6)
$$
注意约束(6)与约束(3)不同,其中 MEMLIMIT被值 m所替代。因此, F(N, MEMLIMIT)是我们需要计算的优化值,假设我们总共有 N个租户。
显然:
$$
F(0, m)= 0, 0 \leq m \leq MEMLIMIT. (7)
$$
对于 n> 0,我们有:
$$
F(n, m)=
\begin{cases}
\min{F(n− 1, m), F(n− 1, m− Sn)+ Wn,t}, & Sn \leq m \leq MEMLIMIT \
F(n− 1, m), & 0 \leq m< Sn
\end{cases}
(8)
$$
我们还定义了一个函数 P(n, m) 如下:
$$
P(n, m)=
\begin{cases}
-1, & n= 0 \
0, & (n> 0)\wedge(m< Sn \vee F(n, m) \neq F(n− 1, m− Sn)+ Wn,t) \
1, & n> 0 \wedge m \geq Sn \wedge F(n, m)= F(n− 1, m− Sn)+ Wn,t
\end{cases}
(9)
$$
我们遍历从 0 到 N 的每一个可能的值 n,以及从 0 到 MEMLIMIT 的每一个可能的值 m,以计算函数 F。同时,我们使用函数 P 来确定哪些租户应被分配给 UMEM t ,其中 P(n, m) = 1 表示第 n 个租户应被分配给 UMEM t 。如果 P(n, m) = 1,那么我们检查 P(n−1, m−S n) 以查看第 (n−1) 个租户是否应被分配给 UMEMt;否则我们检查 P(n−1, m)。我们继续此过程直到 n= 0, 然后我们将确定出 UMEMt 集合,正如算法2中所述。
算法1和算法2分别描述了租户分配过程以及用于解决0/1背包问题的整体算法。在算法1中,第1‐2行将 UDISKt和 UV IOt初始化为空集。第3行调用算法2来计算函数 F和 UMEMt。第4‐10行将所有租户放入 UDISKt 中(除了那些已在 UMEMt中的租户),并计算这些租户产生的总体工作负载。第11‐16行决定最终应将哪些租户分配给 UV IOt。在算法2中,第 1‐5行初始化 UMEMt、函数 F和函数 P。第6‐20行通过动态规划求解 0/1背包问题,第21‐29行计算UMEMt。
算法 1 租户分配
输入: t, Ta,t,Mv,WLM,t
1: TM,t ←{}
2: TV i,t ←{}
3:运行算法 2 以获取 F(n, Mv) 和 TV o,t
4: WLTt ← 0
5:对于 i= 1到 n 执行
6: if i 不在集合 TV o 中, t那么
7: WLTt ← W LTt+ W Li,t
8: TM,t ← TM,t+{i}
9:结束 if
10:结束 for
11:当 WLTt> W LM,t do
12: id ←top(TM,t)
13: WLTt ← W LTt − W Lid,t
14: TV i,t ← TV i,t+{id}
15: TM,t ← TM,t −{id}
16:结束循环
输出: TM , t, TV o , t, TV i ,t
算法 2 在内存数据库引擎中最大化工作负载
输入: UAt:活跃租户的集合
MEMLIMIT:内存中用于数据存储的内存大小 数据库引擎
输出: UMEMt:分配给内存数据库引擎的租户
1: UMEMt ←{}
2:对于 m ← 0到 MEMLIMIT 执行
3: F(0, m) ← 0
4: P(0, m) ← −1
5:结束循环
6: for n ← 1到 N do/*0/1背包问题求解器*/
7:对于 m ← 0到 MEMLIMIT 执行
8:如果 Sn ≤ m 且 F(n− 1, m) ≤ F(n− 1, m− Sn)+ Wn,t,则
9: F(n, m) ← F(n− 1, m− Sn) + Wn,t
10: P(n, m) ← 1
11: else
12: F(n, m) ← F(n− 1, m)
13: P(n, m) ← 0
