







 本文深入探讨了HBase中BloomFilter的应用与优化,详细解释了其如何通过过滤storefile文件提升get操作性能,以及在不同场景下选择ROW或ROWCOL类型BloomFilter的策略。
本文深入探讨了HBase中BloomFilter的应用与优化,详细解释了其如何通过过滤storefile文件提升get操作性能,以及在不同场景下选择ROW或ROWCOL类型BloomFilter的策略。
简介
不了解bloomfilter的可以参考我以前的文章:
在判断元素是否存在的情形确实很高效。在hbase中的应用也是如此,可以使用bloomfilter在采用get方式获取数据的时候,过滤掉某些storefile文件,进而提升性能,当然会存在构建bloomfilter导致的性能开销。
从HBase 0.96开始,默认情况下启用基于行的布隆过滤器。可以选择禁用它们或更改某些表以使用行+列布隆过滤器,具体取决于数据的特征以及如何将其加载到HBase中。
可以选择为行,或行+列组合来启用Bloom过滤器。如果通常扫描整行,则行+列组合使用bloomfilter是无效的。也即是基于行的布隆过滤器可以对行+列进行Get操作。当每个数据条目的大小至少为几千字节时,Bloom过滤器效果最佳。
当数据存储在几个较大的StoreFiles中时,读取开销将降低,以避免在低级扫描期间额外的磁盘IO找到特定的行。
布隆过滤器需要在删除时重建,因此可能不适合具有大量删除的环境。
常用场景
1、根据key随机读时,在StoreFile级别进行过滤
2、读数据时,会查询到大量不存在的key,也可用于高效判断key是否存在
案例说明
a) ROW
根据KeyValue中的row来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloomfilter为ROW,那么get(r1)时就会过滤sf2,get(r3)就会过滤sf1
b) ROWCOL
根据KeyValue中的row+qualifier来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloomfilter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1
启用Bloom过滤器
在列族上启用Bloom过滤器。您可以使用HColumnDescriptor的setBloomFilterType方法或使用HBase API来完成此操作。有效值是NONE,ROW(默认值),或ROWCOL。
以下示例创建一个表,并在colfam1列族上启用ROWCOL Bloom过滤器。
hbase> create 'test',{NAME => 'cf1', BLOOMFILTER => 'ROWCOL'}
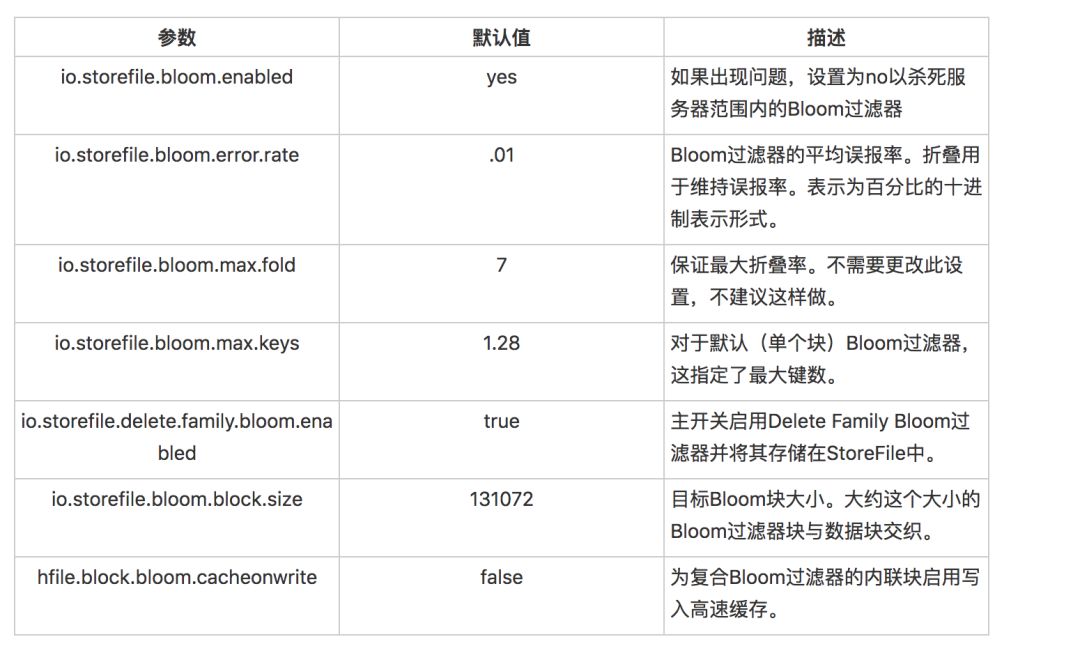
相关配置
推荐阅读:
欢迎与近460好友一起学习大数据,冲刺2019!


















 1098
1098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









