




本文要介绍的是 SIGMOD’25 最佳工业论文《Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases》。阿里云 PolarDB 团队基于 CXL 实现了 PolarDB 共享内存池,对比原有的 RDMA 方案实现了倍级性能提升。
背景
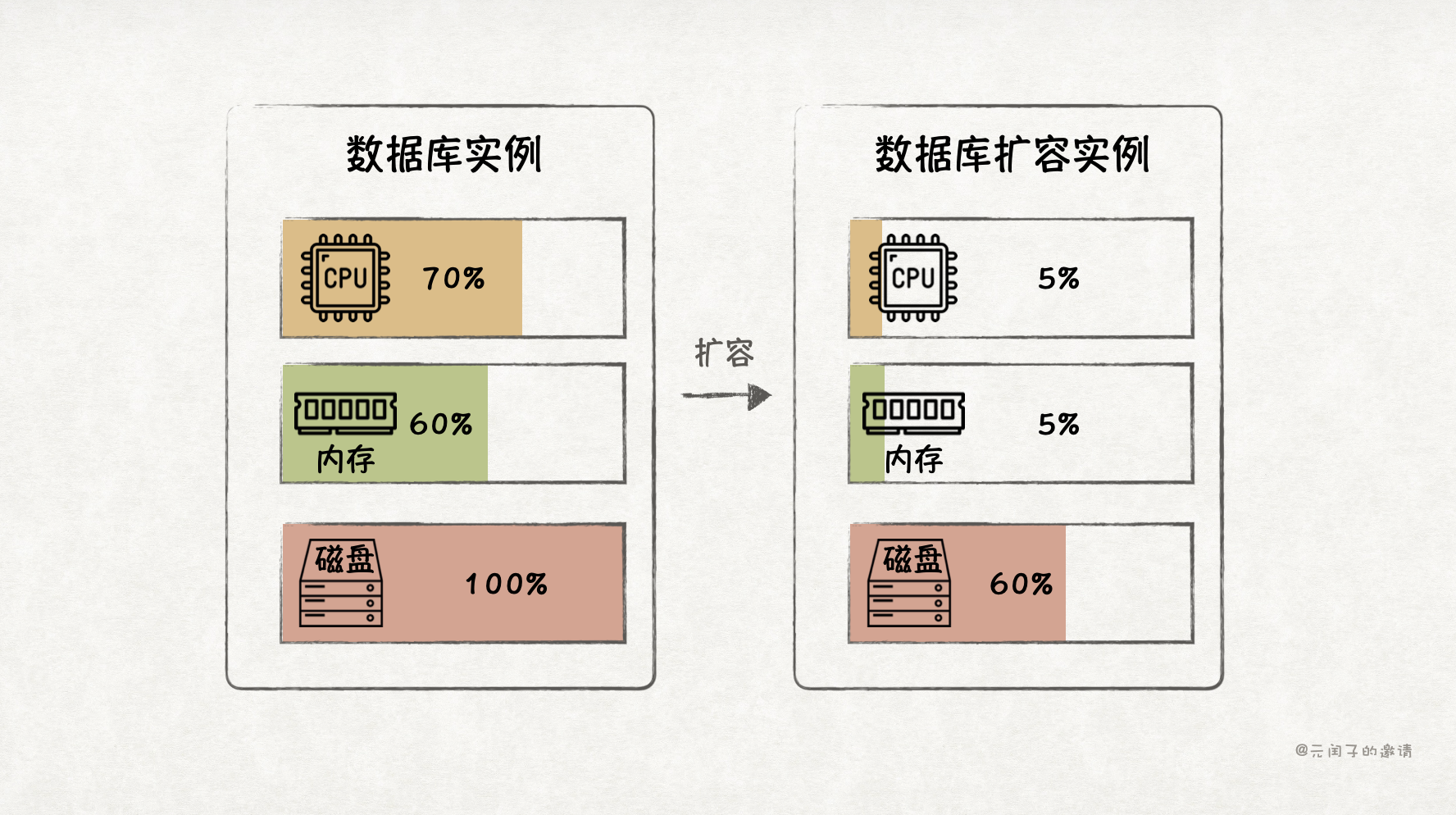
传统数据库是存算一体架构,如果要扩展资源,CPU 核、内存、存储必须一起扩,这带来了资源利用率低、成本高的问题。
比如,一台配置为 128 个 CPU 核 + 512 GB 内存 + 2 TB 存储的服务器上部署了一个数据库,业务高峰期只使用了 70% 的 CPU、60% 的内存,但存储已经接近 100%,必须再扩容一台服务器。这下,存储容量的问题解决了,但连带着增加了 CPU 和内存的成本,它们本无需扩容。
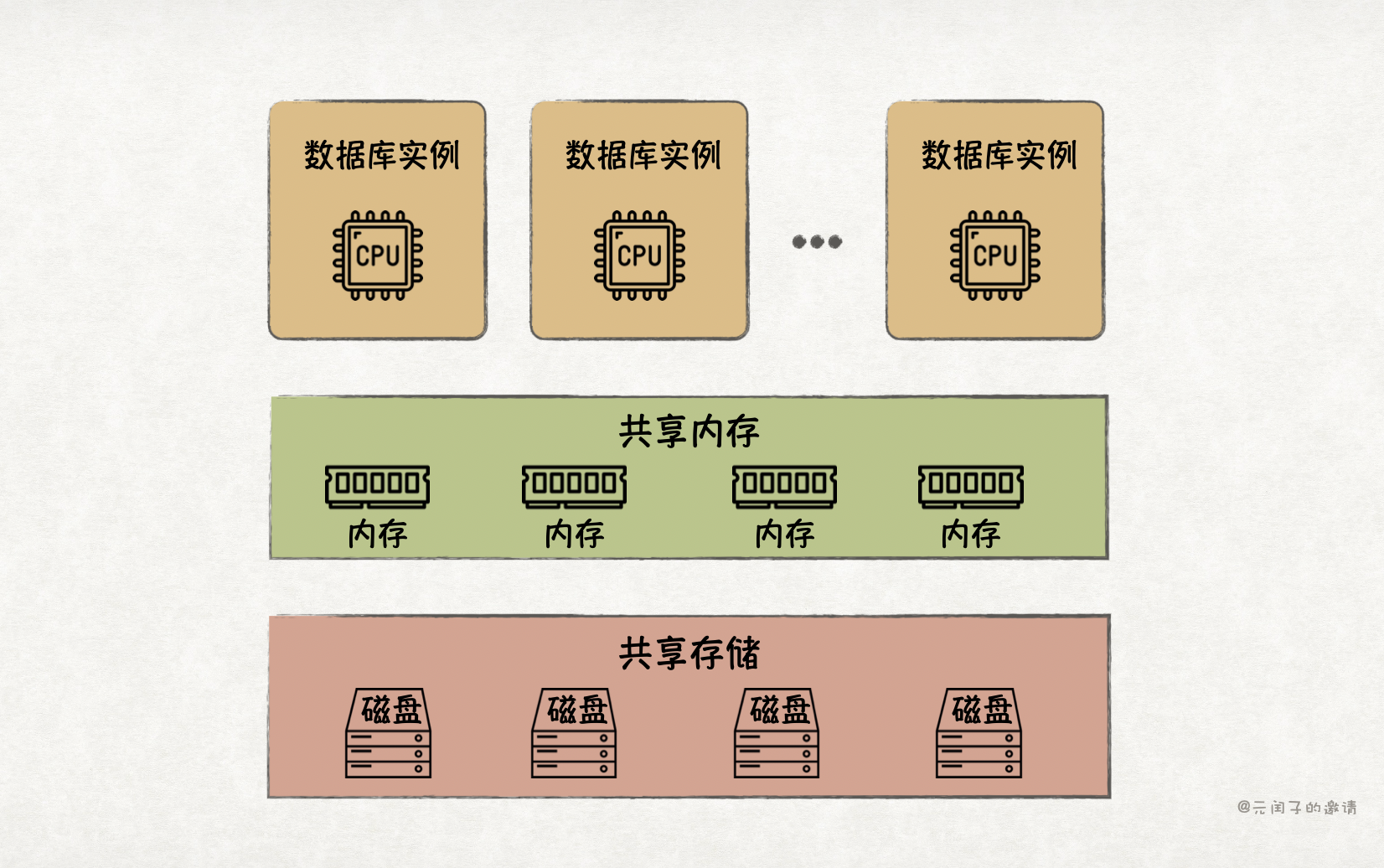