14: 结束 if
15:结束 for
16:结束 for
17: id ← N
18: capacity ← MEMLIMIT
19:当 id ≠ 0 时执行 do
20:如果 P(id, capacity)= 1 那么
21: UMEMt ← UMEMt ∪{idth租户}
22: capacity ← capacity − Sid
23:结束如果
24: id ← id− 1
25:结束循环
4. 运行时迁移
当数据库即服务系统的工作负载压力适中,且基于磁盘的数据库引擎足以处理所有活跃租户的工作负载时,基于磁盘的数据库引擎将处理所有租户的请求。随着系统工作负载压力加剧,基于磁盘的数据库引擎可能无法服务所有活跃租户,此时部分租户的工作负载必须迁移到内存数据库引擎中,而其余工作负载则未迁移的仍将由基于磁盘的数据库引擎处理。
工作负载迁移涉及三个技术问题:数据迁移、数据回迁和数据一致性。为了迁移租户的工作负载,FrugalDB 将该租户的数据加载到内存数据库中,并将该租户提交的所有数据服务请求从基于磁盘的数据库引擎重定向到内存数据库引擎进行处理。一旦数据库即服务系统上的工作负载压力减小,租户工作负载将被回迁至基于磁盘的数据库引擎,同时内存数据库中更新的数据将被同步到基于磁盘的数据库中,从而释放内存数据库中的内存资源,以供后续的工作负载迁移使用。随后,回迁租户提交的所有请求将重新被导向基于磁盘的数据库进行处理。由于数据迁移/回迁需要时间,在迁移/回迁过程中,每个已迁移的租户在系统中会保留两份数据副本。因此,我们必须妥善处理这两份数据副本之间的数据同步,以确保数据一致性不受影响。
4.1. 处理数据一致性
对于工作负载已迁移到内存数据库的租户,基于磁盘的数据库将继续处理该租户的请求,直到所有数据都已加载到内存数据库中,此时内存数据库即可接管该租户的全部数据请求。在数据加载期间,请求可能会更改基于磁盘的数据库中的数据,从而导致内存数据库与基于磁盘的数据库之间的数据不一致。因此,我们必须在工作负载迁移期间正确处理租户的请求,尤其是涉及数据变更的请求,包括插入、更新和删除操作。
我们为每个租户的表在基于磁盘的数据库和内存数据库中均添加了四列属性:rowId、isInserted、isUpdated和isDeleted。其中,rowId 属性用于快速定位数据库表中的行,每次向表中插入一行时,其值递增 1。isInserted、isUpdated和isDeleted属性用于标识对某一行执行的更新操作类型。当租户的数据在数据迁移过程中发生变化时,FrugalDB 通过为相应行正确设置这三个属性来记录更新操作。最初,每行的这三个属性均被设置为“FALSE”。当插入一行时,其rowId属性被正确设置,并且其 isInserted属性被设为“TRUE”;当更新一行时,其isUpdated属性被设为“TRUE”;如果删除一行,则将其isDeleted属性设为“TRUE”。当内存数据库完全接管租户工作负载的处理,任何更改租户数据的操作都会被记录在内存数据库中。
4.2. 数据迁移与重新迁移
当 FrugalDB 将租户的数据迁移至内存数据库中的表时,这些内存表的 isInserted、isUpdated 和 isDeleted 属性均被设置为“假”。在租户数据完全迁移至内存数据库后,FrugalDB 会收集迁移过程中所有已更改的行,并在内存数据库中重放这些收集的行中记录的所有操作:插入 isInserted 属性为“真”的行,使用最新数据更新 isUpdated 属性为“真”的行,并删除 isDeleted 属性为“真”的行。由于在内存表上重放这些操作非常高效,我们在重放期间会阻塞任何操作。之后,内存数据库将接管该租户工作负载的处理。
