




大家好,我是十年码农大兵,目前是一位RPA定制开发者,计划帮忙开发并开源20个RPA机器人项目,如果您有rpa或相关自动化开发需求,欢迎发私信和我交流。
本次开源的RPA项目是:达人京东视频采集
需求描述
和上一期采集视频的方式不同,这次不需要京东app,使用影刀RPA打开浏览器访问指定京东视频达人的首页,通过浏览页面获取视频地址下载载视频到电脑,具体采集流程如下:
1、影刀rpa打开电脑上的浏览器,访问达人的视频首页
2、提取京东视频的地址打开视频链接提取商品购物地址及视频地址,视频进行下载保存到电脑指定目录
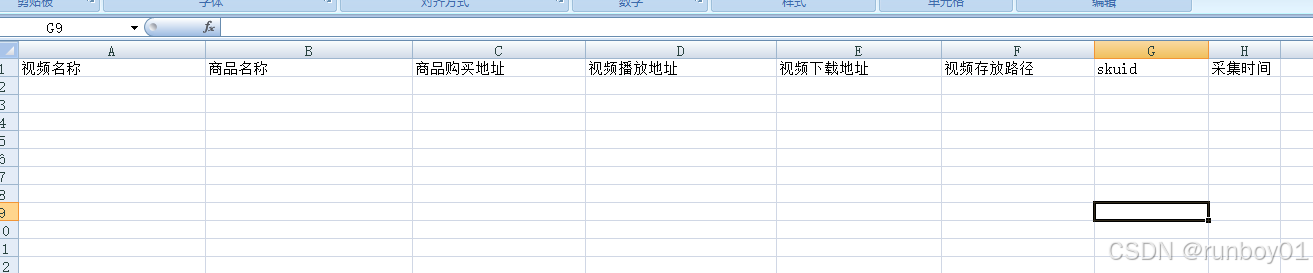
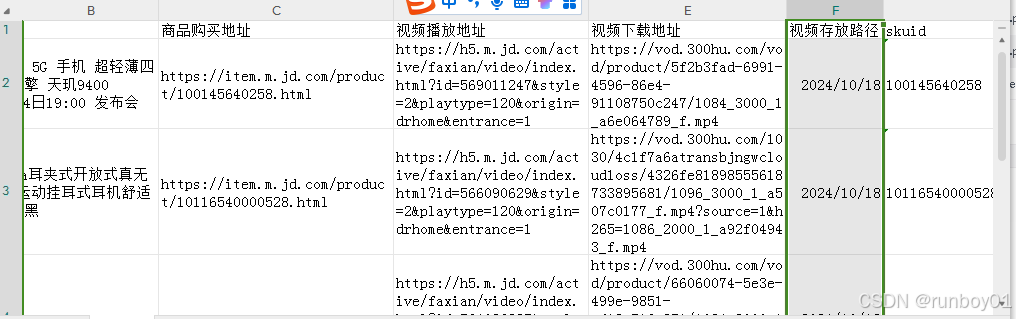
3、将提取的视频名称、商品名称、商品链接、商品suid、视频下载地址存至excel表格
开发环境:
软件:
影刀ShadowBot-5.20.22-x64.exe
设备:
浏览器:谷歌浏览器(需安装影刀插件)
excel模版(下载地址:https://download.youkuaiyun.com/download/runboy01/89900186)
软件安装部署可以点击参考我这篇文章
《京东短视频采集rpa相关软件安装部署使用文档》
应用获取地址:
京东短视频采集应用(获取应用需要使用创业版的账号):
https://api.winrobot360.com/redirect/robot/share?inviteKey=f8041e6683504a46
密码:vw#ios520888
建议使用我分享的这个应用,后续新增功能相关功能优化调整会优先同步到这个应用中,源码版更新会比较慢
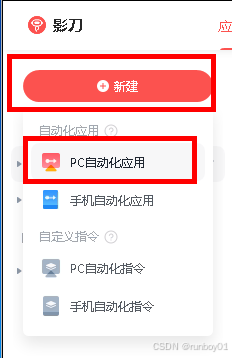
功能实现:
影刀新增应用