业界解决该问题的主要手段为分离和池化,也即云原生架构。
存储率先完成了分离。目前,存算分离已成为云原生数据库的主流架构,实现了低成本存储扩容。随着软硬件的发展,分离内存也逐渐流行了起来,旨在提升内存利用率。
数据库中,Buffer Pool 是内存消耗的大头,它将热数据缓存在内存里,能够有效提升数据库的读写性能。但受限于单机内存容量,Buffer Pool 无法做到很大,而且多节点间无法共享,限制了性能的进一步提升。有了内存分离技术,我们就能构建一个更大的全局共享 Buffer Pool,实现多写架构,提供更高的读写吞吐量。
分离就意味着远程通信,传统的 TCP/IP 通信方式存在用户态和内核态多次上下文切换和数据拷贝。虽然 DPDK 加速 TCP 能够实现内核旁路,但需要 CPU 在用户态轮训处理数据包、解析协议栈,效率仍是不高。
所以,目前数据库实现内存分离的主流技术方案是基于 RDMA 通信,绕过 CPU 实现远程内存读写。但基于 RDMA 实现共享内存池的方案也有它的局限。
RDMA 共享内存池的局限
(一)读写放大
虽然 RDMA 性能比 TCP 更高,但比起本地 DRAM 内存访问,还是差了不少。所以,现有的基于 RDMA 内存分离数据库通常会设置本地 Buffer Pool,作为远端内存池的近端缓存。
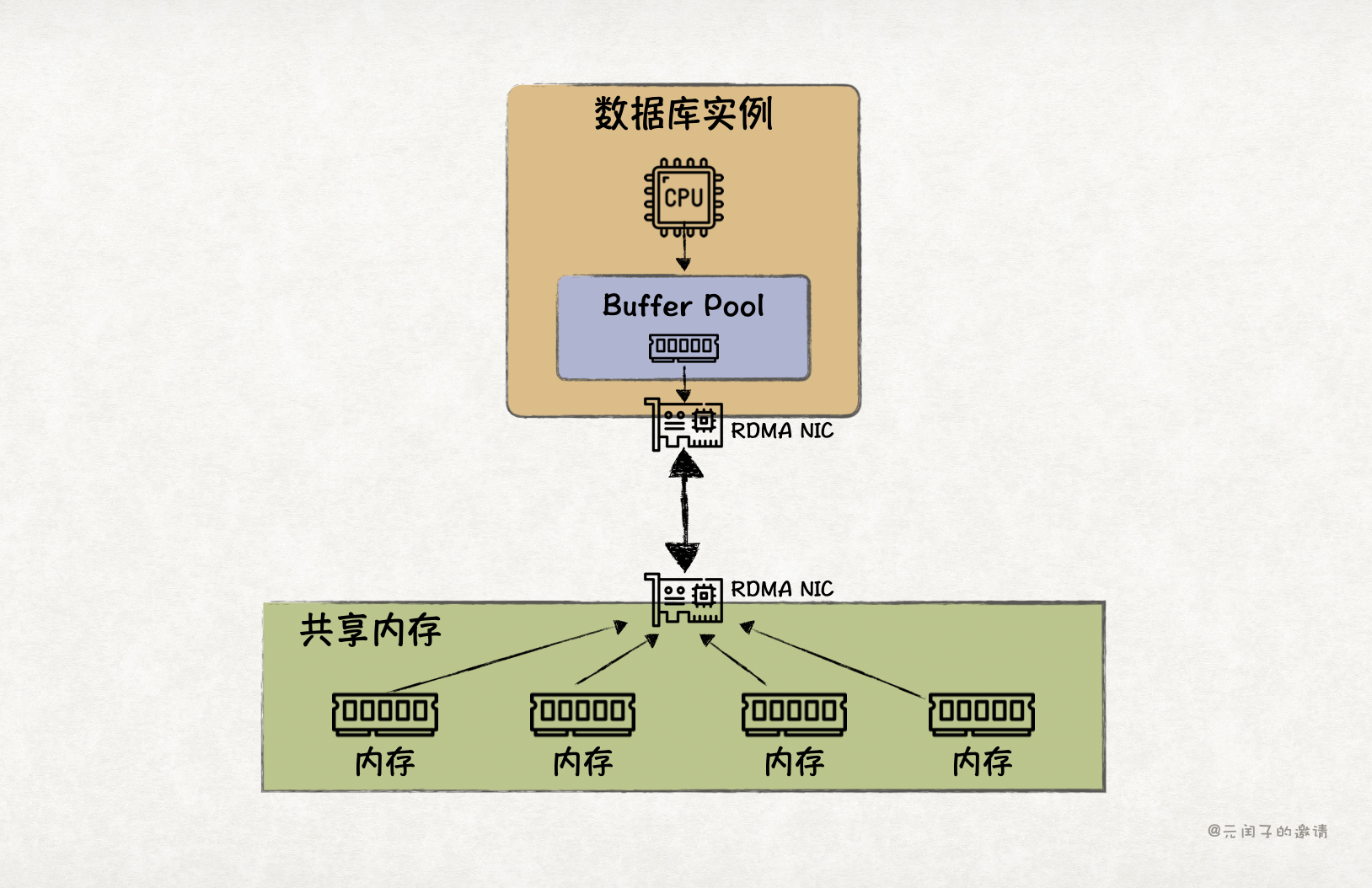
然而,RDMA 属于消息语义,数据库通过 RDMA 读取远端内存池时,会以 page 为粒度,从而带来读写放大的问题。
当本地 Buffer Pool 缓存缺失时,读取 page 中的某一行,需要从远端加载对应的 page 到本地;更新 page 中的某一行,需要先从远端把对应的 page 加载到本地,本地更新后,再将 page 写回到远端。带来了很多非必要的 RDMA 带宽浪费。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