当 FrugalDB 将租户的工作负载迁移回基于磁盘的数据库时,任何已更改该租户数据的操作都应反映到基于磁盘的数据库中。在基于磁盘的数据库上执行的更新操作,由内存表中每一行的 isInserted、isUpdated、 isDeleted 属性值共同决定,如表1所示。具体而言,FrugalDB 首先收集已更新的行,并将这些行在内存表中的 isInserted、isUpdated、 isDeleted 属性设置为“假”,然后在基于磁盘的数据库中执行相应的更新操作。如果在将更新数据同步到基于磁盘的数据库期间,内存表中又发生了新的更新,FrugalDB 将重新收集新更新的行,并再次将这些更新重放到基于磁盘的数据库的表中。
5. 性能评估
在本节中,我们通过大量实验验证了FrugalDB的有效性和效率。结果表明,与各种基线实验设置相比,FrugalDB不仅能够实现更高的租户整合度,还能在保证租户性能服务等级目标的前提下显著降低查询处理延迟。
5.1. 实验设置
所有实验均在两台物理机器上进行,这两台机器通过一台1000M高速以太网交换机互连。其中一台机器作为服务器机器运行FrugalDB以处理租户的工作负载,另一台机器运行线程作为客户端来模拟租户的活动。服务器机器配备了一个八核Intel Xeon处理器和24GB内存,安装了 Ubuntu Linux、MySQL(5.5版)和VoltDB(企业版4.9);客户端机器配备了一个八核Intel Xeon处理器和16GB内存,同样安装了Ubuntu Linux。由于可用的真实多租户OLTP工作负载较少,我们基于TPCC (2017)和YCSB(Cooper等(2010))生成合成工作负载,用于评估 FrugalDB及其基线设置的性能。TPC‐C和YCSB是流行的标准化数据库基准测试规范,包含读取和更新操作,用于模拟复杂数据库应用的活动。
由于FrugalDB的目标应用场景主要包含数据访问请求相对简单的租户,我们提取了TPC‐C和YCSB查询中包含的所有读取和更新操作,并利用这些操作生成基准工作负载,其中每个租户请求仅包含这些提取的操作之一。综合基准工作负载由具有相应性能SLO、不同数据大小和不同读写比例的租户组成,如表2所示。性能SLO的值指定了一个租户每分钟可生成的请求上限。例如,具有性能SLO的租户每分钟100次请求的租户最多可向多租户平台发送100个请求。为简化起见,我们设置了三个性能SLO级别:低、中和高。我们使用三种低‐中‐高性能 SLO组合测试FrugalDB:5‐50‐500、20‐60‐200和100‐150‐200,其中 5‐50‐500组合设为默认设置,代表租户具有多样化性能SLO的场景。20‐60‐200组合代表租户性能SLO差异较小的场景,而100‐150‐200组合代表租户需要几乎相等性能SLO的场景。通过这三种性能SLO组合的评估,可以全面揭示FrugalDB在各种场景下的有效性。
对于每个实验设置,我们运行实验五次以测量 FrugalDB 和其他基线实现的性能,并报告相应性能指标的平均值作为最终结果。每次实验持续三十五分钟,包含七个五分钟时间间隔。需要注意的是,在真实的多租户环境中,租户并非同时处于活跃状态,因此我们使用tenant active ratio来表示活跃租户占所有租户的比例,默认租户活跃比率为30%。由于租户的活跃度随时间变化,不同时间间隔内的活跃租户可能不同。我们随机选择部分活跃/非活跃租户,使其切换非活跃/活跃状态(从非活跃变为活跃或反之),但在所有时间间隔中保持活跃租户的总数不变。在每个时间间隔内,我们首先根据泊松分布为活跃租户分配工作负载,并要求分配给租户的工作负载不超过其性能SLO;然后在整个时间间隔内将每个租户的工作负载稳定在所分配的水平。如果分配的工作负载超过租户的性能SLO,则将其工作负载设置为其性能SLO。
由于我们主要希望评估FrugalDB处理工作负载突发的性能,因此在七个五分钟时间间隔中,将第三个、第四个和第六个时间间隔设置为工作负载突发区间;在这些突发区间内,所有活跃租户的工作负载均设置为其性能服务等级目标,其总量足以超过基于磁盘的MySQL数据库的处理能力。在非工作负载突发区间,租户工作负载按比例设置为低于其性能服务等级目标,实验中该比例设为20%。对于非工作负载突发区间内某个租户的工作负载,我们首先根据其性能服务等级目标,按照泊松分布,并为该时间间隔内生成的工作负载分配20%给租户。FrugalDB 利用非工作负载突发的时间间隔,将租户数据从基于内存的 VoltDB 数据库迁入/迁出到 MySQL 数据库中,以实现工作负载迁移。基于内存的 VoltDB 数据库的内存存储容量是影响 FrugalDB 性能的重要因素,因为它决定了可以将其工作负载迁移到 VoltDB 数据库中的租户数量。我们将 FrugalDB 的默认内存存储容量设置为 2000MB。
