




RAGAS 自动化测评后端设计方案
Ragas是什么 Reasoning-Aware Generative Agents
结合Dify构建一套可扩展的评测框架
设计文档
流程图
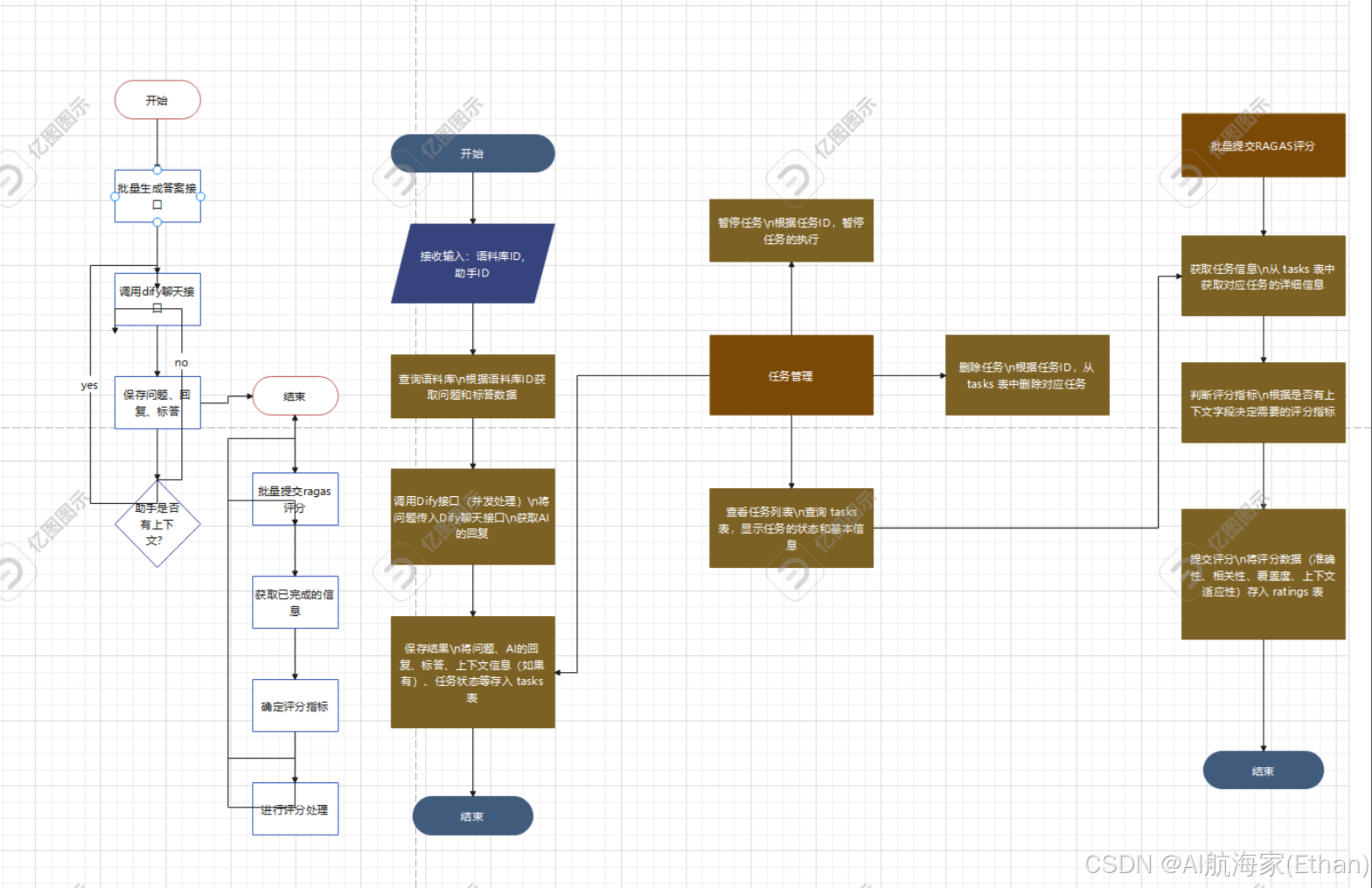
系统概述
系统包括两个主要功能模块:
表结构
-
任务表 (
tasks)- 用于存储批量生成答案的任务信息。
字段名 数据类型 说明 id INT 任务唯一标识(主键,自增) corpus_id VARCHAR 语料库 ID,可能是多个,用逗号分隔 assistant_id VARCHAR 助手 ID question TEXT 问题 answer TEXT AI 回复 ground_truths TEXT 标答 contexts TEXT 引用 has_context INT 是 1 否 0 有上下文 status INT 任务状态(例如“处理中 0”,“完成 1”,“失败 2”等) created_at TIMESTAMP 任务创建时间 completed_at TIMESTAMP 任务完成时间 is_del INT 是 1 否 0 删除(默认 0) is_suspend INT 是 1 否 0 暂停(默认 0) action_time TIMESTAMP 操作时间
- 用于存储批量生成答案的任务信息。
-
评分表 (
ratings)- 用于存储批量提交的 RAGAS 评分数据。

















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









