



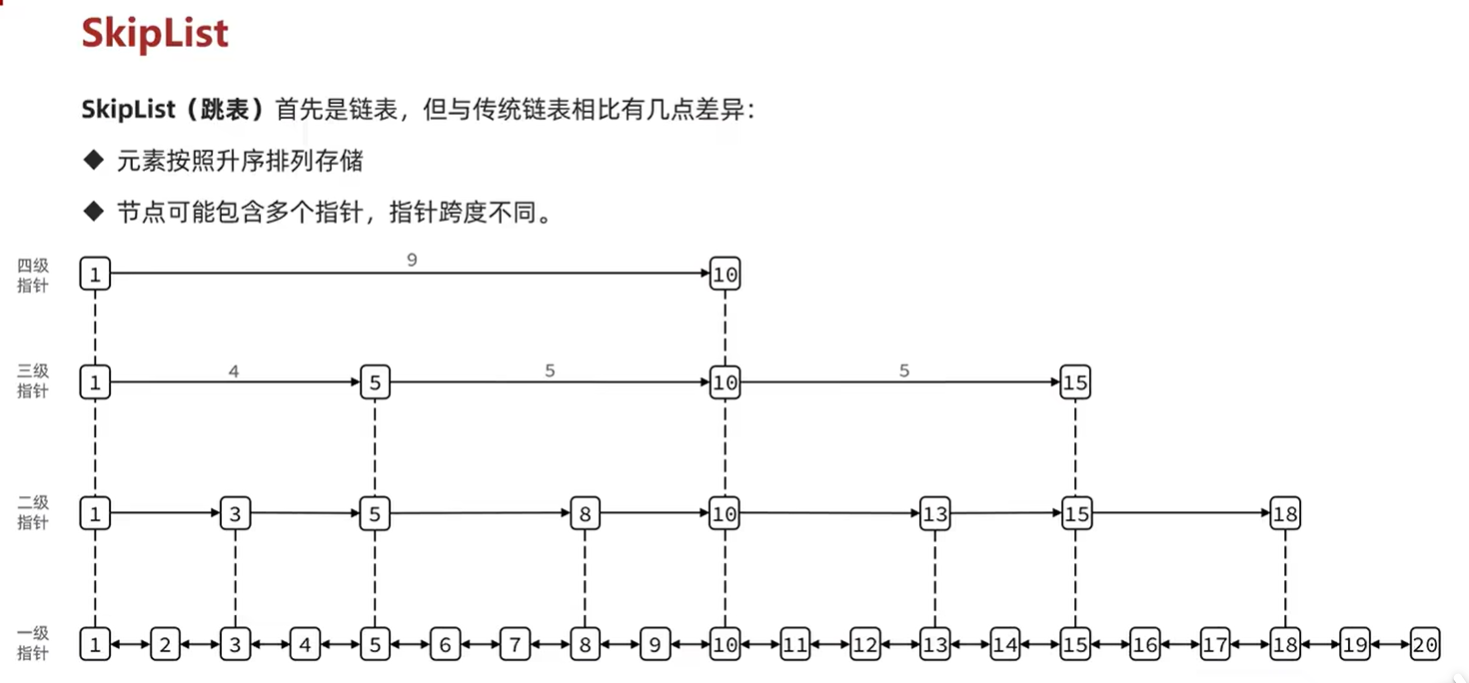
为什么使用跳跃表
首先,因为 zset 要支持随机的插入和删除,所以它 不宜使用数组来实现,关于排序问题,我们也很容易就想到 红黑树/ 平衡树 这样的树形结构,为什么 Redis 不使用这样一些结构呢?
- 性能考虑: 在高并发的情况下,树形结构需要执行一些类似于 rebalance 这样的可能涉及整棵树的操作,相对来说跳跃表的变化只涉及局部 (下面详细说);
- 实现考虑: 在复杂度与红黑树相同的情况下,跳跃表实现起来更简单,看起来也更加直观;
SkipList数据结构
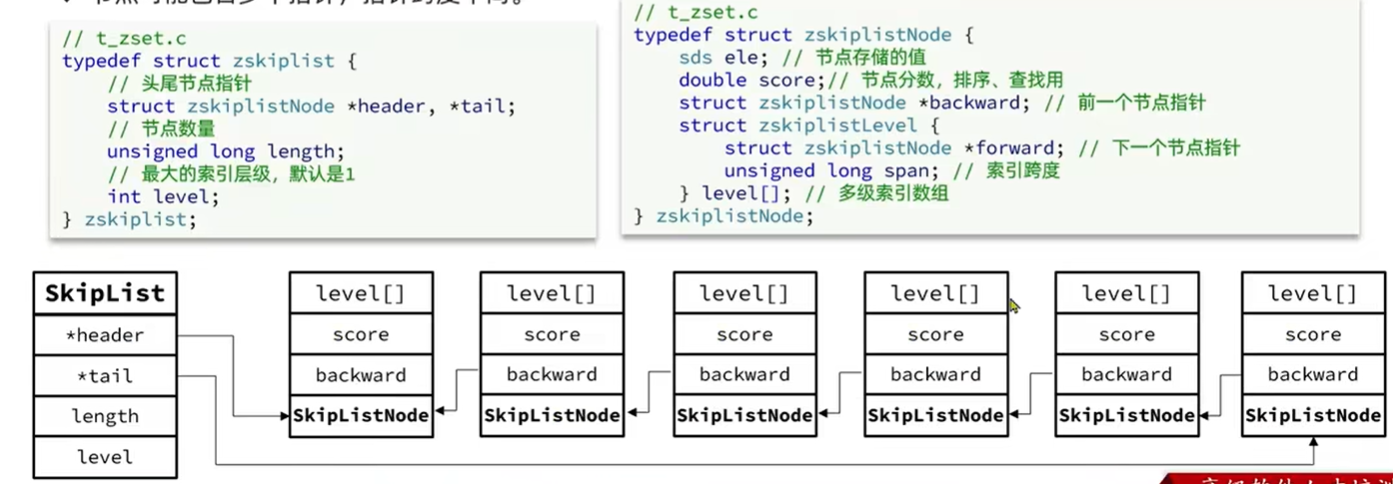
上图中展示了一个跳跃表示例,最左边的就是 zskiplist 结构,各个字段含义如下:
- Header:指向跳跃表的
表头节点。 - Tail:指向跳跃表的表尾节点。
- Level:记录目前跳跃表内,层数最大的那个节点的层数(除了头节点)。
- Length:记录跳跃表的长度,也就是跳跃表目前包含节点的数量(除了头节点)。
下面的是szkiplistNode
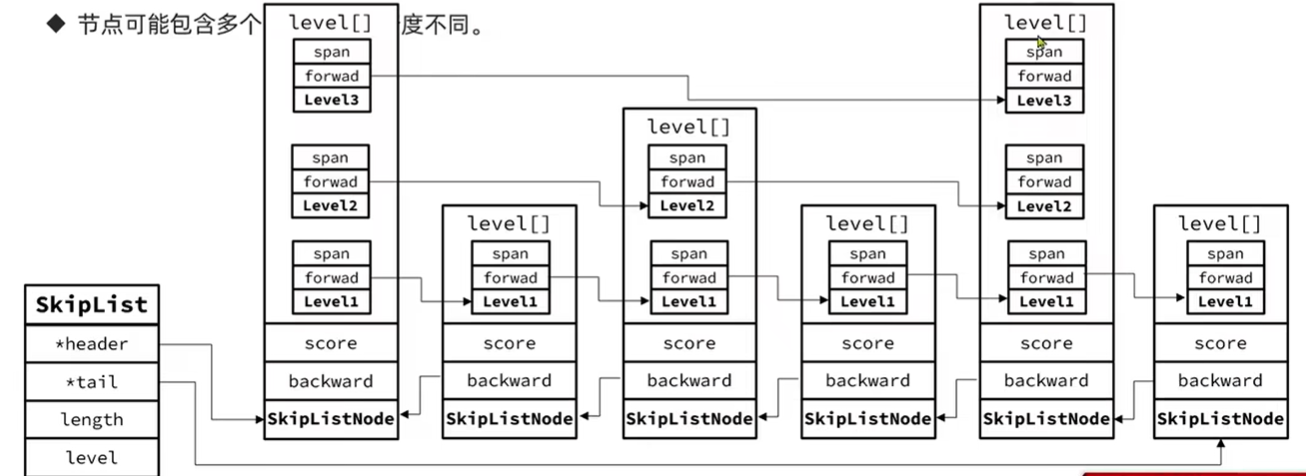
- 层(level):节点中用L1、L2、L3等字样标记节点的各个层,L1表示第一层,L2代表第二层,以此类推。每层都带有两个属性:前进指针和跨度。前进指针用于方位位于表尾方向的其他节点。而跨度则记录了前进指针所指向节点和当前节点的距离。
- backward:后退指针, 节点中用BW字样标记的后退指针 ,他指向当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