选择pc自动化
新建python模块


复制以下的源码到新建的python模块module1.py文件中
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
from xbot.mobile import appium
from xbot import excel
from datetime import datetime
import random
import os
from xbot import word
from xbot import web
import urllib.request
import shutil
import re
def sanitize_filename(filename):
"""
清理文件名中的特殊字符。
这里简单地用下划线替换了一些常见的特殊字符,你可以根据需要修改这个函数。
"""
# 注意:这个替换列表可能不完整,根据你的需要添加更多替换
return filename.replace('/', '_').replace('\\', '_').replace(':', '_').replace('?', '_').replace('*', '_').replace('"', '_').replace('<', '_').replace('>', '_').replace('|', '_')
def download(url,path,name):
if(name==''):
return
name = sanitize_filename(name)
filepath = os.path.join(path, name)
with urllib.request.urlopen(url) as response, open(filepath, 'wb') as out_file:
data = response.read() # 读取所有数据到内存(对于大文件可能不是最佳选择)
out_file.write(data) # 写入文件
def writeRow(worksheet,index,videoName,shopName,shopUrl,videoUrl,downloadUrl,videoPath):
# 获取当前时间
current_datetime = datetime.now()
shopId = parseShopId(shopUrl)
# 使用正确的格式字符串来格式化时间
formatted_datetime = current_datetime.strftime("%Y-%m-%d %H:%M:%S")
worksheet.set_cell(index, 'A', videoName)
worksheet.set_cell(index, 'B', shopName)
worksheet.set_cell(index, 'C', shopUrl)
worksheet.set_cell(index, 'D', videoUrl)
worksheet.set_cell(index, 'E', downloadUrl)
worksheet.set_cell(index, 'F', videoPath)
worksheet.set_cell(index, 'G', shopId)
worksheet.set_cell(index, 'H', formatted_datetime)
def getWebDrvideo(worksheet,index,downPath,videoUrl):
#videoUrl = 'https://3.cn/25-s97kU'
print("浏览器获取视频信息及下载视频")
videoPath = datetime.now().strftime("%Y-%m-%d")
browser = web.create(videoUrl, 'chrome', load_timeout=20)
sleep(5)
#html = browser.get_html()
#print(html)
web_element = browser.find_by_xpath('//video')
#print(web_element)
#print(web_element.get_attribute("src"))
downlodUrl = web_element.get_attribute("src")
web_element = browser.find_all_by_css('.shopbag-item-skutitle')
shopUrl = ''
shopName = ''
videoName = ''
shopUrl = ''
if(len(web_element)>0):
web_element = web_element[0]
shopName = web_element.get_text()
web_element = browser.find_all_by_css('.desc-videotitle')[0]
videoName = web_element.get_text()
web_element = browser.find_all_by_css('.shopbag-item-skutitle')[0]
web_element.click()
sleep(5)
shopUrl = browser.get_url()
shopId = parseShopId(shopUrl)
if(shopId == ''):
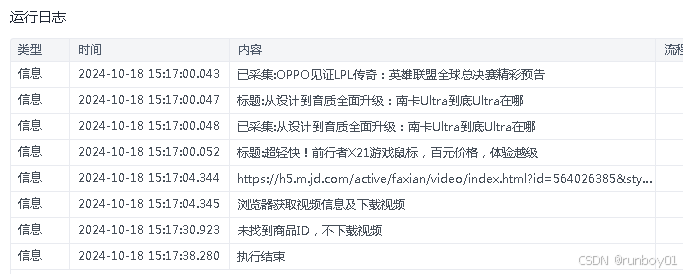
print("未找到商品ID,不下载视频")
if(shopId != ''):
print("采集视频:"+videoName)
download(downlodUrl,downPath,shopId+'_'+videoName+".mp4")
#download(downlodUrl,downPath,videoName+".mp4")
writeRow(worksheet,index,videoName,shopName,shopUrl,videoUrl,downlodUrl,videoPath)
browser.close()
sleep(3)
browser = web.get_active('chrome', load_timeout=20)
sleep(1)
browser.close()
def getWebvideo(worksheet,index,downPath,videoUrl):
#videoUrl = 'https://3.cn/25-s97kU'
print("浏览器获取视频信息及下载视频")
videoPath = datetime.now().strftime("%Y-%m-%d")
browser = web.create(videoUrl, 'chrome', load_timeout=20)
sleep(5)
#html = browser.get_html()
#print(html)
web_element = browser.find_by_xpath('//video')
#print(web_element)
#print(web_element.get_attribute("src"))