5.2. 结果与分析
我们将FrugalDB在满足租户性能服务等级目标以及对租户查询的响应性方面与基线设置进行比较。我们定义租户的性能服务等级目标是否被满足如下:如果一个租户的性能服务等级目标为 A,即该租户每分钟最多可处理 A个查询。现在该租户实际发起了B个查询,但在一分钟内仅收到 C个查询响应,则我们认为该租户有 min(A, B)‐C个查询未被满足。如果 min(A, B)‐C为0,则称该租户的性能服务等级目标在一分钟内被满足;否则,称该租户的性能服务等级目标被违反,且该租户在一分钟内有 min(A, B)‐C个查询未完成。我们以每分钟性能服务等级目标被违反的租户数量作为评估FrugalDB满足租户性能服务等级目标能力的指标,并以查询延迟百分比作为评估FrugalDB对租户查询响应性的指标。
5.2.1. 与静态SLO的比较
我们首先通过模拟将 FrugalDB 与 Lang 等人 (2012) 提出的方法进行比较,该方法旨在最小化具有不同硬件配置和处理能力的服务器数量,以满足一组租户的性能服务等级目标。他们仅考虑了租户的性能服务等级目标未考虑动态工作负载,因此他们的方法属于具有SLO保证的静态工作负载整合,本文中我们称之为静态SLO。
由于FrugalDB结合了基于磁盘的数据库和内存数据库,我们认为我们的多租户平台拥有两种不同类型的数据库服务器,即基于磁盘的数据库服务器和内存数据库服务器,并基于这两种类型的服务器实现了静态 SLO方案。我们首先对FrugalDB数据库服务器能够实现的租户整合进行基准测试,然后计算静态SLO方案为满足这些租户的SLO所需的两类数据库服务器的最小数量,从而通过将每个租户的工作负载分配到相应的服务器上获得工作负载整合方案。根据静态SLO方法,至少需要三台MySQL服务器和两台VoltDB服务器才能满足所有租户的SLO,而FrugalDB仅需一台服务器。我们主要对FrugalDB和静态SLO方案所实现的查询延迟进行了基准测试,结果如图6所示。可以看出,对于85%的查询,FrugalDB和静态SLO方案能够提供相似的延迟,而对于其余15%的查询,FrugalDB 提供的延迟明显更高但仍处于可接受范围内。FrugalDB能够实现比静态 SLO方法高得多的工作负载整合率的原因在于,FrugalDB在更细的时间尺度上调整资源调度,能够比静态SLO方法更快地响应工作负载波动,从而实现更高的资源效率。这证明了轻量级资源管理机制相比重量级机制具有更好的灵活性,进而提升资源效率。
5.2.2. 租户整合
我们测量了不同多租户实现在TPC‐C和YCSB工作负载下能够在不违反性能SLO的情况下服务的租户数量,即租户整合容量。我们基于非确定性工作负载模型,将FrugalDB与纯VoltDB实现以及基于资源预留方案的纯MySQL实现进行比较。我们评估了MySQL数据库能够支持的工作负载达到其性能SLO的租户数量,并将该数量作为MySQL数据库在资源预留方案下可提供的租户整合容量。
在非确定性工作负载模型下,各种多租户数据库实现的租户整合情况如下:完全基于VoltDB数据库的实现提供的租户整合最低;完全基于MySQL数据库的资源预留实现比基于VoltDB的实现高出两倍的租户整合;而 FrugalDB相比基于VoltDB的实现可实现近十倍更高的租户整合,比基于 MySQL的资源预留实现高出四到五倍。
