




 本文详细介绍了MIT-6.824课程中的MapReduce实验实现,包括map和reduce过程,中间文件处理,排序,reduce操作及故障恢复机制,实现了完整的MapReduce流程。
本文详细介绍了MIT-6.824课程中的MapReduce实验实现,包括map和reduce过程,中间文件处理,排序,reduce操作及故障恢复机制,实现了完整的MapReduce流程。
一步一步完成 MIT-6.824-Lab1 : MapReduce 之三
GitHub代码仓库:Mit-6.824-Lab1-MapReduce
接上文
一步一步完成 MIT-6.824-Lab1 : MapReduce 之二
步骤四
目标
定期的,这些内存中的中间值会经过一个用户自定义的 Partition 分割函数,分成 N 份,(即 reduce task 的数量)。然后写到本地的磁盘中。这些文件的存放位置需要发送给 Master, 以保证能够被正确找到,进行 reduce 任务。
我们的实现
中间值经过 Partition 函数,分成N份
紧接着步骤三,此处,我们介绍步骤三里提到的 worker 处理 map 任务需要用到的 Partition 函数:
// Partition : divide intermedia keyvalue pairs into nReduce buckets
func Partition(kva []KeyValue, nReduce int) [][]KeyValue {
kvas := make([][]KeyValue,nReduce)
for _,kv := range kva {
v := ihash(kv.Key) % nReduce
kvas[v] = append(kvas[v], kv)
}
return kvas
}
参数是中间值和 reduce 任务的数量。将中间值的 key 通过 hash 函数来分割,分成N份。对应到 n 个 reduce 任务。
将中间值写入到本地磁盘。
官网上提到,建议使用json格式存放中间值,文件名称也有规定。在用户处理 map 任务的函数中,通过 WriteToJSONFile 函数将分割后的中间值写入到本地磁盘:
// WriteToJSONFile : write intermediate KeyValue pairs to a Json file
func WriteToJSONFile(intermediate []KeyValue, mapTaskNum, reduceTaskNUm int) string {
filename := "mr-"+strconv.Itoa(mapTaskNum)+"-"+strconv.Itoa(reduceTaskNUm)
jfile, _ := os.Create(filename)
enc := json.NewEncoder(jfile)
for _, kv := range intermediate {
err := enc.Encode(&kv)
if(err != nil) {
log.Fatal("error: ",err)
}
}
return filename
}
参数1是某个分割的中间值的某一项,也就是用于某一个 reduce 任务执行的一项数据。参数2代表本 map 任务的编号。这个编号是由 master 分配的。参数3是代表这一项分割后的数据,适用于的 reduce 任务的编号。这样,在函数内部生产文件,将内容写入文件,返回中间文件名。此处,我们使用的文件名代表文件的 location ,因为本实验的 worker 都是在一台计算机上运行的。
将中间文件location发送给master
通过使用我们之前写好的 SendInterFiles 的调用,调用 master 提供的 RPC 接口,消息类型就为 MsgForInterFileLoc。将中间文件名,该中间文件适用的 reduce 任务的编号发送给 master。
通知master,该任务完成
最后,worker在完成任务后,需要发送消息给 mster 以告知我以完成本任务。这样,master 方便修改任务的状态为 Finished 。
完成map过程
这样,配合我们之前完成的代码,我们即可完成 worker 的 map 部分。
步骤五
目标
当一个 worker 被分配了 reduce 任务后,通过远程程序调用,读取 map worker 存放在其本地的中间文件。当读取了所有的中间值后,reduce worker 对中间值按照键值对的 key 进行排序。 如果中间值太大以至于内存容纳不下,那么,一个可能就需要一个外部的排序。
我们的实现
这里,我们开始完成 worker 的 reduce 部分。
上面的步骤,已经完成了 map 部分的处理。然后,我们在 master 上生产任务时的设计是,只有所有的 map 任务执行完成后,才会开始生产 reduce 任务。我们这个设计也正是我们所需要的。
接下来就是对 reduce 的处理:
// reduceInWroker : workers do the reduce phase
func reduceInWorker(reply *MyReply, reducef func(string, []string) string) {
intermediate := []KeyValue{}
// read intermediate key/value pairs
for _,v := range reply.ReduceFileList {
file, err := os.Open(v)
defer file.Close()
if err != nil {
log.Fatalf("cannot open %v", v)
}
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
intermediate = append(intermediate, kv)
}
}
// sort value
sort.Sort(ByKey(intermediate))
oname := "mr-out-"+strconv.Itoa(reply.ReduceNumAllocated)
ofile, _ := os.Create(oname)
i := 0
// reduce
for i < len(intermediate) {
j := i+1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
_ = CallForTask(MsgForFinishReduce, strconv.Itoa(reply.ReduceNumAllocated))
}
如代码所示, worker 读取所有发送过来的中间文件的内容,然后通过一个 Sort 函数完成排序。(我们需要提供相应的方法,才能完成排序):
