






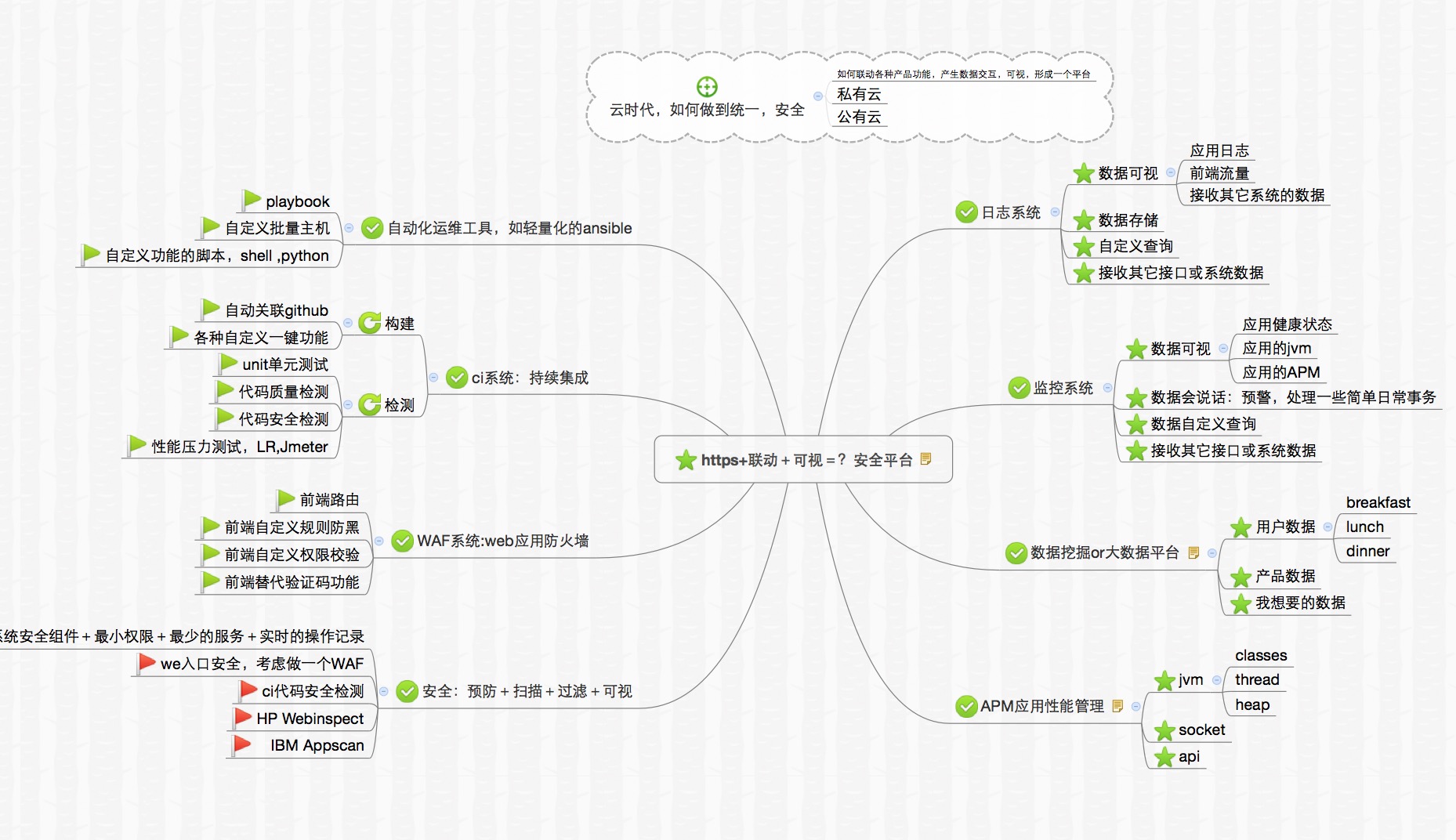

1.通过日志的异常数据判断服务稳定性 -> APM
技术方式:
通过es的api统计应用err数存于apm并展示
curl -XGET 'http://ip:port/index/type/_search?pretty=1?q=message:AVPl-6ql_WySByDbTeq9'
搜索关键字为AVPl-6ql_WySByDbTeq9,并格式化输出
, {
"_index" : "mobile_info",
"_type" : "mobile-info",
"_id" : "AVPl-6hZ_WySByDbTep8",
"_score" : 1.0,
"_source":{"@timestamp":"2016-04-05T10:33:06.965Z","message":"18:33:06 DEBUG
2.通过APM的连接数、消息数、HTTP请求成功率判断服务的稳定性
-> APM
技术方式:
graphite的api获取连接数,消息数已有,(HTTP请求成功率目前grafana没有现成的功能,还要再次计算存入graphite)
写一段python或curl 获取存于graphite时间序列的 数据:
graphite.py["averageSeries(stats.timers.admin.admin.system-metric.jmx-memory.heap-used.mean)"]
3.日志和APM的监控-
> monitor
技术方式:
单元与集成监控相结合的方式。
单元监控是指监控每个节点的状态,分两步来做,第一步是判断应用是否存活;第二步判断各节点是否假死状态,通过异常关键字(error,exception),某些key的数量进行量化判断。
集成监控是指,从展示端取某个key,通过key是否返回对应的数据来判断整条链数是否正
(ps:日志系统第一步各单元监控已完成)
4.和CI关联并自动化?
技术方式:
1.web插件方式。通过插件形式和ci关联,plugin取值于apm并根据数据设置相关状态色(红色表示异常,绿色表示健康),起到提示的效果,发布完,从原先单一http状态码检查,多维度深度查看应用活动状态。
2. 独立应用方式。通过notify进行通信,再进行跳转。
3.ci上执行命令,远程从apm抓数据
5.ci与waf关联
技术方式:lua+nginx+es+ci
集成lua到nginx,把nginx重建成一个应用服务器,用户所有行业数据按一定规则存入es,从流量分析,ci发布是否正常,流量过大或过小都说明版本有问题。
总结:高度集成化,再细分每一条警报的规则,做到出了问题,一看报表图,就马上定位异常的位置与原因。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









