






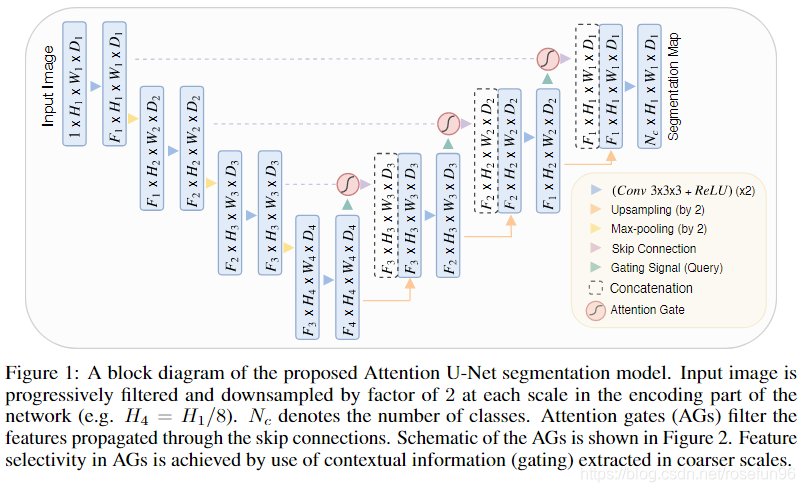
1 理论
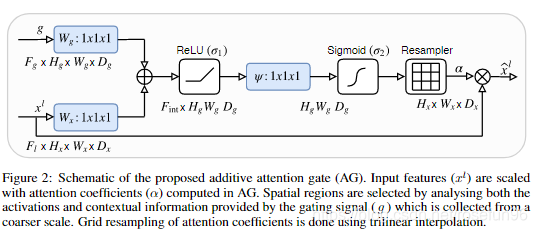
其中,g就是解码部分的矩阵,xl是编码(左边)的矩阵,x经过乘于系数(完成Attention)和g一起concat,进入下一层解码。
这里,Resampler重采样器把特征图重采样到的原来
x
l
x^l
xl 大小,实践2里边的代码中,
H
g
H_g
Hg 和
H
x
H_x
Hx相等,即不对特征图的 H、W、D改变,所以没有Resample 操作。
数学公式:
q a t t l = ψ T ( σ 1 ( W x T x i l + W g T g i + b g ) ) + b ψ α i l = σ 2 ( q a t t l ( x i l , g i ; Θ a t t ) ) \begin{aligned} q_{a t t}^{l}=& \psi^{T}\left(\sigma_{1}\left(W_{x}^{T} x_{i}^{l}+W_{g}^{T} g_{i}+b_{g}\right)\right)+b_{\psi} \\ & \alpha_{i}^{l}=\sigma_{2}\left(q_{a t t}^{l}\left(x_{i}^{l}, g_{i} ; \Theta_{a t t}\right)\right) \end{aligned} qattl=ψT(σ1(WxTxil+WgTgi+bg))+bψαil=σ2(qattl(xil,gi;Θatt))
个人理解这里的Attention:
g,
x
l
x^l
xl 都在channel通道数量发生变化,从
F
g
F_g
Fg 到
F
i
n
t
F_{int}
Fint 再到 1,这过程
g
g
g 和
x
l
x^l
xl分别和权重矩阵相乘,权重矩阵可以通过反向传播学习(alpha矩阵是其中的一个权重矩阵),获得
g
g
g,
x
l
x^l
xl每个元素的重要度,这个重要度是根据我们的目标来学习出来的。也就是我们引入Attention(增加alpha等权重矩阵)来学习到各个元素与目标之间的重要度。
2 实践
Pytorch Attention Unet:
class Attention_block(nn.Module):
def __init__(self,F_g,F_l,F_int):
super(Attention_block,self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1,stride=1,padding=0,bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self,g,x):
# 下采样的gating signal 卷积
g1 = self.W_g(g)
# 上采样的 l 卷积
x1 = self.W_x(x)
# concat + relu
psi = self.relu(g1+x1)
# channel 减为1,并Sigmoid,得到权重矩阵
psi = self.psi(psi)
# 返回加权的 x
return x*psi
Attention-Unet:
class AttU_Net(nn.Module):
def __init__(self,img_ch=3,output_ch=1):
super(AttU_Net,self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2)
self.Conv1 = conv_block(ch_in=img_ch,ch_out=64)
self.Conv2 = conv_block(ch_in=64,ch_out=128)
self.Conv3 = conv_block(ch_in=128,ch_out=256)
self.Conv4 = conv_block(ch_in=256,ch_out=512)
self.Conv5 = conv_block(ch_in=512,ch_out=1024)
self.Up5 = up_conv(ch_in=1024,ch_out=512)
self.Att5 = Attention_block(F_g=512,F_l=512,F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512,ch_out=256)
self.Att4 = Attention_block(F_g=256,F_l=256,F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256,ch_out=128)
self.Att3 = Attention_block(F_g=128,F_l=128,F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128,ch_out=64)
self.Att2 = Attention_block(F_g=64,F_l=64,F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0)
def forward(self,x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5,x=x4)
d5 = torch.cat((x4,d5),dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4,x=x3)
d4 = torch.cat((x3,d4),dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3,x=x2)
d3 = torch.cat((x2,d3),dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2,x=x1)
d2 = torch.cat((x1,d2),dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
numpy 版本理解:
import numpy as np
# channel = 1
a = np.array([[1,1,0],[0,1,0],[1,1,1]])
b = np.array([[1,0,0],[0,1,0],[1,0,1]])
import torch
#m = nn.Sigmoid()
#print(m(torch.from_numpy(a).float()))
n_dim = 2
w1 = np.random.normal(0, 1, (a.shape[0],n_dim))
w2 = np.random.normal(0, 1, (b.shape[0],n_dim))
# Resample 到原来维度
w3 = np.random.normal(0, 1, (n_dim,a.shape[0]))
def relu(x):
return x*(x>0)
def sigmoid(x):
return 1/(1+ np.exp(-x))
# Add, Resample
res = np.matmul((np.matmul(a,w1) + np.matmul(b,w2)),w3)
# Relu
resRelu = relu(res)
# Sigmoid
resSigmoid= sigmoid(resRelu)
final = a*resSigmoid
print('a:\n', a)
print('\nb\n',b)
print('resSigmoid\n', resSigmoid)
print('\n final a:\n',final)
输出:
a:
[[1 1 0]
[0 1 0]
[1 1 1]]
b
[[1 0 0]
[0 1 0]
[1 0 1]]
resSigmoid
[[0.5 0.9731015 0.5 ]
[0.5 0.98390734 0.75471665]
[0.94915347 0.66973461 0.5 ]]
final a:
[[0.5 0.9731015 0. ]
[0. 0.98390734 0. ]
[0.94915347 0.66973461 0.5 ]]
这里,可以看出,Attention的作用就是调整权重。
为什么可以调整权重呢?
感觉是两个输入 a, b都得和一个矩阵
w
1
,
w
2
w1, w2
w1,w2 相乘,最终,
w
1
,
w
2
w1, w2
w1,w2通过反向传播学习,
w
1
,
w
2
w1,w2
w1,w2起到调整 a, b各元素向前传播的比例。
3 疑问与理解
使用两个矩阵相乘,第一次相乘是,g,x之间的权重分配,第二次相乘是,每个像素的权重分配。
最近开通了个公众号,主要分享计算机视觉,推荐系统,风控等算法相关的内容,感兴趣的伙伴可以关注下。

公众号相关的学习资料会上传到QQ群596506387,欢迎关注。
参考:


















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