不难想象,基于VoltDB的实现所提供的租户整合能力最低,因为在开始处理租户的工作负载之前,必须先将该租户的数据加载到内存中,而内存存储容量限制了其租户整合能力。基于资源预留的MySQL实现则受限于存储子系统,当服务的租户总数超过其处理能力时,需要大量的磁盘访问,从而导致对内存缓冲区资源的激烈争用。FrugalDB能够提供高得多的租户整合能力,主要原因有两个:1)大量非活跃租户消耗资源较少,它们驻留在MySQL数据库中共享磁盘带宽、内存缓冲区和中央处理器资源;2)高活跃度租户的大部分工作负载与低活跃度租户的工作负载相分离,并通过高性能的VoltDB数据库保证获得足够的关键资源(即内存缓冲资源),因此不会受到仍驻留在MySQL数据库中的大量低活跃度租户的影响。这表明内存资源是满足租户性能服务等级目标最关键的资源,在考虑租户的性能服务等级目标时,我们应首先考虑如何保证租户拥有足够的内存资源。
请注意,使用确定性工作负载模型可实现的租户整合能力并未进行基准测试,在该情况下FrugalDB能够提供比非确定性工作负载模型更高的租户整合度,因为在非确定性工作负载模型下迁移到VoltDB的预期高强度工作负载有可能实际上并未成为高强度工作负载,而确定性工作负载模型下的所有工作负载迁移都将有效。
5.2.3. 租户SLO的满足情况
我们在基于MySQL数据库的多租户数据库实现和FrugalDB上,对不同内存存储容量下租户性能SLO的满足情况进行基准测试。为了确保 FrugalDB与基于MySQL的实现在相同配置下进行比较实验,我们未采用资源预留方式来测试基于MySQL的实现(因为其支持的租户数量远少于 FrugalDB),而是采用无任何控制机制的尽力而为方式来保障租户的性能 SLO。图8和图9展示了评估结果。可以看出,MySQL上性能SLO被违反的租户数量远远超过FrugalDB;随着FrugalDB内存存储容量的增加,其上 SLO被违反的租户数量减少;当FrugalDB的内存存储容量设置为2000 MB时,所有租户的SLO均得到满足。
此外,我们对FrugalDB和基于MySQL的实现在不同租户活跃比率下租户性能SLO的满足情况进行基准测试,评估结果如图10和图11所示。可以看出:在基于MySQL的实现中,随着TPC‐C工作负载的租户活跃比率增加5%,其 SLO被违反的租户数量增加了 80∼120;对于YCSB工作负载,该数量增加了 120∼140;而在FrugalDB中,直到租户活跃比率上升至30%之前,所有租户的SLO均得到满足,当租户活跃比率增至30%时,部分租户的SLO可能无法保证。当租户活跃比率增加到40%时,活跃租户的总数超过了FrugalDB的处理能力,导致SLO被违反的租户数量增加到TPC‐C工作负载约200个, YCSB工作负载约380个。
最后,我们在 FrugalDB 和基于MySQL的实现上,针对不同的低‐中‐高性能SLO组合,对租户性能服务等级目标的满足情况进行评估,评估结果分别如图12和图13所示。可以看出,不同的低‐中‐高性能SLO组合导致了巨大的差异。对FrugalDB和MySQL的性能均有影响:对于TPCC和YCSB工作负载,当 SLO组合为5‐50‐500时,FrugalDB能够保证所有租户的服务等级目标;当SLO组合为20‐60‐200时,有少量租户的服务等级目标无法得到保障;而当SLO组合设置为100‐150‐200时,大量租户的服务等级目标被违反,此时FrugalDB的性能仅略优于基于MySQL的实现。这是因为当SLO组合设置为100‐150‐200时,租户的工作负载多样性不明显,导致FrugalDB的优化空间较小,工作负载迁移机制的优势无法明显体现。SLO组合的影响也表明了FrugalDB的应用场景,即在租户活跃度和工作负载强度存在显著差异的多租户数据库应用中,FrugalDB能够提供更好的租户整合效果。
5.2.4. 查询延迟
我们将FrugalDB在不同实验设置下针对租户查询的响应延迟,与完全基于MySQL数据库的多租户数据库实现进行了比较。图14和图15展示了在不同租户活跃比率下,FrugalDB和基于MySQL的实现在评估中获得的结果。可以看出,FrugalDB在大多数租户查询上的整体响应延迟更低,且租户活跃比率对大多数租户查询的延迟影响较小。图16展示了 FrugalDB与基于MySQL的实现在评估中取得的结果,在不同的租户SLO组合下进行评估,我们可以看到FrugalDB实现了更低的租户查询响应延迟。
