



 本文详细介绍了HDFS的Java API操作,包括创建、删除、列出、重命名和上传文件等,并深入解析了MapReduce的Shuffle过程,从切片、映射、溢写、排序到数据拉取,全面覆盖了大数据处理的关键环节。
本文详细介绍了HDFS的Java API操作,包括创建、删除、列出、重命名和上传文件等,并深入解析了MapReduce的Shuffle过程,从切片、映射、溢写、排序到数据拉取,全面覆盖了大数据处理的关键环节。
1 hdfs java API
new Configuration(true) 加载配置信息ture参数表示加载默认配置信息
FileSystem.get(conf) 获取FileSystem对象对hdfs文件系统进行操作
fs.mkdir(path) 创建文件路径
fs.delete(PATH,boolean) 删除路径 ture可以迭代删除
fs.listStatus(path) 路径下文件列表
fs.rename(path) 改名 or 更换路径
fs.create(path) 上传文件本地流 往hdfs的输出流上写操作
IOUtils.copyBytes(fis, fos, 1024); 专门进行读写操作的工具类 输入流 输出流 字节大小
fs.open(path) 打开文件 下载hdfs上的文件 hdfs输入流 本地输出流
fs.getFileStatus(path) 获取文件元数据
fs.getFileBlockLocations(fss,0 ,len ) 文件的元数据信息 字节起始位置 读取长度 获取在这个长度内数据在那个DN上的信息
FSDataInputStream.seek(0) 参数是字节偏移量 从0 到 字节末尾 即可读取整个文件
2 shuffle 大致过程
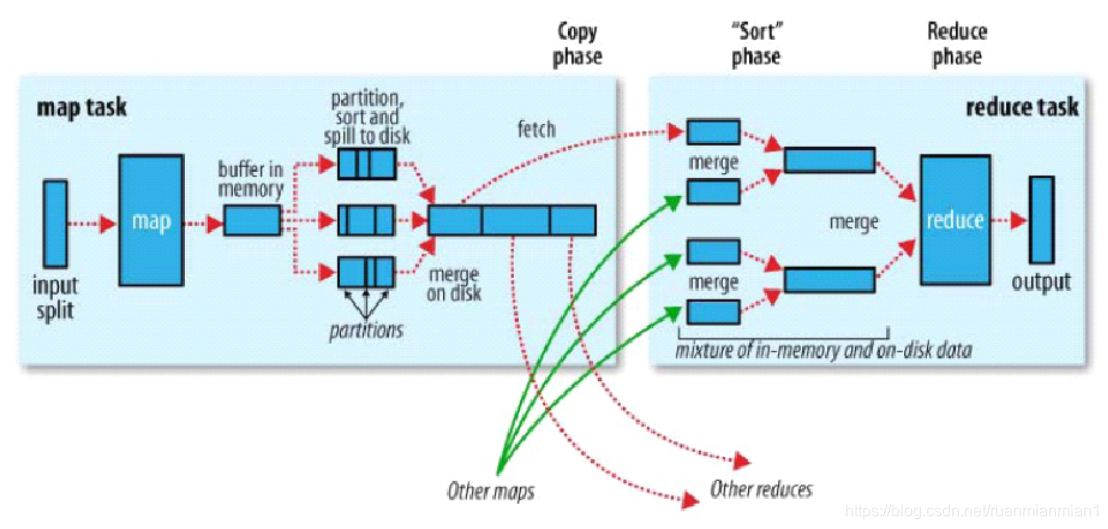
mr首先将文件进行逻辑切块(默认一个block是一块),一个切片对应一个map任务,map默认按行读取切片内容 按照kv形式发给map任务<"偏移量","字符串"> map进行计算 完成后 发给环形缓冲区 在缓冲区中计算分区编号(key的hash对reduce任务取模) 默认比例0.8 默认缓冲区100M 当环形缓冲区达到80M大小时 发生溢写 由内存写入到磁盘 在溢写的过程中 对分区编号进行排序 在每个分区内对key进行快速排序(字典排序) 如果溢写产生的小文件超过3个 则进行归并 归并后也是分区编号有序 分区内字典排序 当一个map处理完一个切片数据后 所有的reduce任务来该map的机器上 通过http get请求各自分区编号的数据
下载到reduce的本地 当所有的map处理完数据 reduce计算则开始

















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