- score:分值,各个节点中的 1.0、2.0、3.0 是节点所保存的分值。节点会按各个所保存的分值从小到大排序。
- obj:成员对象,各个节点中的o1,o2 和 o3 是节点所保存的成员对象。
查找流程
假设有是个SkipListNode
-
从最顶层开始扫描(Level3)
- 从头节点
header出发,沿当前层级level[3]->forward指针移动 - 遇到Score=1节点:
1<10符合条件,继续前进 - 到达Score=9节点:
9<10仍符合条件 - 但下一节点为NULL → 触发降层逻辑
- 从头节点
-
降级到Level2层
- 切换到Score=9节点的Level2指针
- 沿
level[2]->forward指针移动 - 立即到达Score=10节点:
10==10找到目标!
-
跨度过桥作用
- 图中
span字段记录每个指针的跨越距离 - Level3层从1→9的指针,对应
span=8(跳过2-8号共8个点) - 这是跳表提速的关键:不用逐一遍历!
- 图中
与传统链表对比
| 操作 | 跳表路径 | 普通链表路径 |
|---|---|---|
| 访问节点数 | 1→9→10 (3个) | 1→2→3→...→10 |
| 比较次数 | 3次 | 10次 |
| 时间复杂度 | O(log n) | O(n) |

















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









