




 AMD的GI-1.0方案通过减少ScreenProbe更新次数,采用1/4固定生成策略和重投影技术,优化了性能。文章详细介绍了Probe生成、重投影策略、自适应算法、LRU存储和不同采样及滤波方法。
AMD的GI-1.0方案通过减少ScreenProbe更新次数,采用1/4固定生成策略和重投影技术,优化了性能。文章详细介绍了Probe生成、重投影策略、自适应算法、LRU存储和不同采样及滤波方法。
Screen Probe改进分析
Screen Probe Reuse(GI-1.0)
AMD提出的GI1.0内的Radiance Cacheing方案是在Lumen的Screen Probe方案上建立的,他的主要思想就是减少每帧更新的Screen Probe数量来达到优化性能的目的。
AMD Screen Probe
AMD的Screen Probe实际上就是在Lumen的基础上做的改进,重点说改进部分。
AMD Screen Probe采用的策略是每帧只更新原Lumen Screen Probe 1/4的Probe,其余的Probe尽可能通过复用上一帧的来补全,如果在上一帧找不到可复用的Probe,那缺失的Probe就在下一帧生成,这样不考虑额外过程带来的开销理论上可以提高4倍速度。
生成(Spawn Screen Probe)
下图可见,第一帧只生成1/4的Probe,第四帧才能得到全分辨率的信息。

AMD方案采用固定探针生成模式(Fixed probe spawing pattern)生成Probe,每个Tile会在四帧内每帧都通过低差异序列生成一个Probe,且每8×8Tile最多有8×8个Probe,每个Tile大小是8×8个Pixel且有生成Current Probe或者复用History Probe两种策略。下面为了方便表述我们把Tile称为格子

以四个Tile为一组,上面本应一每帧生成一组4个Probe,但现在每帧只能填一个,每帧生成Probe数量固定就是Lumen的1/4,坑位就这么多用完了就没有了,这帧内该组其他格子的Probe只能通过重投影或者下一帧再生成
这个方案导致人眼会看到屏幕光照从暗到亮的过程怕(因为Reprojection失败的Probe会延迟几帧生成)。
重投影(Reprojection Screen Probe)
AMD的方案可以利用Reprojection来避免大部分的Screen Probe的重新生成。
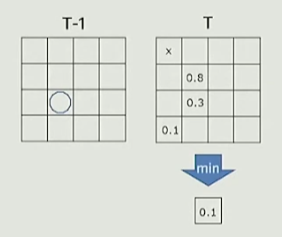
在Tile内生成Screen Probe的过程中,会同时生成上一帧对应的motion vector来对每个格子执行临时投影找到上一帧的位置,再根据距离、深度、法线和几何差异等因素评估对应位置附近History Probe和Current Probe的差异度来量化一个分数,分数(差异度)最小的History Probe信息直接被填充到Current Probe内,以此来减少开销。
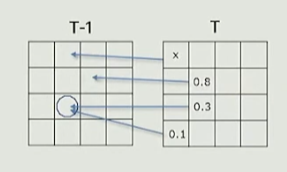
AMD的方案用32位整数前16位存储差异度信息,后十六位存储Local Data Share(存储同Tile多帧History Probe)内的索引
重投影的优化
交换队列自适应补洞
采用固定探针生成模式生成Probe的方式其实存在部分问题,当1/4的Probe生成完了,其余的Probe通过Reprojection获取,但Reprojection失败的Probe就只能等下一帧的1/4Probe了,而屏幕快速移动的时候有很大一部分Probe是找不到上一帧对应的,这就会造成只有1/4Probe能生成,其他位置出现大面积空缺。

原算法下1/4Probe是通过低差异序列固定位置生成的,这往往会出现一种个情况就是在这个位置生成的Probe其
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









