







 本教程详细讲解如何在Keras中构建LSTM网络,用于文本预测模型。涵盖循环神经网络、LSTM原理、Keras LSTM架构、模型构建、数据生成器创建等关键步骤。通过PTB语料库进行实践,解决梯度消失问题。
本教程详细讲解如何在Keras中构建LSTM网络,用于文本预测模型。涵盖循环神经网络、LSTM原理、Keras LSTM架构、模型构建、数据生成器创建等关键步骤。通过PTB语料库进行实践,解决梯度消失问题。
**本文更完整的内容请参考极客教程的深度学习专栏:https://geek-docs.com/deep-learning/rnn/keras-lstm-tutorial.html,欢迎提出您的宝贵意见。感谢。
文章目录
1 循环神经网络
2 LSTM网络
3 LSTM字嵌入和隐藏层大小
4 Keras LSTM架构
5 构建Keras LSTM模型
6 创建Keras LSTM数据生成器
7 创建Keras LSTM结构
8 编译并运行Keras LSTM模型
9 Keras LSTM结果
Keras LSTM教程,在本教程中,我将集中精力在Keras中创建LSTM网络,简要介绍LSTM的工作原理。在这个Keras LSTM教程中,我们将利用一个称为PTB语料库的大型文本数据集来实现序列到序列的文本预测模型。本教程中的所有代码都可以在此站点的Github存储库中找到。
循环神经网络
LSTM网络是一种循环神经网络。循环神经网络是一种神经网络,它试图对依赖于时间或顺序的行为(如语言、股价、电力需求等)进行建模。这是通过将神经网络层在t时刻的输出反馈给同一网络层在t + 1时刻的输入来实现的。它是这样的:
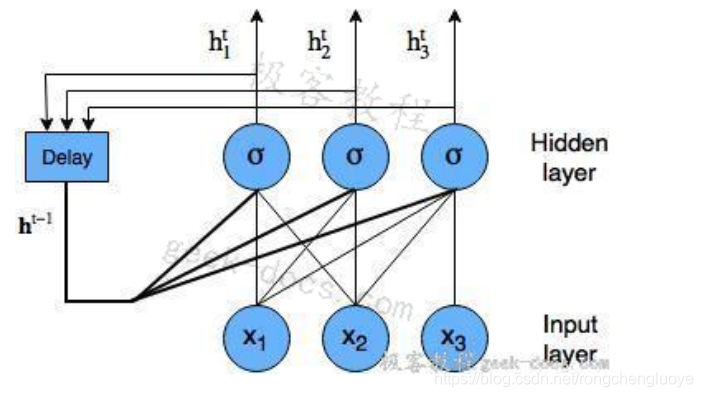
带节点的循环神经网络图
在训练和预测过程中,循环神经网络以编程方式“展开”,得到如下结果:
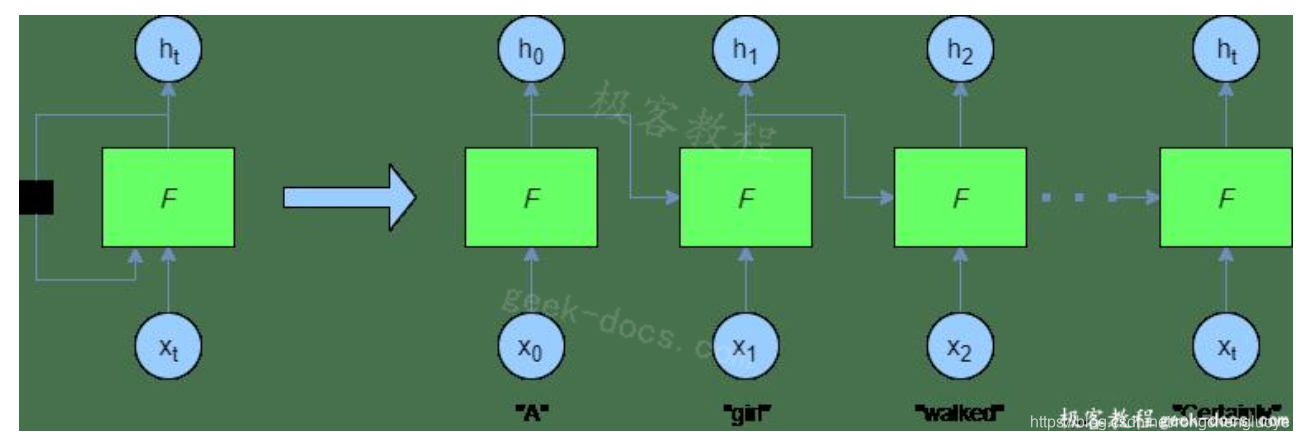
在这里,您可以看到,在每个时间步骤中,都提供了一个新单词——前一个F(即 h t − 1 h_{t-1} ht−1)的输出也在每个时间步骤中提供给网络。