5.2.5. 内存消耗和数据迁移成本
最后,我们报告了在整个实验过程中FrugalDB中VoltDB数据库的内存消耗统计情况,以及将数据从MySQL数据库迁入/迁出VoltDB数据库的时间成本,评估结果如图17所示。我们可以看到:随着VoltDB数据库的内存存储容量增加,其总内存消耗迅速上升,并且增加内存存储容量500MB导致总体内存消耗增加了1000MB∼1500MB,因为VoltDB需要更多的内存缓冲资源来处理增加的工作负载;在工作负载激增之后,总体内存消耗减少,原因是少数租户仍驻留在VoltDB数据库中,已消耗的内存资源可被释放回操作系统;将租户数据加载到VoltDB的时间成本当然随着其内存存储容量的增加而线性增长,加载500MB租户数据大约需要130秒,这也是为什么我们应提前启动工作负载迁移过程的原因;在将更新的数据从VoltDB迁移到MySQL以进行数据持久化仅占用数据加载所花费时间的四分之一,因为只有一部分整体数据被更新并需要持久化到MySQL数据库中。 由于在两个数据库之间迁移租户数据的成本仍然很高,我们应进一步优化工作负载整合方案以减少数据迁移,并寻求更高效的数据加载技术以加快数据迁移速度。
6. 相关工作
数据库即服务作为在云环境中提供服务的一种具有成本效益的数据管理模式,正变得越来越流行。已经出现了大量研究工作致力于改进云环境中支持混合工作负载的多租户服务。此前关于数据库即服务(DBaaS)的研究在缺乏性能保证的情况下,主要专注于实现共享模式多租户中的极高整合水平,其中具有相似数据库模式的数万个租户共享公共表,但其数据库工作负载几乎不活跃。Aulbach 等人 (2008) 提出了块折叠(Chunk Folding),该方法将租户逻辑表垂直划分为块,并将其折叠到不同的共享物理表中,必要时可通过连接操作支持查询处理。许等人 (2009) 提出了位图解释元组(BIT)和多分离索引( MSI),以提高将来自不同租户的元组合并到共享表中的可扩展性和效率。席勒等人 (2011) 在数据库中实现了感知租户的多租户机制,从而增强了数据库可扩展性的灵活性。这些研究很少从按租户基础考虑租户的资源需求,而我们的目标主要是满足租户在其SLO内高度动态的资源需求,因此这些研究均无法提供此类服务。
辛格等人 (2015) 对云环境中的服务质量感知的自主资源管理进行了有意义且全面的调研。他们从系统化视角出发,比较和分析了各种现有资源管理技术、框架和机制的特点与特征,使研究人员能够从中获得有益的见解,以发现自主资源管理的重要特性,并为特定应用选择最合适的自主资源管理技术,同时指出了重要的未来研究方向。辛格等人 (2017) 还提出了一种称为 STAR 的服务等级协议感知自主资源管理技术,旨在降低服务等级协议违规率,以实现高效交付云服务。这些现有研究大多集中在虚拟化云环境中针对自主资源管理的自愈、自配置、自优化、自保护技术,涉及资源配置、供给与调度、容错、安全与攻击检测以及资源管理优化等方面;然而,很少有研究关注具有数据库工作负载独特特性的数据库即服务服务。对于具有服务质量保障的高度动态租户工作负载,我们需要以轻量级方式设计和实现工作负载整合方案,以实现高租户整合率,而这一点在共享机器的重度多租户数据库即服务服务方案中是无法实现的。
一些关于具有性能保证的数据库即服务的现有研究主要集中在虚拟化云环境中的资源供应(Soundararajan 等人 (2012);熊等人 (2011)),通过配置、供应和整合虚拟机(VM)以避免资源过度供应。Soror 等人 (2008) 提出了一种方法,可针对在同一硬件上整合的不同数据库工作负载自动配置虚拟机;Soundararajan 等人 (2012) 提出一个系统,用于确定虚拟机的资源分区;沈等人 (2011) 提出了 CloudScale,用于在线预测基于虚拟机的应用的资源需求,并实现细粒度的弹性资源扩展自动化,以及通过虚拟机迁移解决扩展冲突。