// for sorting by key.
type ByKey []KeyValue
// for sorting by key.
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
Sort结束后,便是开始 reduce 工作。
步骤六
目标
reduce worker 重复迭代排序后的中间值。reduce worker接下来对中间值经过用户自定义的 Reduce 来处理。得到一个 output 文件。
我们的实现
Sort结束后,迭代中间值,对同一 key 的中间值进行 reduce 统计 value , 因为我们已经 Sort 过了, 所以, 相同 key 的中间值对自然是在一块的。
这样完成 worker 的 reduce 部分, 然后写入到最终文件中。 文件名在官网上也有规定。
上面的代码以达到目的, 对 intermediate 的 for 循环, 迭代中间值,并进行 reduce 。然后写入到输出文件:
// WriteToReduceOutput : write to final file
func WriteToReduceOutput(key, values string, nReduce int) {
filename := "mr-out-"+strconv.Itoa(nReduce)
ofile, err := os.Open(filename)
if err != nil {
fmt.Println("no such file")
ofile, _ = os.Create(filename)
}
fmt.Fprintf(ofile, "%v %v\n", key, values)
}
写入完成后, worker 向 master 发送 MsgForFinishReduce 类型的 Reduce 任务完成的消息。
步骤七
目标
当所有的 Map 和 Reduce 完成后,程序正常退出。
我们的实现
到现在,我们已经基本完成了大部分工作,接下来,我们完善其他要求的细节
worker 一直运行
我们的 worker 不能在执行了一个任务后就退出,而是要完成任务后,接着请求下一个任务。直到 master 因为所有任务完成而退出,worker 才退出:
// main/mrworker.go calls this function.
//
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
for(true) {
reply := CallForTask(MsgForTask,"")
if(reply.TaskType == "") {
break
}
switch(reply.TaskType) {
case "map":
mapInWorker(&reply, mapf)
case "reduce":
reduceInWorker(&reply, reducef)
}
}
}
如上述所示,我们一直发送 MsgForTask 类型的请求,如果返回回来的reply没有内容,我们可以判断 master 已经推出,此时, worker 也可以推出。
master 退出的时机
通过观察 mrmaster.go, 我们知道, 通过监视 master 的 Done 方法,判断是否运行结束。所以,我们需要在所有任务运行结束后,让 Done 返回 true:
// main/mrmaster.go calls Done() periodically to find out
// if the entire job has finished.
//
func (m *Master) Done() bool {
ret := false
// Your code here.
ret = m.ReduceFinished
return ret
}
步骤八
目标
完成 crash 的处理
我们的实现
要完成实验,我们还需要完成对 crash 情况的处理。
本实验在测试的时候,会让 worker 在 map 或 reduce 的时候随机退出, 我们要做的是,worker 退出后,它的任务就被当作未完成, master 需要将这些任务重新分配,保证任务的完成。
这里,就需要用到我之前提到的 timerForWorker 函数了。 按照我们 MyCallHandler 里的设计,我们在每分配一个任务后,即开始一个计时进程, 按照要求,以10秒为界限,监视任务是否被完成:
// TimerForWorker : monitor the worker
func (m *Master)timerForWorker(taskType, identify string) {
ticker := time.NewTicker(10 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
if taskType == "map" {
m.RWLock.Lock()
m.AllFilesName[identify] = UnAllocated
m.RWLock.Unlock()
// 重新让任务加入channel
maptasks <- identify
} else if taskType == "reduce" {
index, _ := strconv.Atoi(identify)
m.RWLock.Lock()
m.ReduceTaskStatus[index] = UnAllocated
m.RWLock.Unlock()
// 重新将任务加入channel
reducetasks <- index
}
return
default:
if taskType == "map" {
m.RWLock.RLock()
if m.AllFilesName[identify] == Finished {
m.RWLock.RUnlock()
return
} else {
m.RWLock.RUnlock()
}
} else if taskType == "reduce" {
index, _ := strconv.Atoi(identify)
m.RWLock.RLock()
if m.ReduceTaskStatus[index] == Finished {
m.RWLock.RUnlock()
return
} else {
m.RWLock.RUnlock()
}
}
}
}
}
通过持续监听任务,如果一旦任务失败,超时,那么则将本任务重新加回到任务队列的 channel 里。供其他的 worker 调用。
到此为止
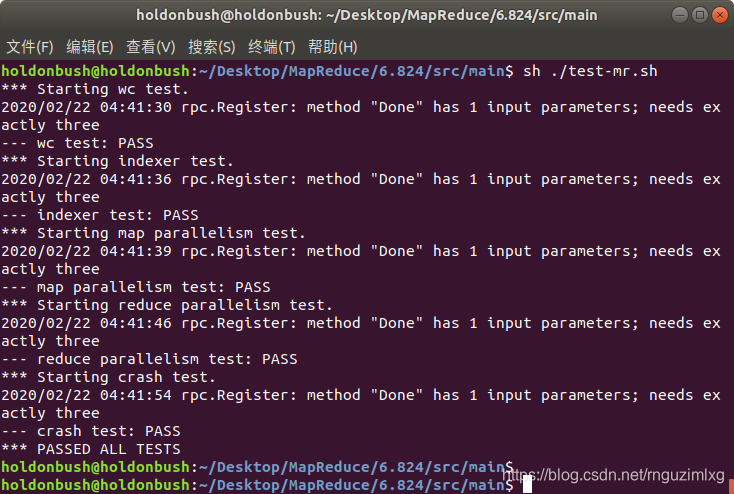
到现在,我们的代码已经基本完成, 可以通过所有的 Tests 。

















 637
637









 到【灌水乐园】发言
到【灌水乐园】发言