downlodUrl = web_element.get_attribute("src")
web_element = browser.find_all_by_css('.shopbag-item-skutitle')
shopUrl = ''
shopName = ''
videoName = ''
if(len(web_element)>0):
web_element = web_element[0]
shopName = web_element.get_text()
web_element = browser.find_all_by_css('.desc-videotitle')[0]
videoName = web_element.get_text()
web_element = browser.find_all_by_css('.shopbag-item-skutitle')[0]
web_element.click()
sleep(5)
shopUrl = browser.get_url()
shopId = parseShopId(shopUrl)
if(shopId == ''):
print("未找到商品ID")
return
print("采集视频:"+videoName)
download(downlodUrl,downPath,shopId+'_'+videoName+".mp4")
writeRow(worksheet,index,videoName,shopName,shopUrl,videoUrl,downlodUrl,videoPath)
browser.close()
def parseShopId(url):
product_id = ''
pattern = r"/product/(\d+)\.html"
# 使用re.search查找匹配项
match = re.search(pattern, url)
# 如果找到匹配项,则提取ID号
if match:
product_id = match.group(1)
return product_id
def writeLine(filepath,line):
line = line+'\n'
with open(filepath, 'a', encoding='utf-8') as file:
file.write(line)
def readLines(filepath):
lines = []
# 检查文件是否存在
if not os.path.exists(filepath):
# 如果文件不存在,则创建文件并写入0
with open(filepath, "w") as file:
file.write("")
else:
# 如果文件存在,则读取文件中的整数,将其设置为100,并写回文件
with open(filepath, 'r', encoding='utf-8') as file:
# 读取文件的所有行,并返回一个列表,其中每个元素是文件的一行(包含换行符)
lines = file.readlines()
# 可选:去除每行末尾的换行符和可能的空白字符
lines = [line.strip() for line in lines]
return lines
def getDrVideo(count,drid,worksheet,downPath):
okList = readLines(downPath+"\\"+drid+".txt")
url = 'https://eco.m.jd.com/content/dr_home/index.html?authorId='+drid
browser = web.create(url, 'chrome', load_timeout=20)
scrollPage(browser,count)
#browser.scroll_to(location='bottom', behavior='smooth')
sleep(2)
web_element = browser.find_all_by_css('.content-item-info-info-multiEllpsis')
global allIndex
allIndex = allIndex+1
for t in range(len(web_element)):
element = web_element[t]
title = element.get_text()
print("标题:"+title)
if(title in okList):
print("已采集:"+title)
continue
okList.append(title)
writeLine(downPath+"\\"+drid+".txt",title)
element.click()
sleep(3)
videoUrl = browser.get_url()
print(videoUrl)
index = t+2
try:
getWebDrvideo(worksheet,allIndex,downPath,videoUrl)
except Exception as e:
print("采集失败")
allIndex = allIndex-1
sleep(3)
break
def scrollPage(browser,count):
print("滑动"+str(count)+"次,到指定位置")
for i in range(count):
browser.scroll_to(location='bottom', behavior='smooth')
sleep(1)
allIndex = 1
def main(args):
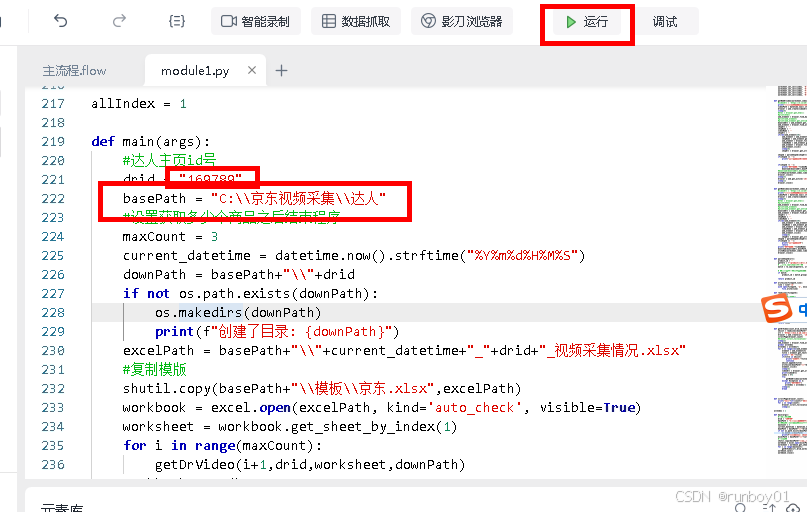
#达人主页id号
drid = "169789"
basePath = "C:\\京东视频采集\\达人"
#设置获取多少个商品之后结束程序
maxCount = 3
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
downPath = basePath+"\\"+drid
if not os.path.exists(downPath):
os.makedirs(downPath)
print(f"创建了目录: {downPath}")
excelPath = basePath+"\\"+current_datetime+"_"+drid+"_视频采集情况.xlsx"
#复制模版
shutil.copy(basePath+"\\模板\\京东.xlsx",excelPath)
workbook = excel.open(excelPath, kind='auto_check', visible=True)
worksheet = workbook.get_sheet_by_index(1)
for i in range(maxCount):
getDrVideo(i+1,drid,worksheet,downPath)
workbook.save()
workbook.close()
修改相关源码的要获取的京东达人id、视频存储路径、excel模板,点击运行

















 1895
1895



 到【灌水乐园】发言
到【灌水乐园】发言