vanilla 循环神经网络(由常规神经网络节点构造)的问题在于,当我们尝试对由大量其他单词分隔的单词或序列值之间的依赖关系建模时,我们体验到了梯度消失问题(有时也是梯度爆炸问题)。这是因为小梯度或权重(小于 1 的值)在多个时间步长中乘以多次,并且梯度以不相通方式收缩为零。这意味着这些早期图层的权重不会显著更改,因此网络不会学习长期依赖关系。
LSTM网络是解决这一问题的一种方法。
LSTM网络
如前所述,在这个Keras LSTM教程中,我们将构建一个用于文本预测的LSTM网络。LSTM网络是一个循环神经网络,它用LSTM细胞块来代替我们的标准神经网络层。这些单元格有不同的组成部分,称为输入门、遗忘门和输出门——这些将在稍后详细解释。以下是LSTM单元格的图形表示:
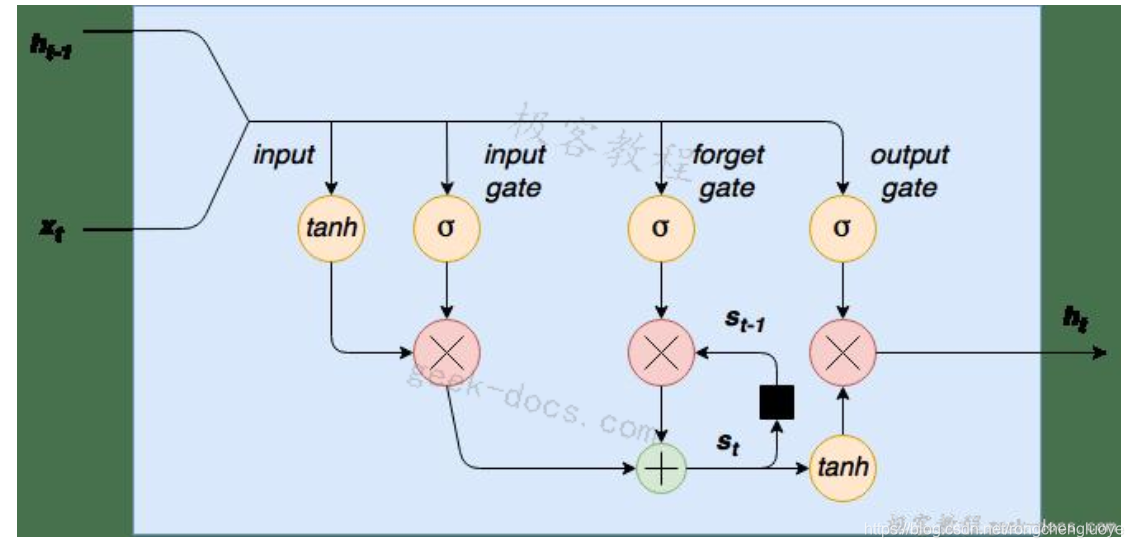
LSTM细胞图
首先请注意,在左侧,我们将新单词/序列值 x t x_t xt连接到单元格 h t − 1 h_{t-1} ht−1的前一个输出。这个组合输入的第一步是通过tanh层进行压缩。第二步是这个输入通过一个输入门。输入门是一层sigmoid激活节点,其输出乘以压扁的输入。这些输入门sigmoid可以“杀死”输入向量中不需要的任何元素。一个sigmoid函数输出0到1之间的值,因此可以将连接到这些节点的输入的权重训练为接近于零的输出值来“关闭”某些输入值(或者相反,接近于1的输出值来“传递”其他值)。
通过此单元格的数据流的下一步是内部状态/遗忘门循环。LSTM细胞有一个内部状态变量 s t s_t st。这个变量,滞后一个时间步长,即 s t − 1 s_{t-1} st−1被添加到输入数据中,创建一个有效的递归层。这个加法运算,而不是乘法运算,有助于降低梯度消失的风险。然而,这个递归循环是由遗忘门控制的——它的工作原理与输入门相同,但是它帮助网络学习哪些状态变量应该“记住”或“忘记”。
最后,我们有一个输出层tanh压扁函数,它的输出由一个输出门控制。这个门决定哪些值实际上可以作为单元格 h t h_t ht的输出。
LSTM细胞的数学是这样的:
输入
首先,使用tanh激活函数将输入压缩到-1和1之间。这可以表示为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









