







一,架构介绍
生产中由于历史原因web后端,mysql集群,kafka集群(或者其它消息队列)会存在一下三种结构。
1,数据先入mysql集群,再入kafka
数据入mysql集群是不可更改的,如何再高效的将数据写入kafka呢?
A),在表中存在自增ID的字段,然后根据ID,定期扫描表,然后将数据入kafka。
B),有时间字段的,可以按照时间字段定期扫描入kafka集群。
C),直接解析binlog日志,然后解析后的数据写入kafka。
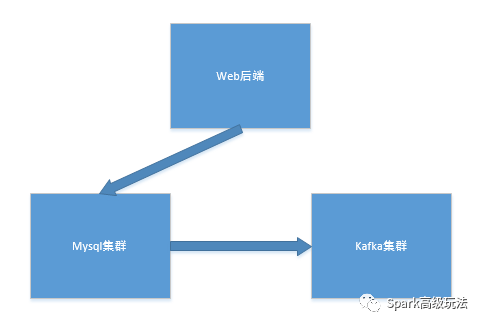
2,web后端同时将数据写入kafka和mysql集群
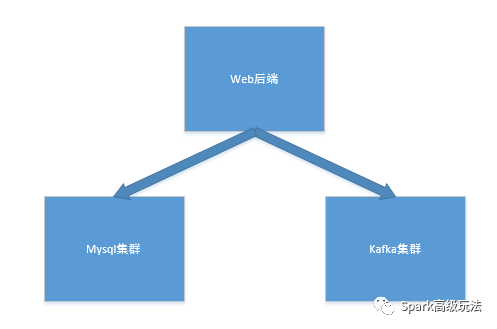
3,web后端将数据先入kafka,再入mysql集群
这个方式,有很多优点,比如可以用kafka解耦,然后将数据按照离线存储和计算,实时计算两个模块构建很好的大数据架构。抗高峰,便于扩展等等。
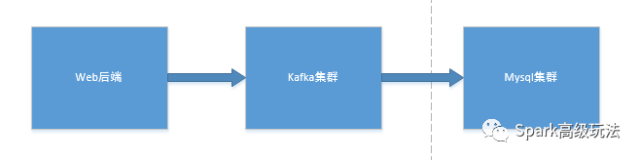
二,实现步骤
1,mysql安装准备
安装mysql估计看这篇文章的人都没什么问题,所以本文不具体讲解了。
A),假如你单机测试请配置好server_id
B),开启binlog,只需配置log-bin
[root@localhost ~]# cat /etc/my.cnf
[mysqld]
server_id=1
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-bin=/var/lib/mysql/mysql-binlog
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
创建测试库和表
create database school character set utf8 collate utf8_general_ci;
create table student(
name varchar(20) not null comment '姓名',
sid int(10) not null primary key comment '学员',
majora varchar(50) not null default '' comment '专业',
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3215
3215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









