




 本文深入探讨了Python中列表、栈等数据结构的实现原理及常用操作,并分析了它们的时间复杂度。
本文深入探讨了Python中列表、栈等数据结构的实现原理及常用操作,并分析了它们的时间复杂度。
python自身的数据容器,如 列表,元组,字典等都是很好的工具,但是有时候我们需要特定的数据结构 如队列,二叉树等特定的数据结构,这些时候我们可以借助list,或者pathon语言特性来设计。
一:列表的操作
在python中列表作为使用最多的容器,必须知道它的特性和常见的操作函数,首先来看列表的四种常见的插入操作并随后分析它的时间复杂度。
def test1():
l = []
for i in range(10):
l = l + [i]
print (l)
print('\n')
def test2():
l = []
for i in range(10):
l.append(i)
print(l)
print('\n')
def test3():
l = [i for i in range(10)]
print(l)
print('\n')
def test4():
l = list(range(10))
print(l)
print('\n')
test1()
test2()
test3()
test4()[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。这个模块在工程开发中还是很有用的。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数。
from timeit import Timer
t1 = Timer("test1()", "from __main__ import test1")
print("concat ",t1.timeit(number=1000), "seconds")
t2 = Timer("test2()", "from __main__ import test2")
print("append ",t2.timeit(number=1000), "seconds")
t3 = Timer("test3()", "from __main__ import test3")
print("comprehension ",t3.timeit(number=1000), "seconds")
t4 = Timer("test4()", "from __main__ import test4")
print("list range ",t4.timeit(number=1000), "seconds")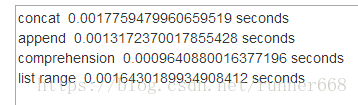
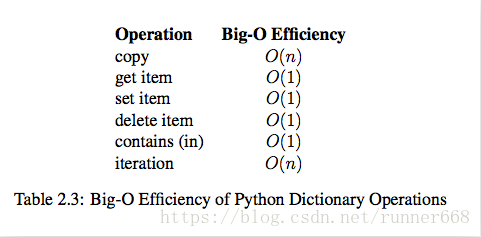
list内置操作的时间复杂度

dict内置操作的时间复杂度
二:python中的顺序表
Python中的list和tuple两种类型采用了顺序表的实现技术,具有前面讨论的顺序表的所有性质。
tuple是不可变类型,即不变的顺序表,因此不支持改变其内部状态的任何操作,而其他方面,则与list的性质类似。
list的基本实现技术
Python标准类型list就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作中维持已有元素的顺序(即保序),而且还具有以下行为特征:
基于下标(位置)的高效元素访问和更新,时间复杂度应该是O(1);
为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中。
允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变。
为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时list对象的标识id不变,只能采用分离式实现技术。
在Python的官方实现中,list就是一种采用分离式技术实现的动态顺序表。这就是为什么用list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在Python的官方实现中,list实现采用了如下的策略:在建立空表(或者很小的表)时,系统分配一块能容纳8个元素的存储区;在执行插入操作(insert或append)时,如果元素存储区满就换一块4倍大的存储区。但如果此时的表已经很大(目前的阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多空闲的存储位置。
一个顺序表的完整信息包括两部分,一部分是表中的元素集合,另一部分是为实现正确操作而需记录的信息,即有关表的整体情况的信息,这部分信息主要包括元素存储区的容量和当前表中已有的元素个数两项。
顺序表的两种基本实现方式
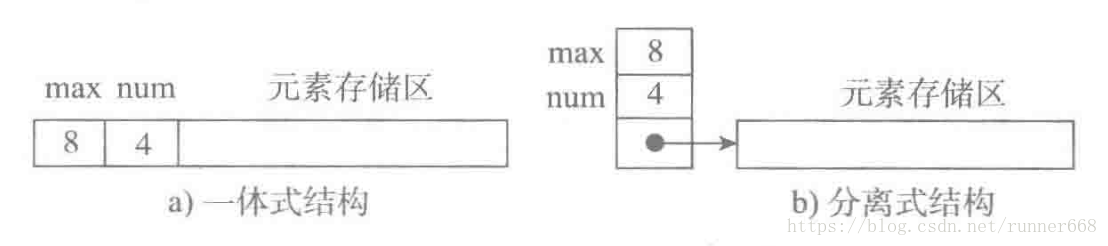
图a为一体式结构,存储表信息的单元与元素存储区以连续的方式安排在一块存储区里,两部分数据的整体形成一个完整的顺序表对象。
一体式结构整体性强,易于管理。但是由于数据元素存储区域是表对象的一部分,顺序表创建后,元素存储区就固定了。
图b为分离式结构,表对象里只保存与整个表有关的信息(即容量和元素个数),实际数据元素存放在另一个独立的元素存储区里,通过链接与基本表对象关联。
三:python中的链表


四:python中的栈与实现
class Stack(object):
"""栈"""
def __init__(self):
self.items = []
def is_empty(self):
"""判断是否为空"""
return self.items == []
def push(self, item):
"""加入元素"""
self.items.append(item)
def pop(self):
"""弹出元素"""
return self.items.pop()
def peek(self):
"""返回栈顶元素"""
return self.items[len(self.items)-1]
def size(self):
"""返回栈的大小"""
return len(self.items)
if __name__ == "__main__":
stack = Stack()
stack.push("hello")
stack.push("world")
stack.push("itcast")
print stack.size()
print stack.peek()
print stack.pop()
print stack.pop()
print stack.pop()可以栈的实现也是基于列表的,这里定义了一个类实现自身的初始化和常见的操作。
五:队列
队列的实现有点类似栈的实现,这里不写了。
六:二叉树
二叉树和链表一样,需要实现自己的业务节点。
通过使用Node类中定义三个属性,分别为elem本身的值,还有lchild左孩子和rchild右孩子
class Node(object):
"""节点类"""
def __init__(self, elem=-1, lchild=None, rchild=None):
self.elem = elem
self.lchild = lchild
self.rchild = rchild树的创建,创建一个树的类,并给一个root根节点,一开始为空,随后添加节点
class Tree(object):
"""树类"""
def __init__(self, root=None):
self.root = root
def add(self, elem):
"""为树添加节点"""
node = Node(elem)
#如果树是空的,则对根节点赋值
if self.root == None:
self.root = node
else:
queue = []
queue.append(self.root)
#对已有的节点进行层次遍历
while queue:
#弹出队列的第一个元素
cur = queue.pop(0)
if cur.lchild == None:
cur.lchild = node
return
elif cur.rchild == None:
cur.rchild = node
return
else:
#如果左右子树都不为空,加入队列继续判断
queue.append(cur.lchild)
queue.append(cur.rchild
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