Cecchet 等人 (2011) 提出了 Dolly,该系统利用虚拟机克隆技术生成数据库副本,以应对在云中供应无共享复制数据库的挑战。Nathuji 等人 (2010) 提出了 Q‐Clouds,这是一个感知服务质量的控制框架,可动态调整资源分配,以减轻在同一服务器上整合的应用之间的性能干扰。基于虚拟机的整合方法只能实现适度整合,因此仅适用于数据库之间的强隔离比成本/性能更重要的场景。这些研究在相对粗粒度级别上管理虚拟机的资源,无法在更细粒度级别上控制资源,从而难以为租户的表进行适当的资源配置。然而,某些方法可以补充我们的方法,以更好地应对各种情况,例如,当总体工作负载超过单个 FrugalDB 服务器的处理能力时,采用准入控制(熊等人 (2011))和工作负载调度(黄等人(2013))机制来避免工作负载过载。
与以虚拟机形式打包资源不同,Curino 等人 (2014) 以及 Narasayya 等人 (2013, 2015) 提出了 SQLVM,通过在数据库服务器进程中保留租户指定的资源,为多租户数据库即服务提供隔离的性能,这可被视为一种轻量级基于虚拟机的整合。Curino 等人(2011)和 Lang 等人 (2012) 提出了将多个数据库工作负载整合到同一个数据库进程中的方法,旨在最小化满足大量租户性能目标所需的服务器数量。所有这些方法都遵循资源预留方式,适用于具有相对稳定工作负载的场景。方法,侧重于通过资源预留进行资源配置、通过虚拟机迁移进行工作负载调度,可能会产生过高的执行成本,因此适用于整合具有稳定的工作负载,而我们的目标场景涉及高度动态的工作负载,在这些场景中,需要为大量工作负载差异显著的租户提供性能保证。我们的工作重点是通过在内存数据库引擎之间临时迁移短期持续的繁重工作负载,来妥善处理在同一数据库服务器上整合的众多租户的高度动态繁重工作负载。
7. 结论
为了改善租户整合并降低运营成本,我们提出了一种新的方法来实现具有性能保证的数据库即服务。我们的目标场景是,在大量租户中仅有适度比例的活跃租户同时生成足够的请求以满足其性能SLO。该方法采用双引擎框架,其中基于磁盘的数据库用于处理来自轻量工作负载租户的大规模数据服务请求,而内存数据库则用于临时卸载重度工作负载,以减轻基于磁盘的数据库的压力,前提是后者自身能够保证所有活跃租户的性能 SLO。
我们采用模型来预测工作负载,并将基于磁盘的数据库与内存数据库之间的工作负载迁移问题建模为一个优化问题,然后设计了算法将该工作负载迁移问题转化为背包问题进行求解,其中尽可能将租户的繁重工作负载分配给内存数据库引擎,而将租户的轻量工作负载分配给基于磁盘的数据库引擎。从而可以使数据库即服务(DBaaS)方案为处理租户的繁重工作负载预留足够的内存资源,进而最小化性能保证的违规情况。
工作负载模型的准确性对我们的多租户工作负载处理优化方案至关重要。我们采用通过分析历史活动日志得到的工作负载模型,来预测即将到来的工作负载,从而预测未来的资源需求。从历史日志中提取合适的工作负载模型并非易事,已有大量研究致力于工作负载建模,因此我们并未在如何获取合适的工作负载模型上投入过多精力,而是专注于利用这些模型来优化租户工作负载的处理。我们假设一个租户在某个时间间隔内产生的工作负载为随机事件,并研究工作负载预测的影响。准确性在实验结果中得到一定程度的体现,因为一些预期为重度的租户工作负载实际上可能表现为轻度,反之亦然,因此工作负载的生成具有一定程度的不确定性。如果我们能够找到并采用一些更准确的工作负载模型,就可以实现更高的租户整合率,从而提供更具成本效益的数据库即服务云服务。
我们通过大量实验验证了我们的方法,实验结果表明,我们的方法在高效应对工作负载激增的同时,实现了令人印象深刻的高租户整合。据我们所知,这项工作是首次尝试利用内存数据库技术为多租户服务以支持海量租户的。

















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









